;9:; · 背景介紹 動機與目的 ... 協同式 推薦...
TRANSCRIPT

詹翰良 元智大學 資訊工程學系 李祐陞 中央研究院 資訊創新科技中心 王祥安 中央研究院 資訊創新科技中心
2012
DADHIC

背景介紹 動機與目的 相關研究 實驗步驟 未來方向
2012
DADHIC

中央研究院數位典藏資源網 ◦ 中央研究院數位典藏計畫的入口網站 ◦ 整合超過一百個網站與資料庫的內容 ◦ 收集超過一百萬筆的metadata,並持續增加中 ◦ 提供相關內容推薦的機制
2012
DADHIC

依文章類別作推薦 ◦ 文章已依照魚類、貝類等十七個類別主題做分類 ◦ 挑選相同分類的文章推薦給使用者
依內容相關性作推薦 ◦ 依特徵選取重要關鍵字 ◦ 進行文件相似比對
2012
DADHIC

以文章分類、內容性相關的推薦精準度不足 ◦ 有些文章屬於多個類別 ◦ 有些文章不屬於任何類別 ◦ 有些文章與太多內容相關
使用者不易了解推薦內容的相關性 ◦ 使用者須看完整篇文章才能了解是否相關 ◦ 使用者無法了解與本文相關的概念有哪些
2012
DADHIC

提供好的推薦機制 ◦ 改善推薦的精準度,讓系統推薦的內容更貼切使用者的需求 ◦ 讓使用者以圖形化的方式,更直覺地了解網站中相關的內容 ◦ 讓使用者能看到更多相關的內容,增加使用的時間 ◦ 讓使用者有良好的使用經驗,增加未來使用的意願
2012
DADHIC

以概念詞組的方式做搜尋,調整文章的Ranking
將文章內容的關聯性,以較直覺的圖形化方式呈現
2012
DADHIC

內容式推薦 ◦ 使用者個人在網站的停留時間、操作 ◦ 文章的閱覽次、點擊次 ◦ 文章內容相關 例:「梯狀福壽螺」、「福壽螺」
協同式推薦 ◦ 透過行為相似的使用者評分,來推薦使用者感興趣的項目 ◦ 缺點 若自己是第一個評分的使用者,則無從參考(Cold Start) 文章太多,被評分的文件數量有限(Sparsity)
2012
DADHIC

Item Representation ◦ 依照文章內容作解析
個人化 ◦ User Profiles 使用者與系統的互動 精準度隨著時間提升 數典網站沒辦法留住使用者這麼久
◦ Learning Model 透過使用者回饋滿意或不滿意 缺點:造成使用者困擾
2012
DADHIC

簡介 ◦ 最早由Apriori所提出 ◦ 從大型資料庫找熱門商品之間的關係 例:尿布與啤酒
應用 ◦ 以一篇文章當作一筆交易 ◦ 以關鍵字當作商品 ◦ 建立關鍵字彼此之間的關係
2012
DADHIC

演算法 ◦ FP-Growth vs Apriori 優點 建立樹狀結構與檢索效率較好 不會產生過多組合
缺點 占用較多記憶體
2012
DADHIC

知識(Knowledge)是加值過的資料(Data)與資訊(Information),地圖是知識內容的視覺化與圖表化呈現模式。 換言之,知識地圖(Knowledge Map)即是有價值資訊的圖表化呈現結果。
2012
DADHIC

邊 ◦ 由Association Rule所建立關鍵字彼此的關係
點 ◦ 各個關鍵字名稱
將關鍵字彼此的關係繪製成圖形
2012
DADHIC

詞組 ◦ 足以代表一個概念,由多個關鍵字所組成
如何透過 Knowledge Map 建立詞組?
2012
DADHIC
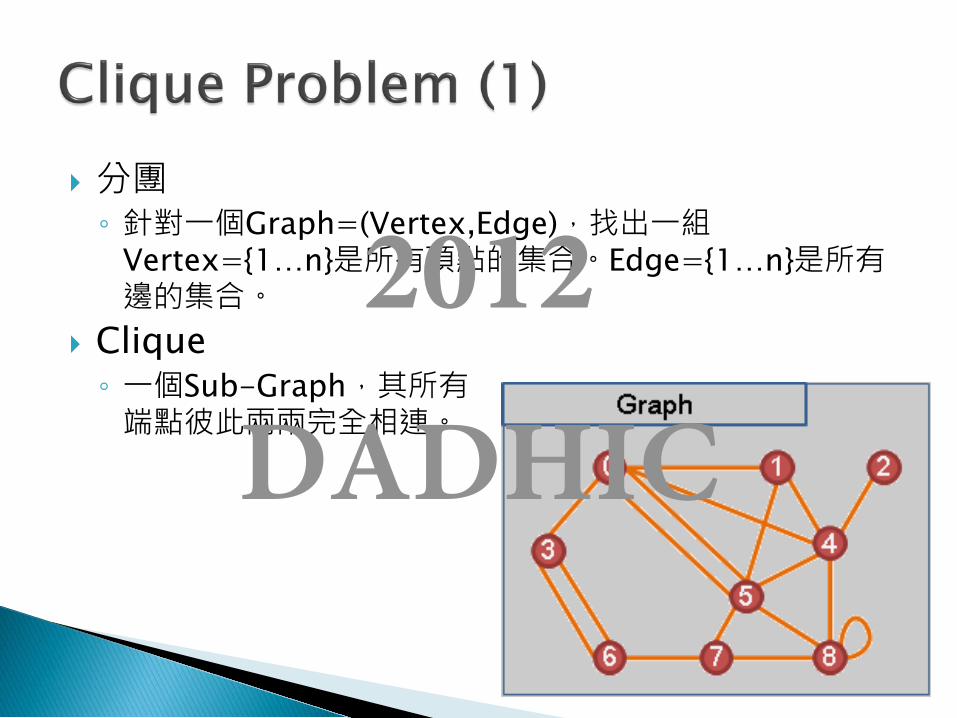
分團 ◦ 針對一個Graph=(Vertex,Edge),找出一組
Vertex={1…n}是所有頂點的集合。Edge={1…n}是所有邊的集合。
Clique ◦ 一個Sub-Graph,其所有 端點彼此兩兩完全相連。
2012
DADHIC

Maximal Clique ◦ 不被其他Clique所包含的Clique
Maximum Clique ◦ 擁有最多頂點數的Clique 2012
DADHIC

透過詞組的建立,可以把原始的複雜圖化為多個小群組,而這每個群組就是我們的詞組。 2012
DADHIC

建立關鍵字資訊
解析文章關鍵字
建立關聯規則
平行化 建立關鍵詞組
以詞組做搜尋
2012
DADHIC

聯合目錄字典檔 ◦ 由人力挑選、建置而成 ◦ 約十萬字
數典資料 ◦ 符合Dublin Core格式 ◦ 針對Description、Coverage、Subject、Title 進行關聯法則 ◦ 若關鍵字出現在這些元素中, 代表這篇文章與這個關鍵字有相關
2012
DADHIC

對每個關鍵字建立相關資訊 以「數位典藏」為例 ◦ TF(詞頻):
「數位典藏」出現的次數除以該文件的總詞語數 ◦ DF(文件頻率):
有多少份文件出現過「數位典藏」一詞, ◦ 跨分類頻率:「數位典藏」出現在幾個主題之中
2012
DADHIC

2012
DADHIC

擷取每篇文章的關鍵字 依照關鍵字的DF降冪排列 2012
DADHIC

用FP-Growth找出關聯項目(Frequent-Pattern) ◦ Confidence通過一定門檻的項目 ◦ 例:警察、罰鍰
平行化 ◦ 事先取得所有關鍵字的DF ◦ 對關鍵字排序 ◦ 將文件分散給多部機器
2012
DADHIC

平行化工具 ◦ Gearman vs Hadoop 設定簡單 撰寫結構較簡單 跨平台,包含Java、C、PHP、Python
2012
DADHIC

依照關聯規則所找到的關聯項目 依照Confidence的高低 建立不同Confidence的關鍵詞組
把關鍵字的關係建成Knowledge Map
利用分團問題,找出Maximum Clique。 每個Clique內的元素就是關鍵詞組
2012
DADHIC

詞組示意圖
2012
DADHIC

查詢 ◦ 以詞組作為Query的單位 Confidence層級越高,則Score越高 詞組元素越多,則Score越高
◦ 最終的Ranking受到Clique大小以及Confidence層級影響
2012
DADHIC

對於沒有特定主題或是太多主題的文章,效果較差
可透過Knowledge Map看出文章大意
2012
DADHIC

以視覺化呈現 vs 條列式呈現 ◦ 視覺化呈現的優點 將文章概念濃縮成圖形化方式,快速理解 閱讀文章前即可了解文章大意
2012
DADHIC

2012
DADHIC

2012
DADHIC
改善關鍵字挑選 ◦ 字典檔的維護 ◦ 長辭優先篩選 例如:中國、現代史→中國現代史
關聯規則加強 ◦ 加入語句的概念來挑選每個主題的關鍵字 ◦ 詞間距離混合計算
2012
DADHIC

在少許的情況下,會形成類似蜘蛛網或是太陽發散的圖形,應避免這種圖形出現
使用者行為分析(User Log) ◦ 使用者對於現行推薦結果的滿意度 問卷方式 群眾外包(crowdsourcing) ◦ 關聯式推薦是否產生更多點擊、增加使用者停留時間
2012
DADHIC

感謝您的聆聽 2012
DADHIC