2015 nov 27_thug_paytm_rt_ingest_brief_final
TRANSCRIPT

The New <Data> Deal:RealTime IngestA fast pipeline befitting hundreds of millions of customers.

Agenda
• What Paytm Labs does• Our Data Platform• Moving to Realtime data ingestion
2

What do we do at Paytm Toronto?
• Create Data Platforms and Data Products to be used by Paytm in the following areas:• Create a comprehensive data
platform for archive, processing, and data-based decisions
• Fraud Detection and Prevention• Analytical Scoring, Reporting, and
other Data Science challenges• Building an advertising technology
platform to generate revenue and increase customer engagement
• Blockchain(!) Stay tuned…3

The Platform
4

The Data Platform at Paytm:
• Maquette• Continues to be mainstay of RT Fraud Prevention• Provides a Rule DSL as well as a flexible data model
• Fabrica• Modularized feature creation framework (yes, a real framework)• In Spark and SparkSQL for now• Will move to Spark Streaming very soon
• Chilika• Hadoop and related technologies• Processing and Storage muscle for most data platform tasks• Includes data export and BI tooling like Atscale, Tableau, and ES
5

Fabrica
• Modular framework for execution of feature creation, scoring, and export jobs• Parallel job execution and optimized by caching targeted
datasets• Handles complex transformations and can automate new
feature creation• Easily consumes Machine Learning libraries, especially Spark
MLLib• Starts as a Spark batch job and moves to a Spark Streaming
application• Written in Spark Scala• A DSL coming later
6

Fabrica7

Maquette:
• Realtime rule engine for fraud detection• All of our marketplace transactions are evaluated in realtime
with concurrent evaluation on hundreds of fraud rules• Custom Scala/Akka application with a Cassandra datastore• Can be used with our datastores, such as Titan,
GraphIntelligence, HBase, etc• Interface for Rule and Threshold tuning• Handles millions of txns per day at an average response time
of 20ms
8

Chilika (aka Datalake, aka Hadoop Cluster):Moving to a Realtime Data Pipeline
9

What we have been using…
10

A “traditional” batch ingest process to Hadoop
• A 24 hour cycle batch-driven process • A reservoir of detailed data for the past 6 months for core
tables, 2 years for some higher level data, and a few months for the new data sets• Hadoop (HDP) data processing tools primarily, specifically Hive• Hive (SQL) transformations require so much additional logic
for reprocessing, alerting, etc that they have python programs call them• For event-streams (aka Real-Time), we load into Kafka. We pull
off this event data into a aggregated avro file for archive in HDFS.
11

When MySQL fails…we fail
12
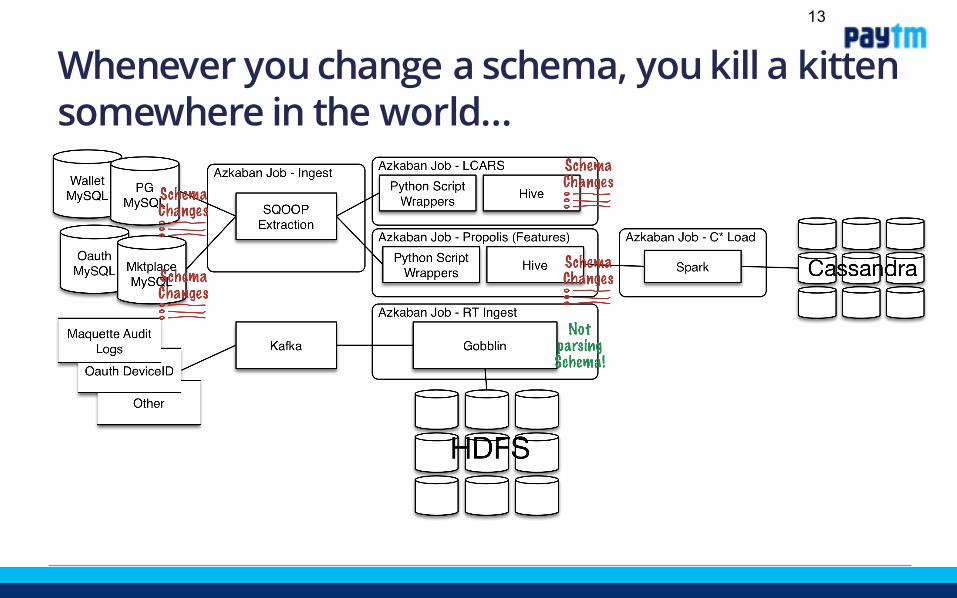
Whenever you change a schema, you kill a kitten somewhere in the world…
13

Lots of room for improvement…• A 24 hour cycle batch-driven process means stale data for
a lot of use cases• The most important and most fragile pipeline is MySQL• The MySQL instances rely on a chain of Master-Replica-
Replica-Replica to get to Hadoop. This chain fails a lot• The MySQL chain has a fixed schema from RDBMS to
Hive. • Assumptions that this schema is fixed are carried forward
throughout our own processing pipeline. • Changes to schema result in a cascading failure• Hive does not have a resilient and programmatic way of
handling schema change• Others have attempted to write custom Java Hive SerDes to
correct data but this puts too much logic in the wrong spot• By using Hive for transformations that are complicated,
we have forced unnecessary temporary tables, created hacky nanny scripts, and made it nearly impossible to compose complicated transformations
14

A word on impatience…• The amount of signals and actions that a mobile
phone user will generate is much higher than a web user by virtue of their mobility
• Reducing the MTTF (Mean Time To Feature) from hours to minutes opens up an entirely new set of interactions with users:• More advertising inventory with hyperlocal (ie walk into a
store) targeting, ie more revenue potential• Better fraud detection and risk assessment• More opportunities to construct a meaningful relationship
with the customer through helpful engagement:• bill splitting• localized shopping reminders – “while you are here...”• Experience planning (you were looking for a restaurant, so we
suggest something you would like, plan your transit/train, and order via FoodPanda)
15

Chilika Realtime Edition16

Using Confluent.io
17

Our realtime approach: DFAI (Direct-From-App-Ingest)
• Requires our primary applications to implement an SDK that we provide • The SDK is a wrap of the Confluent.io SDKs with our
schema registered• Schema management is done automatically with the
confluent.io schema repository using Apache Avro• Avro Schema is flexible with Avro, unlike @#$^@!!! SQL
Schema• Avro Schema is open source and would still be
manageable even if we moved away from using Confluence. Our data is safe for the long term.
18

DFAI = Direct-From-App-Ingest• Market-order• order/invoice: sales_order_invoice table
• create• updateAddress
• order/order : sales_order table• create• update
• order/payment: sales_order_payment table• create• insertUpdateExisting• update
• order/item:sales_order_item table• create• update
• order/address: sales_order_address table• create• updateAddress
• order/return_fulfillment: sales_order_return table
• create• update
• order/refund: sales_order_refund table• create• update
Order/invoice schema example:
{ "namespace" : "com.paytm", "name": "order_invoice_value", "type": "record", "fields": [ { "name": "tax_amount", "type": unitSchemas.nullLong}, { "name": "surchange_amount", "type": unitSchemas.nullLong.name}, { "name": "subtotal", "type":unitSchemas.nullLong.name}, { "name": "subtotal_incl_tax", "type":unitSchemas.nullLong.name}, { "name": "fulfillment_id", "type":unitSchemas.nullLong.name}, { "name": "created_at", "type": unitSchemas.str} ]}
19

Event Sourcing & Stream Processing
• Read this: http://www.confluent.io/blog/making-sense-of-stream-processing/• Basic concept: treat the stream as an immutable set of
events and then aggregate views specific to use cases• We will use Fabrica to stream and aggregate data in
realtime eventually• For batch work, we post-process the create / update
events to yield an aggregate state view. In other words, the last state
20

Say no to batch ingest: talk to your Data Architect about DFAI today.
21

Thank you!Adam [email protected]