(19) tzz z t - welcome to city research online - city ...openaccess.city.ac.uk/8146/1/patent...
TRANSCRIPT

Note: Within nine months of the publication of the mention of the grant of the European patent in the European PatentBulletin, any person may give notice to the European Patent Office of opposition to that patent, in accordance with theImplementing Regulations. Notice of opposition shall not be deemed to have been filed until the opposition fee has beenpaid. (Art. 99(1) European Patent Convention).
Printed by Jouve, 75001 PARIS (FR)
(19)E
P2
470
994
B1
TEPZZ 47Z994B_T(11) EP 2 470 994 B1
(12) EUROPEAN PATENT SPECIFICATION
(45) Date of publication and mention of the grant of the patent: 09.10.2013 Bulletin 2013/41
(21) Application number: 10763407.3
(22) Date of filing: 13.08.2010
(51) Int Cl.:G06F 11/20 (2006.01)
(86) International application number: PCT/GB2010/051347
(87) International publication number: WO 2011/023979 (03.03.2011 Gazette 2011/09)
(54) IMPROVEMENTS RELATING TO DATABASE REPLICATION
VERBESSERUNGEN IM ZUSAMMENHANG MIT DATENBANKREPLIKATIONEN
AMÉLIORATIONS APPORTÉES À LA RÉPLICATION D’UNE BASE DE DONNÉES
(84) Designated Contracting States: AL AT BE BG CH CY CZ DE DK EE ES FI FR GB GR HR HU IE IS IT LI LT LU LV MC MK MT NL NO PL PT RO SE SI SK SM TR
(30) Priority: 25.08.2009 GB 0914815
(43) Date of publication of application: 04.07.2012 Bulletin 2012/27
(73) Proprietor: THE CITY UNIVERSITYLondon EC1V 0HB (GB)
(72) Inventors: • POPOV, Peter Tonev
London EC1V 0HB (GB)• STANKOVIC, Vladimir
LondonEC1V 0HB (GB)
(74) Representative: Lawrence, Richard Anthony et alKeltie LLP Fleet Place House 2 Fleet PlaceLondon EC4M 7ET (GB)
(56) References cited: EP-A2- 1 349 085
• ELNIKETY S ET AL: "Database Replication Using Generalized Snapshot Isolation", RELIABLE DISTRIBUTED SYSTEMS, 2005. SRDS 2005. 24TH IEEE SYMPOSIUM ON ORLANDO, FL, USA 26-28 OCT. 2005, PISCATAWAY, NJ, USA,IEEE, 26 October 2005 (2005-10-26), pages 73-84, XP010854120, ISBN: 978-0-7695-2463-4

EP 2 470 994 B1
2
5
10
15
20
25
30
35
40
45
50
55
Description
FIELD OF INVENTION
[0001] The present invention concerns improvementsrelating to database replication. More specifically, as-pects of the present invention relate to a fault-tolerantnode and a method for avoiding non-deterministic be-haviour in the management of synchronous databasesystems.
DISCUSSION OF PRIOR ART
[0002] Current database replication solutions, in bothacademia and industry, are primarily based on the crashfailure assumption, whereby it is assumed that the un-derlying building blocks, i.e. Relational Database Man-agement Systems (RDBMSs), fail in a detectable way,leaving a copy of a correct database state for use in re-covery. The conventional approach in database systemsis to use a plurality of non-diverse replicas - RDBMSsfrom the same vendor - for mainly availability and scal-ability improvement. This is regarded as a suitable ap-proach to addressing failure under the crash failure as-sumption, as use of a sufficient number of replicas toler-ates crash failures and manages increased load fromclient applications for improved performance. The validityof this assumption has, however, been refuted in the re-cent work by Gashi et al. [Gashi, Popov et al. 2007] andsubsequently in [Vandiver 2008]. Many of the softwarefaults examined in these two studies caused systematic,non-crash failures, a category ignored by most standardimplementations of fault-tolerant database replication so-lutions. The non-crash failures of RDBMS products arelikely to be causing some of the following anomalies: re-turning incorrect results to the client application, incor-rectly modifying data items in the database, arbitrarilyhalting a transaction or failing to execute an operationand raise an exception. These failure modes are typicallyassociated with synchronous systems, that is, systemswhich either deliver a result in a predefined amount oftime or are considered to have failed (timeout occurs).[0003] The work of Gashi et al [Gashi, Popov et al.2007] was based on two studies of samples of bug reportsfor four popular off-the-shelf SQL RDBMS products: Or-acle, Microsoft SQL, PostgreSQL and Interbase; plus lat-er releases of two of them: PostgreSQL and Firebird (anopen source descendant of the InterBase database serv-er). Each bug report contains a description of the bugand a bug script for reproducing the failure (the erroneousbehaviour that the reporter of the bug observed). Theresults of the studies indicate that the bugs causing fail-ures in more than two diverse RDBMSs are rare - only afew bugs affected two RDBMSs and none affected morethan two. Thus, a very high detection rate (ranging from94% to 100%) is achievable when using just a simpleconfiguration with two diverse servers. Another very im-portant finding was that crash failure assumption is un-
justified. The authors showed that the majority of the col-lected bugs belonged to the incorrect results category,causing incorrect outputs without crashing the RDBMSproducts (approximately 66% of the bugs caused incor-rect results failures, while roughly just 18% caused crashfailures).[0004] Similarly to the work by Gashi et al., the workin [Vandiver 2008] experimented with the faults reportedfor three well-known RDBMSs: DB2, Oracle and MySQL.The results show that for all three products over 50% ofthe bugs cause non-crash failures; resulting, for example,in incorrect results returned to a client or incorrectly mod-ified database items.[0005] The unfounded assumption that only crash-fail-ures are observed in RDBMSs has lead to developmentof a multitude of solutions which are based on asymmetricprocessing of database transactions (see Appendix A).Inherent to asymmetric processing is the inability to copewith non-crash failures; e.g. if a replica is faulty, the clientconnected to this replica can obtain a wrong result orincorrect values could be propagated into the state of thecorrect replicas (see Figure 1).[0006] Figure 1 illustrates the impossibility of incorrectresult detection by a middleware-based database repli-cation protocol using asymmetric transaction execution(the steps shown with dashed lines are not part of theprotocol). The figure shows the execution of a read op-eration (read(x)) in a replicated database system con-sisting of three replicas Rx, Ry and Rz. The executionsteps are as follows: the client sends 1 the read operationto the middleware, M; the middleware forwards 2 the re-quest to only one replica, Rx; Rx executes the requestand sends 3 the result to the middleware and middlewarenotifies 4 the client of the result. If Rx is faulty, an incorrectresponse will be forwarded to the client with no possibilityfor detection, since the execution of the read operationis executed on only one replica. On contrary, if all replicaswere sent 2, 2a, 2b the read request it would be possiblefor middleware to adjudicate the responses sent 3, 3a,3b by all replicas and detect the incorrect Rx response.[0007] The family of multicast replication protocols isgenerally used for implementing asymmetric transactionprocessing. These protocols use a GCS (Group Com-munications System), which makes it possible for anyreplica to send a message to all other replicas (includingitself) with the guarantee that the message will be deliv-ered if no failures occur. Furthermore, GCS is capableof guaranteeing totally ordered messages: if two replicasreceive messages m and m’, they both receive the mes-sages in the same order. In fact, a GCS may offer a rangeof different guarantees and total ordering is one of themore expensive options. The known DB replication so-lutions rely on GCS being configured to offer total order-ing. The principal steps behind a multicast replication pro-tocol are as follows: a transaction Ti is submitted to one,local replica (all other replicas are called remote for Ti);the local replica executes completely the transaction andextracts the results of all the modifying operations in a
1 2

EP 2 470 994 B1
3
5
10
15
20
25
30
35
40
45
50
55
writeset; in the end of transaction Ti’s writeset is sent toall remote replicas in total order using the underlyingGCS; upon receiving the Ti’s writeset every replica in-stalls the writeset in the same total order imposed by theGCS. The installation of the writesets in the same totalorder is necessary to avoid data inconsistencies due tonon-determinism on the replicas. Otherwise, if the totalorder was not respected it would be possible for two rep-licas to install overlapping writesets in a different order,which would result in an inconsistent state of the repli-cated system. Some examples of multicast-based repli-cation protocols used with RDBMSs providing snapshotisolation (see Appendix A) are described in [Lin, Kemmeet al. 2005] and [Kemme and Wu 2005]. [Elnikety, S., W.Zwaenepoel, et al. 2005] provides discussion of fault-tolerant database replication using snapshot isolation ap-proaches - a master database is replicated to a pluralityof replica databases, such that any past snapshot canbe used for snapshot isolation, wherein if update trans-actions update the same item, then the transaction thatcommits first succeeds in updating the item and the othertransaction is aborted.[0008] EP 1349085 teaches a database replication ar-rangement in which update collisions are resolved byswitching from a synchronous replication mode to anasynchronous replication mode. EP 1349085 does notteach the use of snapshot isolation in the context of con-current transactions.[0009] Two recent database replication protocols arebuilt on a more general failure model than crash failures:HRDB (Heterogeneous Replicated DataBase) [Vandiver2008] and Byzantium [Preguiça, Rodrigues et al. 2008]approaches. HRDB’s SES (Snapshot Epoch Scheduling)protocol and Byzantium are of particular interest becausethey assume, that the underlying replicas guaranteesnapshot isolation. Both HRDB and Byzantium assumethat an arbitrary failure can occur, i.e. a Byzantine failuremodel (described for the first time in [Lamport, Shostaket al. 1982]) is assumed. This failure model is the mostgeneral one, where beside crash failures, for example,incorrect results of read and write operations are alsoallowed; even malicious behaviour by the replicas suchas sending conflicting messages to the other replicas areallowed by the Byzantine failure model.[0010] Both HRDB and Byzantium are primary/ sec-ondary, middleware- based replication protocols, whichtolerate non- crash failures by voting on the results com-ing from different replicas. Figure 2 illustrates the genericprimary/ secondary database replication approach. TheClient (C) first sends 21 the operations {op1, , ..., opk,... , opn} of the transaction Ti to the Primary replica (P)for execution, and only once the Primary executes theoperations it forwards 22a, 22b them to the Secondaries{S1, ..., Sm} . Therefore, in both protocols, write opera-tions are firstly executed on one (primary) replica andonly then sent to the secondary replicas in order to guar-antee replica consistency- in this way the conflicting op-erations are executed in the same order (the one im-
posed by the primary) on all replicas and thus non- de-terminism between conflicting modifying transactions areavoided. However, in this way no parallelism in the exe-cution of the same write operations between the primaryon the one hand and secondary replicas on the otherhand is allowed; as a result the total duration of a trans-action may be significantly prolonged (as shown in Figure3) even in the arguably more common case when nowrite- write conflicts (see appendix A) occur between theconcurrently executing transactions.[0011] Although both HRDB and Byzantium use a pri-mary/secondary approach, there is a difference betweenthe two as to when the primary forwards the (write) op-erations for execution to the secondaries. In HRDB everywrite operation is sent to the secondaries as soon as itis completed on the primary (possibly after its concurren-cy control mechanism resolves the conflicts betweenconcurrent write operations), see Figure 3. The read op-erations in HRDB, on the other hand, are executed inparallel on primary and secondary replicas.[0012] More specifically, Figure 3 shows a timing dia-gram of the execution of a write operation in HRDBscheme consisting of the primary (P) and two secondaryreplicas (S1 and S2) . The meaning of the callouts is asfollows: the middleware (M) sends 31 the write operation,w (x), to the primary replica for execution; once the pri-mary has executed the write, it notifies 32 the middlewareby sending it the result of w (x) ; middleware forwards33a, 33b the write operation to the secondary replicasfor execution. Performance overhead ensues becausethe write operation is not executed in parallel betweenthe primary and the secondary replicas. As a result, theoperation duration as perceived by the middleware is pro-longed (Tw(x)
Sequential), as opposed to it being shorter dueto parallel execution on all replicas (Tw(x)
Parallel) . Theexecution order in the primary/ secondary scheme caus-es transactions to retain the write locks for longer andthis leads to an increased likelihood of a write- write con-flict with the other concurrent transactions. Even thoughHRDB (as well as Byzantium) uses database systemswhich offer snapshot isolation, the low level implemen-tation of the concurrency control mechanisms in thesedatabase systems still relies on the use of locking mech-anisms on shared resources by multiple concurrent us-ers.[0013] The situation with Byzantium is different in anumber of respects. First, all operations, both reads andwrites, of a transaction are executed on the primary rep-lica (the work in [Preguiça, N., R. Rodrigues, et al. 2008]uses the term "coordinator replica" for the primary) andthe respective responses collected for future use. Also,different from HRDB, Byzantium assumes that differenttransactions are assigned to different coordinator repli-cas. Subsequently, the commit phase is initiated and onlythen all operations and the respective results are forward-ed by the primary to the secondaries for validation: thesecondaries then execute all operations and comparethem with the responses of the primary. In this way no
3 4

EP 2 470 994 B1
4
5
10
15
20
25
30
35
40
45
50
55
parallelism between the operations’ execution on theprimary and the secondaries exist, which makes thisscheme inferior in terms of response time in comparisonwith HRDB.[0014] More specifically, Figure 4 shows the timing di-agram of executing transaction Ti, consisting of three op-erations: w (y), r (x) and r (z), on three Byzantium replicas(P, S1 and S2) . The transaction duration is prolongedbecause all the operations are first executed on the pri-mary replica and only then forwarded to the secondaries.Hence, instead of the transaction execution being paral-lelised on all replicas and its duration dictated by the slow-est one (A Ti (MAX (Ti
P, TiS1, Ti
S2) ), in this case second-ary replica S2 is the slowest), the duration is the sum ofthe primary’s and the slower secondary processing(ΔTi
Sequential) .[0015] The HRDB approach does not compare the re-sponses from the read operations; albeit this possibilityis discussed in [Vandiver 2008]. The Byzantium protocol,on the other hand, includes the validation of the resultscoming from all types of operations.[0016] Compared to conventional database replicationapproaches, the HRDB and Byzantium approaches arecomplex and slow. It is, thus, desirable to develop anapproach for processing of database transactions whichis not limited to the crash failure assumption but whichallows more economical and efficient operation than theHRDB and Byzantium approaches.
SUMMARY OF THE INVENTION
[0017] Accordingly, the invention provides a fault- tol-erant node for synchronous heterogenous database rep-lication whereby the fault- tolerant node is adapted tocarry out a series of database transactions generated bya processor executing a computer program at the fault-tolerant node, wherein the fault- tolerant node comprisesat least two relational database management systems,the systems being instances of different relational data-base management system products which provide snap-shot isolation between concurrent transactions and eachsystem comprising a database and a database manage-ment component, wherein for each database transaction,operation instructions are provided concurrently to eachof the systems to carry out operations on their respectivedatabases and to provide respective responses; whereinthe responses generated by the systems either comprisean operation result or an exception, and where only oneof the systems is configured with a NOWAIT exceptionfunction enabled which returns an exception when it isdetected that two or more concurrent transactions areattempting to modify the same data item and the othersystems are configured with the NOWAIT exception func-tion disabled, whereby the fault- tolerant node is adaptedto detect that two or more concurrent transactions areattempting to modify the same data item and to block oneor more of the transactions to ensure that all systemsapply the same order of modification of the data item by
the concurrent transactions.[0018] With such an approach, the consequences ofnon-deterministic behaviour of the systems are avoided.Such a node is capable of tolerating crash failures andincorrect results by the replicas. This also allows for asolution which is faster than prior art protocols such asHRDB and Byzantium.[0019] A set of operation instructions may include abegin instruction, a commit instruction and an abort in-struction for control of execution of a transaction. Advan-tageously, only one transaction can execute a begin in-struction or a commit instruction at a time for all the sys-tems. When an exception is received as an operationresult from one of the systems, the fault-tolerant nodeprovides an abort instruction for that transaction for allthe systems. In one preferred arrangement, execution ofa begin operation for a transaction comprises setting avariable indicating that the transaction is not, or no longer,aborted, and by acquiring control of commit and beginoperations so that no other begin or commit operationcan take place until the begin operation is completed. Inone arrangement, execution of a commit operation for atransaction comprises confirming that the transactionhas not been marked to be aborted, determining that theoperation results from the systems allow a transactionresults to be provided, determining that the operation re-sults are consistent, and by acquiring control of commitand begin operations so that no other begin or commitoperation can take place until the commit operation iscompleted.[0020] The set of operations comprises a read opera-tion and a write operation, and in executing a write op-eration the node extracts a write set on which operationsare performed before the transaction is committed. Whenall systems have failed to provide a result to a read op-eration or a write operation within a predetermined time,fault-tolerant node raises an exception.[0021] In one preferred arrangement, the fault-tolerantnode comprises a transaction manager to control the ex-ecution of the operations for one transaction in each ofthe systems and a replica manager for each of the sys-tems used to execute a transaction to provide operationsto its associated system, wherein for each transaction,the transaction manager provides operations required forexecution of the transaction into a queue for each systemmanaged by the replica manager for that system, whereinthe operations are provided to each system from thequeue by the replica manager for that system.[0022] Preferably, the fault- tolerant node comprises acomparator function to compare operation results re-ceived from the systems to enable the fault- tolerant nodeto determine whether the transaction has completed suc-cessfully. The fault- tolerant node may then abort thetransaction if the comparator function indicates a mis-match between operation results received from differentsystems. This arrangement contributes to the achieveddependability of the node, as it enables the recognitionof many cases of a failure.
5 6

EP 2 470 994 B1
5
5
10
15
20
25
30
35
40
45
50
55
[0023] In one preferred arrangement (an optimistic re-gime of operation), the fault-tolerant node returns the firstoperation result received from any of the systems to thecomputer program, and provides a further message tothe computer program if the transaction aborts or if theoperation results received from all the systems are notconsistent (e.g. typically identical, or considered to beidentical when the internal representation of data in thedifferent systems introduces small differences even forthe same data). Alternatively, in a pessimistic regime ofoperation, the fault-tolerant node returns an operationresult to the computer program only when the operationresults from all the systems have been received and eval-uated by the fault-tolerant node.[0024] In the fault-tolerant node described above, thedifferent relational database management system prod-ucts may comprise two or more systems that implementsnapshot isolation between concurrent transactions,such as Oracle, Microsoft SQL 2005 or later, Post-greSQL, Interbase and Firebird.[0025] In a further aspect, the invention provides a da-tabase server comprising a fault-tolerant node as set outabove. Such a database server can be provided as partof any computational system in which it is necessary ordesirable for one or more databases to achieve the per-formance resulting from use of embodiments of the in-vention.[0026] In a further aspect, the invention provides amethod for performing a synchronous heterogenous da-tabase replication, for a series of database transactionsprovided by a processor executing a computer program,at a fault-tolerant node comprising at least two relationaldatabase management systems, the systems being in-stances of different relational database managementsystem products which provide snapshot isolation witheach system comprising a database and a databasemanagement component, the method comprising: re-ceiving a database transaction at the fault-tolerant node;providing operation instructions for the database trans-action concurrently to each of the systems to carry outoperations on their respective databases and to providerespective responses; the systems each generating aresponse to an operation instruction which comprises anoperation result or an exception, wherein only one of thesystems is configured with a NOWAIT exception functionenabled such that that system returns an exception whenit is detected that two or more concurrent transactionsare attempting to modify the same data item and the othersystems are configured with the NOWAIT exception func-tion disabled; whereby the fault-tolerant node detectsthat two or more concurrent transactions are attemptingto modify the same data item and allows the transactionthat accesses the data item first on the system with NOW-AIT enabled to proceed on all the systems, and preventsexecution of all the other transactions attempting to mod-ify the same data item on all the systems, thereby achiev-ing that all systems apply the same order of modificationof the data item by the concurrent transactions.
[0027] In embodiments, there is provided a fault-toler-ant node for avoiding non-deterministic behaviour in datamanagement whereby a processor executes a computerprogram to generate a series of database transactionsto be carried out at the fault-tolerant node, the fault-tol-erant node comprising at least two relational databasemanagement systems, the systems being instances ofdifferent relational database management system prod-ucts and each comprising a database and a databasemanagement component, wherein for each databasetransaction, operation instructions are provided concur-rently to each of the systems to carry out operations ontheir respective databases and to provide operation re-sults; wherein the fault-tolerant node compares operationresults generated by the systems to validate the resultof the database transaction.
BRIEF DESCRIPTION OF THE FIGURES
[0028] Embodiments of the invention are described be-low, by way of example, with reference to the accompa-nying Figures, of which:
Figure 1 illustrates a generic middleware-based da-tabase replication protocol using asymmetric trans-action execution and demonstrates the impossibilityof incorrect result detection in such systems;
Figure 2 illustrates a generic primary/secondary ap-proach to database replication;
Figure 3 shows a timing diagram of the execution ofa write operation in the prior art HRDB scheme;
Figure 4 shows a timing diagram of executing a trans-action with one write and two read operations onthree replicas in a prior art Byzantium scheme;
Figure 5 shows an embodiment of a fault-tolerantnode (FT-node) as a UML Component diagram;
Figure 6 illustrates a transaction context for the FT-node of Figure 5 as a UML Class diagram;
Figure 7 illustrates the establishment and destruc-tion of a connection associated with a transaction inthe FT-node of Figure 5;
Figure 8 illustrates the interaction related to theprocessing of an operation by the FT-node of Figure5;
Figure 9 shows the interaction between a RepMan-ager object and respective RDBMSs in the FT-nodeof Figure 5;
Figure 10 shows a UML sequence diagram of com-mitting a transaction in the FT-node of Figure 5;
7 8

EP 2 470 994 B1
6
5
10
15
20
25
30
35
40
45
50
55
Figure 11 shows interaction related to the compari-son of responses received from RDBMSs in the FT-node of Figure 5;
Figure 12 shows a procedure of exception handlingby middleware in the FT-node of Figure 5;
Figure 13 shows pseudo code illustrating the execu-tion of the DivRep protocol on a TraManager as usedin the FT-node of Figure 5;
Figure 14 shows pseudo code illustrating the execu-tion of the DivRep protocol on a RepManager asused in the FT-node of Figure 5;
Figure 15 shows a timing diagram of the executionof a transaction using the DivRep protocol as shownin Figure 13;
Figure 16 shows a timing diagram of a conventionalROWAA scheme for snapshot isolation replicationbased on reliable multicast;
Figure 17 illustrates generally distributed transac-tions which comprise execution of one or more op-erations that, individually or as a group, updateand/or read data on two or more distinct nodes of areplicated database;
Figure 18 shows a timing diagram showing generallythe use of Strict 2-Phase Locking concurrency con-trol and first-updater-wins and first-committer-winsrules for enforcing Snapshot Isolation;
Figure 19 shows generally an example of a concur-rency control mechanism, based on Strict 2-PhaseLocking, enforcing Snapshot Isolation on a central-ised, non-replicated database;
Figure 20 shows generally an example of differenttransaction serialisation decisions made by the con-currency control mechanisms, based on Strict 2-Phase Locking, of two RDBMSs in a replicated da-tabase;
Figure 21 is a schematic block diagram which showsgenerally the interaction between clients and repli-cated DBs;
Figure 22 shows generally the competition betweentwo concurrent transactions competing for a dataitem while executing in a replicated database systemwith two replicas; and
Figure 23 shows a high-level schematic representa-tion of a Group Communication Scheme (GCS) usedfor consistent database replication in a general rep-lication scheme with multiple replicas.
DETAILED DESCRIPTION OF EMBODIMENTS
[0029] An embodiment of an approach to databasereplication will now be described, for which diverse (i.e.different by design, developed by different software ven-dors) relational database management systems (RD-BMSs) are used which offer snapshot isolation betweenconcurrent transactions. This is a departure from the priorart, where non-diverse databases have always been con-sidered to be adequate for database replication, in orderto cope with the software failures and guarantee consist-ency of the data on all replicas. Database replication as-sumed in the present embodiment is of "share nothing"type, where each RDBMS interacts with its own, full copyof the database. This is in contrast to some widespreadcommercial solutions such as Real Application Cluster(RAC) from Oracle (http://www.oracle.com/technology/products/database/clustering/index.html) which uses"share all" approach, where one copy of the database isshared by a cluster of RDBMSs. In this embodiment da-tabase transactions are directed to a specially construct-ed node (hereafter called an FT-node) which is tolerantof certain database faults. Such an FT-node is schemat-ically represented in Figure 5.[0030] Figure 5 is a UML (Unified Modelling Language)Component diagram of an FT-node 50. An FT-node isan instantiation of a database server which embodiesaspects of the invention. Referring to Figure 5, it can beseen that the FT-node (FT stands for fault-tolerant) con-sists of three software components: RDBMS1 51,RDBMS2 52 and Middleware 53. The componentsRDBMS1 51 and RDBMS2 52 consist of the softwareresponsible for data management (SQL engines) and thedata itself (in the form of tables, views, stored procedures,triggers, etc. stored in one or multiple computer files) asrequired by the respective SQL server engine. The com-ponent Middleware 53 consists of three components: aDivRep protocol module 54, a Diagnostic module 55 anda Multicast protocol module 56. The DivRep protocol 54module utiises a DivRep protocol which is a replicationprotocol, that works with the diverse (heterogeneous) da-tabases, RDBMS1 and RDBMS2, via the interfaces eachof them provides (SQL API 1, WS API 1 (shown by ref-erence numbers 51a and 51b provided by RDBMS1, andSQL API 2, WS API 2(shown by reference numbers 52aand 52b) provided by RDBMS 2).[0031] In the arrangement shown in Figure 5, there aretwo RDBMSs present. For many practical purposes, ef-fective embodiments will be provided using two RD-BMSs, each of a different type (for example, one Oracleand one Microsoft SQL 2005). In some cases, it may bedesirable to use a further RDBMS - this may, for example,improve further the prospect of detecting simultaneousand identical failures of more than one RDBMS.[0032] The interaction between the components of theFT-node 50 consists of the Middleware 53 sending op-erations to the RDBMSs 51, 52, and the RDBMSs 51, 52responding to these by either confirming that the opera-
9 10

EP 2 470 994 B1
7
5
10
15
20
25
30
35
40
45
50
55
tion has been completed successfully or instead report-ing an abnormal completion of the operation. The oper-ations offered by the SQL API allow for managing dataobjects in databases (the so called Data Definition Lan-guage (DDL) operations, such as creating/deleting/mod-ifying tables, views, etc.) and also for data (content) man-agement (i.e. selecting data from and inserting/deleting/modifying data in the existing objects, referred to as DataManipulation Language (DML) operations). Another setof operations is typically offered by off-the-shelf RDBMSsto control the privileges of different users to manipulatethe data objects (such as GRANT and REVOKE, fre-quently referred to as Data Control Language operations)- while these may be used in embodiments of the inven-tion, they are not of significance to the FT-node function-ality described here and will not be described further be-low.[0033] SQL API (as represented by 57x, 51a and 52a)offer also a set of operations for connecting externalagents 57, 57n (e.g. application software) to RDBMSs51, 52 (establishing connections), managing transac-tions (i.e. a set of operations treated by the engine as anatomic whole as defined in Appendix A) such as begin,commit or abort a transaction. A set of operations in theSQL API allow for setting the isolation level between thetransactions. In the particular case, it is assumed that theRDBMSs offer support for snapshot isolation betweenthe transactions (see Appendix A).[0034] When an operation is completed successfully,the RDBMSs 51, 52 will return, via the SQL API, eitherthe requested data (in the case of a read operation) or anotification that the operation is completed successfully(e.g. in the case of inserting new data, the RDBMS willtypically return the number of newly inserted rows). Incase no result is received, within a predefined amount oftime (timeout occurs), DivRep protocol module 54 raisesa timeout exception.[0035] When an operation is completed abnormally,the RDBMS 51, 52 wil typically raise an exception (i.e. asignal) to the Middleware 53 detailing the problem (e.g.that the SQL syntax of the submitted operation is incor-rect). Of the many possible exceptions, it is assumedhere that at least one of the RDBMSs 51, 52 used in theFT-node 50 offers a NOWAIT exception feature (herein-after also referred to as ’a NOWAIT exception’) immedi-ately upon detection by that RDBMS that two concurrenttransactions attempt to modify the same data item (e.g.to alter the same row in the same table of the same da-tabase). The feature is typically implemented as part ofthe first phase of a 2-phase lock protocol (see AppendixA for discussion of a conventional 2-phase locking pro-tocol): the transaction, which finds the write lock on arecord taken by another transaction will be interruptedby a NOWAIT exception and the modifications of the par-ticular record by the interrupted transaction will be dis-carded by the SQL server engine, on which the interrupt-ed transaction is executed. Many off-the-shelf products(e.g. Oracle, PostgreSQL, Firebird, etc.) offer the func-
tionality of a NOWAIT exception feature, albeit imple-mented differently and for different purposes than de-scribed here.[0036] WS API 51b, 52b offer ways for the agent con-nected to the RDBMS to extract the write sets, (hencethe term WS API is used) of a transaction. Typically, WSAPI is not a standard feature of an off-the-shelf RDBMS.If a RDBMS is to be used which does not have this fea-ture, custom-built software for write set extraction needsto be added either by modifying the SQL engines or byadding a module, which uses proprietary features of therespective SQL engine. The format of the write sets mayvary, but a reasonable approximation is to think of themas if they were stored in a separate table (as the trans-action modifies the data), from which the agent can readusing the transaction ID as a parameter. The ability tomodify the SQL engines or to add such a module will bewell within the ability of the skilled addressee followingthis specification and so is not described further herein.[0037] The components SW 1 to SW n (shown by ref-erence numbers 57 and 57n) represent the client appli-cations interacting with the FT-node 50. The Client SQLAPI 57x, provided by the Middleware 53, offers function-ality similar to that offered by the SQL API 51a and 52a:DMUDDL operations plus the functionality for establish-ing a connection and transaction management. In effect,for the client applications 57, 57n the Middleware 53 ap-pears as an RDBMS with its own SQL API, e.g. a su-perset of the SQL API of one of the RDBMSs used in thereplication, thus allowing for porting existing applicationsfor work with an FT node 50 without modification.[0038] The Diag API 55a provides for the interactionbetween the DivRep protocol module 54 and the Diag-nostic module 55. Once a failure is detected by the Di-vRep protocol module 54, the Diagnostic module 55 isinvoked to analyse the failed RDBMS (e.g. "rephrasingrules" [Gashi and Popov 2006] are one possible diagno-sis mechanism).[0039] The MC API 56a allows for the interaction be-tween the DivRep Protocol module 54 and the MulticastProtocol module 56. The DivRep Protocol module 54communicates the decisions reached about conflictingtransactions inside the respective FT-node 50 to the Mul-ticast Protocol module 56, which in turn ensures thatthese decisions are reconciled with the decisions fromall other FT-nodes in the system. Once the decisions arereconciled, all the transactions are applied consistentlyon all FT-nodes. Besides guaranteeing data consistencyacross FT-nodes, the use of Multicast Protocol for FT-node replication increases the scalability of the overallsystem through the use of asymmetric processing (seeDiscussion of Prior Art and Appendix A). The particularsof the Multicast Protocol module 56, the associated MCAPI 56a, and the interaction between Multicast Protocolmodules 58 across FT-nodes (represented with thedashed arrowed lines in Figure 5) are not necessary forunderstanding the basic functionality of the FT-node andtherefore are not discussed further here.
11 12

EP 2 470 994 B1
8
5
10
15
20
25
30
35
40
45
50
55
[0040] Figure 6 illustrates the contexts (i.e. the datastructures) created within the Middleware component,which allow for a transaction originating from the partic-ular client to be mapped into transactions with theRDBMS1 and RDBMS2. More specifically, Figure 6shows a UML class diagram illustrating the transactioncontext, maintained in the Middleware component foreach transaction created by a client application.[0041] An implicit assumption is made in the Figure 6that there wil be a single transaction per connection (in-dicated by the 1-to-1 association between the classesConnection and TraManager), which simplifies the de-scription of the embodiments of the present invention.Although such 1-to-1 mapping between connections andtransactions is widely used in practice, in many casesmultiple transactions can share the same connection, acase which would require a trivial extension of the dia-gram and the Client SQL API 61 to allow for the transac-tion ID to be used as a parameter in all Client SQL APIoperations.[0042] Informally, the operation of the FT- node 60 canbe described as follows. The client (e.g. a software ap-plication) first establishes a connection to a named da-tabase by sending a request via the Client SQL API 61to the Middleware (Connect operation) . A Connectionobject 62 is created, which in turn instantiates a TraMan-ager object 63 and sets a transaction ID unique acrossall concurrent transactions. This object then instantiatesa series of objects which would hold the operations, whichmake up the transaction (shown in the diagram as a UMLcomposition with a Statement class) and the respectiveresponses received from each of the RDBMSs on oper-ations’ completion. The responses are stored in instanc-es of the class Response, which in turn may be either aReadSet (in case a read operation is executed) or aWriteSet (in case a modifying operation is executed) .Every response consists of a non- zero number of Da-taRecords. The class TraManager includes (modelled asa UML aggregation association) two dedicated classes(RepManager1 and RepManager2 both derived from theclass RDBMSBuffer holding the operations as sent toand the responses returned by the respective RDBMSs.The communication of the Middleware with the RDBMSsis undertaken by the RepManager objects 64, 65, whichuse the interfaces as defined in Figure 5 (SQL API andWS API associated with the respective RDBMS) .[0043] The instances of TraManager 63,RepManager1 64 and RepManager2 65 are run concur-rently in separate execution threads. If multiple transac-tions are run concurrently, multiple instances of the class-es shown above will be created in the Middleware com-ponent, one set of instances including the triplet ofthreads (TraManager 63, RepManager1 64 andRepManager2 65) per transaction. Due to multithreadingso achieved, the middleware allows for concurrent exe-cution of transactions.[0044] A degree of synchronisation between the trans-actions is achieved at transaction "edges" (Begin and
Commit/Abort operation): the Begin and Commit opera-tions of a transaction are serialised (i.e. their executionsare mutually exclusive (mutex) among TraManager ob-jects). This is supported by defining the methods Beginand Commit in the TraManager class as static, as perUML specification. The protocol does not require a mutexfor the Abort operations. This concurrency control canbe developed further by executing several edges simul-taneously (in ’epochs’), but this will be discussed belowin consideration of variations to this embodiment.[0045] The Client SQL API defines two "data" func-tions, Read (Statement String) and Write (StatementString), which allow for any DML operation to be submit-ted to the middleware; the latter function also allows fora DDL operation to be submitted. It should be noted thattypically the DDL operations (e.g. an operation that mod-ifies a database table structure) are not mixed with DMLoperations, but are instead executed in separate trans-actions. The Client SQL API defines also 3 transactioncontrol operations - Begin, Abort and Commit.[0046] When a data operation is submitted via the Cli-ent SQL API it is propagated to the respective buffers(RepManager1 and RepManager2) and explicitly storedin the Statement object with the attribute "isRead" set to"true" in the case of a ReadStatement operation. TheTraManager object 63 serves as a gateway to pass theoperations from the Client SQL API to the respectivequeues of operations maintained by RepManager1 64and RepManager2 65 (in the respective Statement ob-jects held in the RepManager objects). The actualprocessing of the operations from the queue is left to theRepManager objects 64, 65 (run in their own threads).The RepManager would pull from the queue one opera-tion at a time and submit it for execution by the respectiveRDBMS via its SQL API. The RDBMS may either suc-cessfully complete the operation, in which case the Rep-Manager will fetch the respective response (either viathe SQL API in case of a read operation or via WS APIin case of a write operation) and store these in the re-spective Response object associated with the success-fully executed operation, or the RDBMS may fail to exe-cute the operation successfully, in which case an excep-tion will be returned to the RepManager. The TraManagerobject 63 will monitor the Response objects associatedwith the last submitted operation (using its attribute size,which indicates the number of operations in the transac-tion queue). Once a Response is received, the TraMan-ager object 63 returns it to the client application. Notethat the Response class has an attribute exception oftype String. In the normal case this attribute will be setto an empty String.[0047] In case of an exception being raised by the re-spective RDBMS (e.g. as a result of incorrect syntax ofan SQL operation or a write-write conflict) the attributewill get set to a meaningful value, e.g. "Incorrect syntax".In this case, the response returned to the client applica-tion will return a Response object (e.g. a ReadSet objectin case of a read operation), which will carry the exception
13 14

EP 2 470 994 B1
9
5
10
15
20
25
30
35
40
45
50
55
raised. The TraManager can implement different modesof operation, which will affect the point in time when aresponse is returned to a client application. If the Middle-ware is configured to work in pessimistic mode, the re-sponse will be returned after both RepManager1 andRepManager2 have returned their responses, thesehave been adjudicated by the comparison (see the Com-pareResponses() function shown in Figure 11 and de-scribed later) and no discrepancy has been detected. Ifinstead the Middleware is configured to work in optimisticmode, as soon as a response is returned by eitherRepManager1 or RepManager2, it is returned to the cli-ent application. The adjudication on the two responsesis applied when both become available. The client will benotified if a discrepancy is detected upon adjudicationcompletion.[0048] In case of an exception, the respective Rep-Manager will set its Boolean attribute "isException-Raised" to "true" and stop pulling operations from itsqueue, even if more operations are waiting to be proc-essed.[0049] The TraManager class contains a functioncalled CompareResponses, which is activated when re-sponses (Response objects) from both RDBMSs to thesame statement are collected. This operation returns"true", if the responses are identical and "false", if theresponses differ. In the latter case (non-identical re-sponses), the TraManager object 63 would access theoperation Diagnose() of the DiagAPI interface for diag-nosing which of RDBMS 1 and RDBMS 2 has failed. De-tails of the diagnosis are beyond the scope of the presentembodiment, but it is envisaged that a solution based on’rephrasing rules’ [Gashi and Popov 2006] is possible. Ifthe diagnosis is successful, the operation Diagnose() willreturn the ID of the RDBMS, which has been identifiedto have failed (e.g. 1 for RDBMS 1 and 2 for RDBMS 2,3 for both failing and 0 - if the diagnosis failed). The di-agnosis outcome may be interpreted in different ways(the variations are scrutinised further below). For in-stance, a successful diagnosis may lead to blocking theoperation of the failed RDBMS from further processing(i.e. reducing the FT node to a single RDBMS). Unsuc-cessful diagnosis may lead to fail-stopping the FT-node,i.e. all connections are abnormally dosed by the middle-ware as if the FT-node has crashed.[0050] A further variation of the CompareResponses()operation is setting a timeout (not shown) for the respons-es to be collected. If the timeout is exceeded it will serveas a trigger for diagnosing the RDBMS, which failed toprovide a response. Such timeouts provide a mechanismfor detecting crash failures of the RDBMSs and faults inthe Middleware implementation, which would lead to fail-ing to collect a response from the respective RDBMS.[0051] The TraManager object 63 will also monitorwhether either RepManager1 64 or RepManager2 65have received exceptions from the respective RDBMS(e.g. NOWAIT exception defined above or other such asa deadlock (see Appendix A for explanation) between
concurrent transactions, etc.). If this is detected, then theTraManager will abort the transactions on both servers,using the Abort operations of the respective SQL API. Incontrast with the Begin/Commit operations the Abort op-erations do not have to be synchronised with the opera-tion "edges" of the other transactions (i.e. their respectiveTraManager objects).[0052] When a Commit operation is submitted via theClient SQL API, the Connection passes it on to the Wait-Commit() operation of the TraManager object, which willwait until both RepManagers have processed in full theirrespective queues of operations and then will enter thestatic method (i.e. the mutex) Commit() of the TraMan-ager for committing the transactions on RDBMSs (by in-voking the Commit() operation of the SQL APIs).[0053] The interactions summarised above will now bedescribed in further detail with reference to standard UMLsequence diagrams.[0054] Figure 7 illustrates a typical interaction of es-tablishing a connection, in which the objects associatedwith a transaction are created. The details related to in-stantiating and destruction of the RepManager objectparts - the queues of Statement/Response, have beenomitted for ease of understanding. The objects and theinvocation of their respective methods (shown as mes-sages) are displayed in the diagram. More specifically,Figure 7 is a UML sequence diagram related to estab-lishing and destroying a connection between an externalagent (application software) and the Middleware. The up-per half of the diagram shows establishing a connection,while the lower part dosing a connection, As a result ofclosing a connection the objects are destroyed (indicatedby the crosses at the bottom of the vertical bars (UML’slifelines) showing the lifecycle of the respective objects).[0055] Figure 8 shows the interaction related toprocessing an operation by the FT node, focussing onhow the operations submitted for execution by client ap-plications get stored in the respective queues of Rep-Manager objects 84, 85. More specifically, Figure 8 is asequence diagram showing how a DML statement (aread or a write operation) gets placed in the RepManagerqueues for passing to the RDBMSs for further execution.The upper part of the figure represents the read operationand the lower part the write operation.[0056] The fragments 87a, 87b, 88a, 88b (procedures)with the tag ref StatementExecution 1 and StatementEx-ecution 2 shown in Figure 8 are described in greater detailin Figure 9, which details how an operation in the Rep-Manager queues gets passed on for processing by theRDBMSs. Similarly, CompareResponses procedure86a, 86b is described in greater detail in Figure 11.[0057] Figure 9 is a UML sequence diagram, whichshows the interaction between the RepManager object91 and the respective RDBMSs. Depending on the typeof operation upon its completion either a ReadSet getsreturned to the RepManager or a WriteSet gets fetchedby the RepManager from the WS API 93. In addition, fora write operation it is shown explicitly (in the try fragment)
15 16

EP 2 470 994 B1
10
5
10
15
20
25
30
35
40
45
50
55
the possibility for an exception to be raised by the server(e.g. a NOWAIT exception), which if observed would leadto setting to "true" the isExceptionRaised flag (attribute)of the respective RepManager.[0058] In Figure 9, the detailed interaction between theRepManager object with its parts, the Response objectand of the Response object with its parts (the DataRecordobject (s) ), for storing the data returned as a result ofexecuting the operation, have been omitted as these aremere details of how the innovation can be implemented,which would be within the knowledge and capability ofthe skilled addressee.[0059] Figure 10 shows a UML sequence diagram ofcommitting a transaction. A Commit operation gets sub-mitted by an agent, which then gets relayed to the Tra-Manager object 103 (its WaitCommit() operation). TheTraManager 103 waits until both its RepManagers ob-jects 106, 107 have processed in full their respectivequeues, upon which enters its own static (mutex) oper-ation Commit() within which Commit() is submitted toboth RDBMSs. At this stage, the databases are modified(a Write operation carried out only on the extracted write-set is now applied to the actual database from which itwas extracted). SQL API Commits are invoked concur-rently and TraManager object 103 waits for commits tocomplete by both RDBMSs, and RepManager queuesare cleared by the ClearStatements operations 108 (thefragment (procedure) at the bottom of Figure 10.).[0060] Invoking the SQL API Commits are shown asasynchronous operations. However, TraManager object103 does wait for the commit to complete - successfulcompletion of both commits is needed for the RepMan-ager queues to be cleared by the ClearStatements op-erations 108 (the fragment (procedure) at the bottom ofFigure 10.)[0061] An important feature of the present embodimentis that the responses of the replicas are compared, whichoffers ways of detecting non-crash failures (discrepancyof the results obtained from RDBMSs). The interactionbetween objects related to comparison is shown in Figure11 and described below.[0062] Figure 11 is a sequence diagram showing theinteraction related to comparison of the Responses fromthe RDBMSs. The comparison is carried out once theresponses from both RDBMSs to the same operationhave been received (the TraManager object 111 moni-tors the value of the attribute isCompleted of the sameoperation in both RepManager1 112 and RepManager2113) and when both are set to "true" the operation Com-pareResponses() as shown in Figures 6 and 8 of theTraManager object is invoked. In the case a discrepancyis detected, the TraManager object 111 invokes the op-eration Diagnose() of the Diag API 114 (part of the Diag-nostic module as shown in Figure 6. It is to be noted thatthe "membership" of the attribute isCompleted in the re-spective RepManagers is implicit from the diagram in Fig-ure 6. The semantics of the part of the UML diagramconsisting of Statement, RDBMSBuffer and RepManag-
ers is as follows: every object of the class RDBMSBufferconsists of, among other attributes, a number of State-ment objects (possibly zero). The classes RepManager1and RepManager2 are specialisations ("subclasses") ofthe general class RDBMSBuffer, and as such they inheritall the attributes that the general class contains. Thus,they each contain (the reference to) the isCompleted at-tribute of every respective Statement object.[0063] The interaction beyond invoking the Diagnose() operation is not discussed further here, but is discussedfurther below when variations to this embodiment areconsidered.[0064] Figure 12 shows the procedure of exceptionhandling by the Middleware. More specifically, Figure 12shows a UML sequence diagram of an exception handlerused in the DivRep replication protocol. The operationsAbort() are executed concurrently, TraManager waits un-til the aborts are completed by the respective RDBMSs.[0065] The logic presented here is minimalistic - anyexception raised by either RDBMS 1 or RDBMS 2 leadsto aborting the transactions on both RDBMSs. Althoughmore refined algorithms of exception handling are pos-sible, the one presented here is sufficient for achievingconsistent operation on both RDBMSs.[0066] A formal description of the operation of DivRepis provided, by supplying a pseudo-code of the replicationprotocol used by the DivRep module. This pseudo-codeis shown in Figures 13 and 14, and is discussed withreference to these Figures below.[0067] As mentioned in the previous section, the Di-vRep module executes on Transaction Managers (re-ferred to as TraManagers, see pseudo code shown inFigure 13, which illustrates the execution of the DivRepprotocol on a TraManager) - there is one TraManagerserving each client, as well as on Replication Managers(referred to as RepManager, see pseudo code shown inFigure 14, which illustrates the execution of the DivRepprotocol on a RepManager) - there are n RepManagersper each TraManager, where n is the number of RDBMSsdeployed in an FT-node (n=2 in the embodiment de-scribed above but can be any integer greater than 1. Theexecution of this embodiment of the replication protocol(Figures 13 and 14) assumes that every transaction sub-mitted by a client consists of a transaction begin opera-tion, a non-zero number of read or write operations (awrite operation is either a DML or DDL operation) andfinishes with a oommit or an abort operation.[0068] In this embodiment of the replication protocol,the following features have been set to enable successfulexecution of the replication protocol:
• One of the replicas is configured with NOWAIT ex-ception parameter enabled. The other replicas areconfigured with NOWAIT exception disabled (the im-portance of this is described below).
• The TraManager is instantiated; a connection existsbetween the client executing a transaction and theTraManager object.
17 18

EP 2 470 994 B1
11
5
10
15
20
25
30
35
40
45
50
55
• It is assumed that every client is "well-behaved" inthat it submits operations with dearly defined trans-action boundaries: each transaction starts with a be-gin operation, followed by a number of reads andwrites and in the end it either commits or aborts.
• Crashes of replicas are detected by putting timeoutsin RepManagers, on any of the read or write opera-tions. If timeouts occur they will result in the expectedresponses being set to represent exceptions by theRepManagers. Similarly, for the commits and abortstimeouts are set up by the TraManagers.
[0069] A TraManager accepts transaction operationssubmitted by a particular client. It deals in a specific waywith every operation depending on its type, e.g. transac-tion boundary operations (begins, aborts and commits)are treated differently than the read and write operations.If an exception occurs during the processing of a trans-action, TraManager notifies the client after indicating thatthe transaction needs to abort (set transaction to abort).As a result, the Abort function is triggered - the functionsubmits aborts to all RDBMSs (abort operation for eachRDBMS is executed in a separate thread) through therespective SQL API without sending them first to the Rep-Managers.[0070] The execution of a begin operation includes thefollowing steps: first, the variable indicating that a partic-ular transaction should abort is reset, i.e. its value is setto false; then the global mutex, contended for by all Tra-Managers, is acquired; the begin operation is sent to allRDBMSs for transaction snapshots to be created - thisis done directly through each replica’s SQL API, withoutsending it first to RepManagers. No commit or begin op-eration can execute unless the TraManager holds themutex, and thus consistent snapshots (unchanged byany other transaction commit) are taken on all replicas;the global mutex is released; and finally the control isreturned to the client. If at any time during the processingof the begin operation an exception is raised, the trans-action abort is flagged, which subsequently will triggerthe Abort function.[0071] The execution of a read or a write operation istreated in the same way in TraManager. First, the oper-ation is placed in the queues of all RepManagers. Oncethe fastest response is received (i.e. an RDBMS has suc-cessfully executed the operation passed to it by the re-spective RepManager), it is returned to the client. If anexception is received, however, the transaction is set toabort, triggering the Abort function. Without occurrenceof an exception, the processing continues by TraManag-er waiting for the responses from all RDBMSs. Once allof them are collected, the Comparator function is initiat-ed. Similarly to Abort function, the Comparator executesasynchronously with TraManager and the respectiveRepManagers. It compares the corresponding respons-es from all RDBMSs and if it finds a mismatch betweenresults the transaction abort is set, indicating to the clientthat "data inconsistency" exception has occurred.
[0072] If the client submits an abort operation, the Tra-Manager triggers the Abort function by setting transactionabort.[0073] Once the commit operation is submitted, theTraManager checks if a transaction abort has been al-ready set. If it has not, once the votes from all replicas(confirming that all reads and writes have finished) andthe Comparator vote (confirming no result mismatch wasfound) are collected, the mutex is acquired. Similarly tothe execution of the begin operation, no commit or beginfrom other transactions can execute while the TraMan-ager holds the mutex. This guarantees that the order ofthe commits and begins is the same on all replicas. Afterall replicas have acknowledged that the commit has beenexecuted, the mutex is released. The queues of the Rep-Managers are then cleared, preparing them for the exe-cution of the following transaction, and the control is re-turned to the client.[0074] Figure 15 shows a timing diagram of theexecution of transaction T, using DivRep protocol asdescribed in Figure 13. The Middleware (M) sends 151a,151b the operations (op1, ...opn) to the two replicas (S1and S2) as they arrive from the client application (topreserve the clarity of the figure, middleware M isdepicted as sending all the operations in a batch to thereplicas; in DivRep, instead, the middleware sendsoperations successively, as soon as they are receivedfrom the client) . The execution of the operations takesplace in parallel on the two replicas, and thus theresponse time (ΔTi
Parallel) of T, is, in general case, shorterthen if HRDB (see Figure 3) or Byzantium approach (seeFigure 4) was used. The transaction duration is likely tobe prolonged due to the use of the Comparator Function(this detail is not.shown in Figure 15) . The actual delayis, however, likely to be minimal because the results’comparison in DivRep is performed in parallel with theoperations’ executions on the replicas (assuming theprotocol is configured in the optimistic regime asdescribed above), and thus all but the result of the lastoperation (opn) might have been compared before theslower server completes all operations. The assumptionof the minimal delay is, of course, dependant on theperformance characteristics of the Comparator Functionand the sizes of the results to be compared. Note thatthe only two, "peer" replicas are shown to be executingthe transaction in DivRep- no notion of the local, i.e.primary replica, exists as is the case in HRDB andByzantium.[0075] The part of the DivRep protocol executed onRepManagers (shown in Figure 14) is simpler than theexecution on the TraManagers - Replica Managers ex-ecute only read and write operations. As long as thereare unexecuted operations in a particular RepManagerqueue and the corresponding transaction is not set toabort, the processing proceeds as follows. If it is a readoperation, the operation is sent to the RDBMS, the re-sponse (either data or the exception due to unsuccessfulexecution) is fetched and returned to the TraManager.
19 20

EP 2 470 994 B1
12
5
10
15
20
25
30
35
40
45
50
55
The processing of the write operation differs from theprocessing of a read in that RepManager has to explicitlyinitiate the extraction of the WriteSet. The WriteSet, iden-tically to the result of a read operation, is sent to the Com-parator function of the TraManager for validation.[0076] Going back to the configuration of the systemprior to execution of the DivRep protocol, the asymmetricconfiguration of the replicas (one is configured with aNOWAIT exception enabled while all other replicas havea NOWAIT exception disabled) is important. This em-bodiment uses a NOWAIT exception feature as a mech-anism of immediate reporting the write-write conflicts byone of the RDBMSs, not both. Thus write-write conflictswill typically be reported by a single replica while on theother replicas, transaction blocking will take place in caseof write-write conflicts. The exception handler, providedfor NOWAIT exceptions, implements for one of the rep-licas a mechanism, which resolves consistently the con-sequences of non-determinism between RDBMS 1 andRDBMS 2.[0077] Had both replicas been allowed to report imme-diately a write-write conflict would have led to unneces-sarily high abort rate. For instance, had both RDBMS 1and RDBMS 2 used NOWAIT any race between twotransactions, which without NOWAIT would have led toa deadlock (see Appendix A) might have led to NOWAITexceptions being raised against both transactions. Typ-ically, this would have led to aborting both transactionsby the DivRep protocol, while aborting only one wouldhave sufficed and the second transaction could have pro-ceeded.[0078] Furthermore, the hierarchical data structureused to implement the DivRep protocol is important andadvantageous. The above- described embodiment spe-cifically shows how the responsibiities for the differentoperations (data manipulation vs. transaction control) arehandled by a transaction manager thread (TraManager)and the replica management threads (RepManager) .The embodiment also describes how once the state of atransaction is set to abort, the transaction manager (Tra-Manager) will efficiently block any further operations wait-ing in the RepManager queues of the replica managers,thereby leading to fast response times once an abort con-dition is detected.[0079] One further important characteristic of thepresent embodiment relates to the functionality betweenthe client and the middleware application. The DivRepreplication protocol described above communicates ex-ceptions from Middleware to the client applications asthey occur, and thus client applications respond faster toa situation when transaction aborts occur. This commu-nication is important because the client application needsto be aware as soon as possible that a transaction cannotbe committed. Without this communication, the unnec-essary processing of the client application would likelylead to more read or write operations being sent to themiddleware before the transaction is eventually aborted.[0080] The embodiment described above will now be
compared with solutions based on other approaches.[0081] There are various solutions based on the ’readonce write all available’ (ROWAA) approach, which in-clude the solutions for snapshot isolation based on reli-able multicast. Unlike these solutions, the embodimentdescribed above provides a defence against a class offailures wider than the crash failures targeted by theROWAA solutions. As Figure 16 dearly shows, the ROW-AA solutions execute the read statements on a singlereplica and assume that if a response is received fromthe replica it is correct. As empirical studies indicate, suchan assumption is unjustifiable. With respect to the writeoperations, although in ROWAA solutions the modifyingoperations are applied to all replicas, their correctnessis not adjudicated beyond the assumed crash failuremodel.[0082] Referring to Figure 16 in greater detail, a timingdiagram of a typical ROWAA for snapshot isolation rep-lication based on reliable multicast, is shown. The trans-action execution time consists of 4 parts: the time it takesthe local transaction to complete all operations of thetransaction, T (op1, ... opn), the time for the middlewareto multicast the write sets (WS) accumulated by the localreplicas, TMC (WS), the time it takes the remote replicasto validate the WS, TWS validation and the time it takes theremote replicas to apply the WS, TWS application.[0083] In contrast, DivRep of the embodiment de-scribed above offers a comparator function, CompareRe-sponses (), which allows for any discrepancies betweenthe responses to be detected and acted upon. If at leastone replica works correctly, and the diagnosis is success-ful some failures may be masked. If diagnosis is not suc-cessful (it is unclear if there is a correct replica), the mid-dleware may at least detect a problem, and as a minimummay record it, or preferably will report to the client appli-cation that the FT- node failed to complete the operation.[0084] The solutions with snapshot isolation surveyedin the section ’Prior Art’ deal with write sets in a differentway from the DivRep protocol described above. Theknown solutions for databases with support for snapshotisolation based on reliable multicast (e.g. Middle- R, [Pat-ino- Martinez, Jimenez- Peris et al. 2005] ) minimise thenumber of messages exchanged between the replicasby exchanging the write sets of the transactions as asingle message. The replica designated to serve as a"local" replica, collects the write sets produced by themodifying operations of the transaction and propagatesthem when the local replica is ready to commit.[0085] In effect, this prior art method is a specific im-plementation of the Primary/Secondary scheme, in whichthere are two distinct parts in the processing of eachtransaction as shown in Figure 2. The "local" replica ex-ecutes the transaction in full, while the other replicasprocess only the WriteSet multicast by the "local" replica.In contrast with the standard primary/secondary arrange-ment, solutions similar to Middle-R require a "validation"phase by all the replicas of the write sets being multicast,the implementation of which is not defined in sufficient
21 22

EP 2 470 994 B1
13
5
10
15
20
25
30
35
40
45
50
55
detail to allow for any educated guess on how expensivethis validation can be in comparison with the cost of mul-ticasting a message. In any case, the transaction durationwith multicast is likely to be longer than if the transactionswere executed in parallel.[0086] Note that in multicast-based solutions the rep-licas will complete the transactions at different times and,if a new client connects to the replicated database, thedata that this client will ’see’ (via the snapshot of the da-tabase it will take) depends on which replica it is con-nected to. In the example case shown in Figure 16, anew client connected 164 at time t to either the "local" or"remote1" replica will see the effects from the transactiondetailed in the diagram. If the client, however, connectsto replica "remote2" it will not see the effect of the trans-action, since this transaction is yet to be committed. This’feature’ may seem insignificant - after all the client willnever interact with more than one replica. In some ex-treme scenarios, however, e.g. as a result of using a poolof connections, the client may end up being connectedto different replicas for successive transactions. Then thisclient may be affected by the phenomenon identifiedabove: the transactions which this client successfullycommitted on the initial local replica (initial local replicatransactions) may be still in progress by the replica towhich this client has been connected for the subsequenttransactions (subsequent local replica transactions). Asa result, the client may be unable to ’see’ the data thatthe transactions (i.e. the initial local replica transactions)have written to the database - this could happen not be-cause the data have been changed by another transac-tion, but simply due to the particular way the multicast-based replication protocol is optimised. In contrast, Di-vRep protocol of the present invention does not sufferfrom a similar deficiency. Since the transaction edgesare processed in atomic operations, the creation of a newsnapshot is impossible until all previous transactionshave been committed on all replicas.[0087] As indicated above, HRDB and Byzantium alsopossess protocols which use diverse replicas. Differenc-es between the embodiment described above, with itsDivRep protocol, and these schemes and their protocolsare considered below. In all three cases concern is givento the effects of non-crash failures of the RDBMSs. Thefailure models used by the other schemes, however, aredifferent. HRDB and Byzantium target the so called Byz-antine failures - the most general known type of misbe-haviour in distributed systems, an example of which arereplicated databases.[0088] In the protocol of the embodiment describedabove failures are targeted, for the existence of whichthere is empirical evidence: significant proportion of fail-ures observed with several RDBMSs summarised in thesection Prior Art are non-crash failures. More importantly,the empirical studies show that using diverse (heteroge-neous) RDBMSs makes detecting such failures very like-ly. Although these failures nominally can be called Byz-antine failures (any failure is a special case of Byzantine
failure), they fall short of malicious behaviour such assending different messages to different participants in adistributed system, a unique characteristic of Byzantinefailures. It is the malicious aspect of Byzantine failures(behaviour) that makes Byzantine failure very extensiveto tolerate. Opting for tolerating Byzantine failures mayseem an advantage, but it has its cost. Unless there isevidence that Byzantine failures are a likely problem, tol-erating them may be an expensive and unnecessary lux-ury. Byzantine behaviour is inherent in some cases ofdistributed systems (e.g. the behaviour of a sensor readby distributed applications may be adequately modelledas Byzantine behaviour). However, there is no empiricalevidence of such behaviour for RDBMSs. For RDBMSswith snapshot isolation, there is no obvious mechanismto promote Byzantine failures: once a snapshot is takenthe data remains stable until another snapshot is taken.The proposers of HRDB and Byzantium justify the deci-sion to use the Byzantine failure model with evidencethat crash failure model is implausible.[0089] The cost of tolerating Byzantine behaviour ishigh. HRDB and Byzantium introduce a degree of redun-dancy required for a Byzantine agreement to becomepossible - at least 4 participants (3 replicas + a coordi-nator middleware) sufficient to tolerate a single Byzantinefault. In the absence of empirical evidence that the Byz-antine behaviour may occur, solutions tolerating such be-haviour can be seen as unnecessary ’extensive’.[0090] Instead the DivRep protocol set out for the em-bodiment above takes a more "economical" approachand requires 2 RDBMS + a replication middleware, suf-ficient to detect a single failure. In fact, the DivRep pro-tocol of the embodiment described would tolerate non-crash failures of one of the used RDBMSs. As far as theMiddleware is concerned, it is assumed to be free of de-sign faults (i.e. is correct by design) and for it, a crashfailure model is sufficient (similar to the assumption madeby HRDB for the respective middleware, referred to asCoordinator). This assumption is plausible, as the proto-col is relatively sample and its correctness can be provenformally.[0091] In the embodiment described, if the middlewarecrashes then the entire FT-node becomes unavailable.The person skilled in the art would be able to provide anappropriate solution to enable alternative resources inthe event of such a failure - one such approach would beto use a standard ’fail-over’ solution (e.g. as in passivereplication using a primary-backup, also called leader-follower, scheme [Mullender 1993]) sufficient for tolerat-ing crash failures.[0092] The differences between HRDB and the DivRepprotocol of the embodiment set out above have beenoutlined previously. Both HRDB and Byzantium use avariant of the Primary/Secondary scheme (see Figures2 and 3). As a result, the transaction is prolonged byserial execution of operations on the primary and the sec-ondaries. The scheme avoids non-determinism betweenthe primary and the secondary replicas, but in cases with
23 24

EP 2 470 994 B1
14
5
10
15
20
25
30
35
40
45
50
55
high likelihood of write-write conflicts, the longer thetransactions the greater the chance of a conflict on theprimary, i.e. high abort rate. In the cases when the like-lihood of write-write conflicts is low, avoiding non-deter-minism with the use of primary/secondary scheme bringsvery little to no advantage but incurs a significant increaseof the response time. Indeed, in the extreme case of nowrite-write conflicts non-determinism in the replicas con-figured with snapshot isolation has no effect on concur-rency control. Thus with such workload of operations se-rialising the execution of the (write) operations on theprimary and the secondaries is not necessary, and sothe performance overhead is not justified.[0093] In the DivRep protocol described above the op-erations are executed in parallel on all replicas - in theversion described, the protocol is optimistic in the sensethat it assumes implicitly that there will be no write-writeconflicts between the transactions. Therefore, if indeedthe write-write conflicts are infrequent in the workload,the DivRep protocol described above would offer betterperformance than HRDB. If write-write conflicts do occur,non-determinism between the replicas might lead to dif-ferent orders of transactions on different replicas. TheDivRep protocol overcomes the problem using NOWAIT,the specific feature enabled on one of the RDBMSs forconsistent resolution of the conflict (by aborting the sametransaction on all replicas) and allowing the same trans-action to eventually become ready to commit. In summa-ry, the difference between the DivRep protocol on theone hand and HRDB/Byzantium protocols on the otherhand is in the way the effects of non-determinism aredealt with: the DivRep protocol allows for non-determin-ism and overcomes its effects when this is needed. HRDBand Byzantium protocols instead merely avoid the effectsof non-determinism at the cost of performance overhead.[0094] Handling NOWAIT exceptions leads to perform-ance overhead, too. However, whilst this performanceoverhead is application specific, it is almost always lessthan the performance overhead incurred by the use ofprimary/secondary scheme used by the HRDB protocolwith a small number of RDBMSs. DivRep is likely, there-fore, to be faster than HRDB in certain applications, e.g.where there is a low abort rate.[0095] The Byzantium replication protocol, as dis-cussed in the Prior Art section, is worse in terms of per-formance than the HRDB protocol as the operations areexecuted on the secondaries only once the primary hascompleted all the operations of a transaction. Thus, theDivRep protocol is highly likely to outperform the Byzan-tium protocol in a wider range of operational conditions.[0096] Variations to the embodiment described abovewill now be discussed.[0097] The DivRep protocol described above offersseveral regimes of operation. The pessimistic regime ofoperation requires comparison of the responses fromRDBMS1 and RDBMS2 and only if no discrepancy isdetected will a response be returned to the client. A dis-advantage of this scheme is that the slower RDBMS may
take much longer to produce a response. The optimisticregime, instead, will return the first response receivedfrom either RDBMS 1 or RDBMS 2, optimistically assum-ing that no mismatch between the responses will occurlater when both have been received and adjudicated.[0098] There is a scope for improving performance inprocessing the edges of transactions. This may beachieved by executing several non-conflicting transac-tion edges inside a single mutex, possibly in differentorders on two RDBMSs. Firstly, if multiple transactionsare ready to commit (i.e. the client application has sub-mitted a commit to the respective transactions), thesecan be executed in the same mutex (the order of thecommits might be different on two RDBMSs without com-promising the consistency of the replicas, since the sit-uation represents non-conflicting transactions executedin parallel). Secondly, multiple begins can be executedin the same mutex, as they will merely cause the samesnapshot of the data to be used in multiple transactions(the order of the begins might be different on two RD-BMSs without compromising the consistency of the rep-licas). The relative order between commits and begins,however, has to be the same on all RDBMSs.[0099] The replication protocol described above canbe applied with a range of error handling mechanisms,which are briefly discussed below.[0100] In case a discrepancy is detected between theresponses by the RDBMSs, the replication protocol mayuse a diagnosis module to determine which of the tworeplicas has failed. The embodiment described here in-tentionally does not commit to a particular diagnostic rou-tine as different diagnosis techniques can be applied indifferent embodiments. One possibility which is consid-ered is the use of ’rephrasing rules’ [Gashi and Popov2006], in which the diagnosis module would ’rephrase’the operations (SQL statements), which have resulted indifferent responses by the RDBMSs. This approach isdescribed below purely by way of an illustrative example.As a result of rephrasing, statement invariants (i.e. logi-cally equivalent operations) are derived using the redun-dancy built in the SQL. The diagnosis consists of sub-mitting to the RDBMSs invariants of the operations. Forexample, a statement may be placed in a stored proce-dure and then the stored procedure executed instead ofsubmitting the SQL statement. Then the middleware willcompare the responses received for invariants with thoseobtained for the original statements. If a qualified majorityamong the responses (for the original statements andtheir invariants) is reached, then the ’correct’ responsewil be known and in some cases the failed RDBMS willhave been identified. For instance, if an RDBMS ’chang-es’ its response between the original response and theinvariants produced for it, then it is dearly faulty. Ofcourse, the diagnosis may fail, e.g. a qualified majorityis achieved on an incorrect response, but this will typicallyrequire majority of the RDBMSs to fail on the particularstatement, a situation which is highly unlikely.[0101] Options are available in different embodiments
25 26

EP 2 470 994 B1
15
5
10
15
20
25
30
35
40
45
50
55
in respect of confinement of errors: when discrepancy isdetected, the respective transaction on the failed RDBMScan be aborted. Submitting to the RDBMS an invariantof the operation, which has triggered the failure, and ob-taining a ’correct’ response from this RDBMS will be asufficient error confinement measure, provided the fail-ure did not affect the ACID properties of the RDBMS (i.e.the failure did not outlive the transaction context). An al-ternative would be to degrade gracefully the affected FT-node to a single replica (i.e. switch off the failed RDBMSfrom processing any further operations coming from theconnected client applications) and subject (possibly aftera reboot) the failed RDBMS to scrutiny targeted at iden-tifying whether the error propagated beyond the transac-tion where the discrepancy occurred by comparing thedatabase on the failed RDBMS with the database of anRDBMS which remains operational within the FT node.[0102] FT- node recovery from a graceful degradationis another aspect which may be achieved in differentways in different implementations of the replication pro-tocol described above. The choice of a particular recov-ery policy will be dictated by the trade- offs to be struckbetween availability and thoroughness of the recovery.Several options are possible:
- putting the repaired RDBMS (i.e. which has beenswitched off the FT-node and subjected to variouschecks) into a ’catch up’ mode, in which a recoveryroutine would extract from the operational RDBMSof the FT-node a valid snapshot of the databasesbeing recovered and apply these to the databasesof the RDBMS being repaired.
- another option would be placing the FT node in adegraded mode to configure the correctly functioningRDBMS for operation in such a way as to store allthe database changes (write sets) applied to this RD-BMS in a form suitable for use by the failed RDBMS(e.g. write log). Once the failed RDBMS is ready fora recovery (after a reboot and successful completionof the checks envisaged in error confinement) thewrite sets from the write log wil be applied to theRDBMS being repaired. Such an arrangement willallow for restoring the state of the recovered RDBMSfast (i.e. a fast ’catch up’) by applying the changeswhich have occurred since this RDBMS has beenswitched off the FT node, instead of applying thewhole valid database snapshot as described above,in the first recovery option.
Appendix A - Concepts and Background
Transactions
[0103] Database transactions are logical units of workwithin a relational database management system (RD-BMS) that are treated reliably and independently of eachother. A transaction represents a unit of interaction withan RDBMS and consists of any number of read and write
operations and finishes with either commit or abort. LetD = {x1, x2, ... xn} be a representation of data items storedin a database and let r(xk) and w(xk) be a read and a writeoperation on data item xk: xk ∈ D respectively, and let cand a be the commit and abort operations. A transactionTi is defined [Bernstein, Hadzilacos et al. 1987] to be apartial order with ordering relation "<i" where:
1) Ti # {ri(xk), wi(xk) | x ∈ D} ∪ {ai ci};2) ai ∈ Ti iff ci ∉ Ti;3) let o be ai or ci, whichever is in Ti, for all otheroperations o’ ∈ Ti: o’<i o; and4) if ri(xk), wi(xk) ∈ T, then either ri(xk) <i wi(xk) or wi(xk) <i ri(xk);
[0104] The meaning of the conditions 1) to 4) above isas follows: Condition 1) describes the types of opera-tions, Condition 2) indicates that either an abort or a com-mit is part of a transaction, but not both; Condition 3)indicates the order of operations such that commit orabort (whichever occurs) must follow all other operationsin the transaction and Condition 4) indicates that opera-tions on a common database item must be ordered in aparticular way.[0105] An inplicit assumption is made in the abovemodel: a transaction writes a particular data item onlyonce. This is the reason why in the Condition 4) a pair ofwrite operations is not considered.[0106] The first formal discussion of database trans-action properties can be found in [Gray 1981]. Since thena standard approach has emerged in the literaturethrough ACID properties. The acronym ACID stands forthe following:
- Atomicity - ability to guarantee that either all of thetasks of a transaction are performed or none of themis.
- Consistency - ability to preserve the legal states im-posed by the integrity constraints. More informally,this means that no rules are broken as a conse-quence of transaction execution.
- Isolation - ability to make operations in a transactionappear isolated from (all) other operations executedby concurrent transactions.
- Durability - ability to guarantee that changes madeby a transaction are permanent once the transactionsuccessfully completes (commits).
[0107] Figure 17 shows distributed transactions, whichcomprise execution of one or more operations that, indi-vidually or as a group, update and/or read data on twoor more distinct nodes of a replicated database. A dis-tributed transaction must provide ACID properties amongmultiple participating databases, which are commonlydispersed among different physical locations. More spe-cifically. Figure 17 illustrates execution of a distributedtransaction, Ti, in a replicated database. Each operation,op ∈ {opi,1, ..., opi,k, ... opi, n(i)}, of the transaction Ti is
27 28

EP 2 470 994 B1
16
5
10
15
20
25
30
35
40
45
50
55
initiated at client C and sent to all replicas {RA, RB, ...Rx} in the replicated database. Each of the operationscan be one of the following: database item read, databaseitem write, transaction abort or transaction commit. Theinteraction between the client and the replicated data-base is simplistic in that it excludes the mechanism thatenables the client to perceive the replicated database asa single entity (typically this would be implemented by amiddleware) . Also, the interaction of other, concurrentlyexecuting clients and the replicated database is notshown in the figure.
Isolation Levels
[0108] Concurrency control mechanisms in RDBMSsensure that transactions execute concurrently without vi-olating data integrity of a database. A property of con-currency control mechanisms is the provision of differentdegrees of isolation between the transactions’ execu-tions - these mechanisms determine when the modifica-tions of one transaction become visible to other, concur-rent transactions. However they should also prevent con-current executions which exhibit worse performance thana serial execution (Second Law of Concurrency Control[Gray and Reuter 1993]). A component in an RDBMS,referenced to as scheduler, manages the overlappingexecutions of transactions. A scheduler receives opera-tions from users and makes sure that they are executedin a correct way, according to the specified isolation level(s).[0109] Out of all ACID properties, the isolation propertyis of particular interest. The isolation property has ap-peared for the first time under the term Degrees of Con-sistency in [Gray, Lorie et al. 1975]. Different types ofisolation have been proposed. The ANSI SQL standardspecifies four levels of isolation [ANSI 1992]: serializable,repeatable read, read committed and read uncommitted.The highest level of isolation is the serializable level,which requires every history of transaction executions(i.e. the order in which the operations of the differenttransactions are executed) to be equivalent to a serialhistory, i.e. in a serializable history, transactions appearto have executed one after another without overlapping.Lower isolation levels are less restrictive but they canintroduce inconsistencies during transaction executions,i.e. they offer better performance at the expense of com-promising consistency. Due to its impact on system per-formance, isolation is the most frequently relaxed ACIDproperty. The trade-off between data consistency andperformance is an inherent part of any RDBMS’s concur-rency control mechanism.[0110] The ANSI SQL isolation levels have been criti-cised in [Berenson, Bernstein et al. 1995] and [Adya, Lisk-ov et al. 2000] because they do not accurately capturethe isolation levels offered by many RDBMS products.The work in these two papers has shown that the threephenomena defined by ANSI SQL for characterising theisolation property are ambiguous and they fail to distin-
guish between all possible anomalous behaviours of dif-ferent isolation levels. Therefore, the work in [Berenson,Bernstein et al. 1995] defines an additional isolation level,snapshot isolation (SI), which is offered in leading com-mercial and open-source database systems (Oracle, Mi-crosoft SQL Server, with certain variations, Sybase,PostgreSQL etc.).
Snapshot Isolation (SI)
[0111] SI is the isolation level assumed in the databaseproducts used in the DivRep protocol of the present in-vention. It is commonly implemented using extensionsof multiversion mixed method described in [Bernstein,Hadzilacos et al. 1987], and the ANSI SQL standard plac-es it between the two strictest isolation levels, repeatableread and serializable isolation level. A transaction exe-cuting in snapshot isolation operates on a snapshot ofcommitted data, which is obtained when transaction be-gins; the changes of the transactions committed after thebegin are invisible to the transaction. Snapshot isolationguarantees that all reads of a transaction see a consistentsnapshot of the database (i.e. repeatable read isachieved). Additionally, any write performed during thetransaction will be seen by subsequent reads within thatsame transaction. In case a write-write conflict occursbetween transactions (i.e. when write operation(s) of twoor more concurrent transactions attempt to modify thesame data item(s)) at most one of these can be commit-ted. The other transactions, involved in the write-writeconflict have to be aborted. An attempt by a client appli-cation to commit more than one transaction involved ina write-write conflict typically leads to the RDBMS over-riding the client commit and aborting all but one of thewrite-write conflicting transactions.[0112] In general, concurrent transactions are definedas follows: for a begin operation, b, and a commit oper-ation, c, where bi, ci ∈ Ti and cj ∈ Tj, the two transactions,Ti and Tj, are considered to be concurrent if the followingholds: bi < cj < ci.[0113] Snapshot isolation has the advantage of avoid-ing conflicts between read-read and read-write opera-tions - the executions of any pair of concurrent read op-erations, or any pair of concurrent read and write oper-ation never conflict. These properties improve perform-ance and make SI more appealing than the traditionalserializable isolation level. This is particularly evident inthe workloads characterised with long-running read-onlytransactions and short modifying transactions.[0114] Most RDBMSs which offer the snapshot isola-tion level use Strict- 2- Phase- Locking (S2PL) . In thefirst phase, the transaction acquires exclusive locks forwriting data items. These locks are released in the sec-ond phase, only once the transaction has finished with acommit or abort. Instead of waiting for a transaction com-mit and using first- committer- wins rule, these concur-rency control mechanisms commonly check for write-write conflicts at the time the transaction executes a write
29 30

EP 2 470 994 B1
17
5
10
15
20
25
30
35
40
45
50
55
operation and apply the first- updater- wins rule [Fekete,O’Neil et al. 2004] . This mechanism is now explained inmore detail below.[0115] In order to write a data item y, transaction Ti hasto obtain an exclusive lock on y. There are two possiblecases:
a) if the lock is available, Ti performs a version checkagainst the executions of the concurrent transac-tions. Two outcomes are likely: if a concurrent trans-action had modified the same data item and it hadalready committed, Ti has to abort (if first-updater-wins rule is used Ti aborts as soon as it tries to modifythe data item; or if first-committer-wins rule is usedTi aborts when it attempts to commit, see Figure 18,Case a)); otherwise it performs the operation.
b) If the lock is unavailable, because another trans-action Tj has an exclusive access, Ti is blocked. If Tjcommits, Ti will have to abort (similarly to the Casea) above, if first-updater-wins rule is used Ti abortsas soon as Tj has committed, or if first-committer-wins rule is used Ti aborts when it attempts to com-mit), see Figure 18, Case b)). On contrary, if Tjaborts, Ti will be granted the exclusive lock on y sothat it can proceed and potentially commit success-fully if no conflicts with other concurrent transactionsoccur.
[0116] If the first-updater-wins rule is used, in either ofthe above cases a) or b), the key is that the version checksare performed at the time Ti attempts to create a version,and not when it attempts to commit. This is called a ver-sion-creation-time conflict check.[0117] Figure 18 is a timing diagram showing the useof Strict 2- Phase Locking concurrency control and first-updater- wins and first- committer- wins rules for enforc-ing Snapshot Isolation. Case a) shows that transactionTi is aborted after the concurrent transaction Tj modifieda same data item (y) and committed 181- the abort occurseither, as soon as Ti attempts to write the data item y(first- updater- wins rule) 182 or when Ti attempts to com-mit (first- committer- wins rule) 183. Case b) shows thatTi is aborted after the concurrent transaction Tj modified184 a same data item, y, and committed- the abort occurseither as soon as Tj commits 185 (first- updater- winsrule) while Ti is waiting to acquire the lock, or when theTi attempts to commit (first- committer- wins rule) 186.
Database Replication
[0118] Database replication is a process of sharing da-ta between redundant resources, which typically belongto a system of physically distributed nodes (commonlyreferred to as replicas). A replicated database systemimplements either a full replication (every node stores acopy of all data items) or a partial replication (each nodehas a subset of data items). The present invention is con-
cerned with the former.[0119] Database replication is a thoroughly studiedsubject. Two main challenges of database replication areconcurrency control and replica control. The former aimsat isolating transactions with conflicting operations (seeFigure 19), while the latter ensures the consistency ofdata on all replicas (see Figure 20). The need for replicacontrol arises due to the inherent non-determinism in theexecution of transaction operations on different replicas- the data stored on different replicas, which are initiallyconsistent, could diverge because differently orderedmessage sequences are supplied to each replica. Thishappens, for example, as a result of the operating sys-tems, on top of which the replicas are running, schedulingthe transaction operations in different, non-deterministicorder.[0120] Referring now to Figure 19, an example of aconcurrency control mechanism, based on Strict 2-Phase Locking, enforcing Snapshot Isolation on a cen-tralised, non-replicated database, is shown. Three clients(C1, C2 and C3) execute respective transactions (Ti, Tjand Tk) 191a, 191b, 191c to concurrently access the da-tabase. Ti reads data item x, and writes data items y; Tjreads and writes data item z and Tk writes data items yand z and reads data item x. Therefore, the transactionsTi and Tj both conflict with transaction Tk (write-write con-flicts between the Ti and Tk ensue because both trans-actions attempt to write data item y, and similarly betweenTj and Tk due to the concurrent writing of the data itemz). The execution of each transaction proceeds from rightto left, e.g. the first operation in each transaction (therespective begin operations: bi, bj and bk) are depictedin the rightmost positions of the respective clients’queues. Each client sends the operations of the respec-tive transaction to the database, which in turn uses theconcurrency control mechanism to place the operationsin a particular order 192 (one such possibility is shownin the figure).[0121] Transaction Ti is the first to acquire the lock forwriting data item y (the third callout from the right indi-cates that wi(y) is the first modification of the data item yin the database queue). As a result, Tk will be blockedwaiting for the lock on y (indicated by the leftmost callout),and thus once Ticommits, Tk must abort according to the rules of Snap-shot Isolation. As a consequence of Tk aborting, the thirdtransaction, Tj, will end the waiting for the write lock ondata item z (indicated by the second callout from the right)and subsequently commit - once Tk aborts, all its modi-fications arediscarded and the lock on all data items released (includ-ing the lock on the data item z, shown to be initially ac-quired with the rightmost callout), and thus Tj is allowedto make the changes to z and then commit successfully193.[0122] Figure 20 illustrates an example of differenttransaction serialisation decisions made by the concur-rency control mechanisms, based on Strict 2-Phase
31 32

EP 2 470 994 B1
18
5
10
15
20
25
30
35
40
45
50
55
Locking, of two RDBMSs in a replicated database. Threeclients (C1, C2 and C3) execute respective transactions(Ti, Tj and Tk) to concurrently access the database, pro-viding these operations to replica RA 201a, 201b, 201cand to replica RB 202a, 202b, 202c. Ti reads data itemx, and writes data items y; Tj reads and writes data itemz and Tk writes data items y and z and reads data itemx The concurrency control mechanism on replica RAschedules 202a the operations of the three transactionsin a particular order: Ti and Tj are committed, and Tk isaborted 203a (as explained in Figure 19). The order ofoperations execution is scheduled differently 202b onreplica RB, and as a result Tk is the only transaction tocommit since it is the first to acquire the locks for both yand z 203b. To avoid installing inconsistent data on thetwo databases, due to different serialisation order by rep-licas’ concurrency control mechanisms, a replica controlprotocol must be in place.[0123] There are different parameters that can be usedfor classification of database replication protocols [Gray,Helland et al. 1996], [Salas, Jimenez-Peris et al. 2006],such as:
1) the place where the write operations (initially) takeplace;2) the time when the write operations take place;3) the number of messages exchanged; and4) the assumed concurrency control mechanism etc.
[0124] Parameter 1) divides the solutions into primary/secondary and update everywhere approaches. The pri-mary/secondary approach designates only one replicato accept the writes. By contrast, in the update every-where approaches, writes are executed on all (available)replicas. The forwarding of updates to remote replicasincurs an overhead in the primary copy approach whilethe most common challenge in update everywhere rep-lication is conflict resolution.[0125] The second parameter, 2), divides the solutionsinto eager and lazy replication. Eager solutions guaran-tee that the writes are propagated to all replicas beforetransaction commit. This has a negative impact on sys-tem performance, but ensures database consistency ina straightforward way. Lazy solutions perform writes onremote replicas after commit. They offer proved perform-ance at the possible expense of compromising databaseconsistency. If two transactions update different copiesfor the same data item with different values, data becomeinconsistent. The inconsistencies are eventually recon-ciled outside the boundaries of the initial transactions.[0126] Another classification of database replicationprotocols identifies two broad groups: black- box (com-monly referred to as middleware- based), and white- box(commonly referred to as kernel- based) approaches.The protocols of the former group are easier to developand can be maintained independently from the databaseservers they operate on. On the other hand, they are ata disadvantage because no access to the potentially use-
ful concurrency control mechanism of the database serv-er kernel is available. Thus, concurrency/ replica controlmight need to be performed on a coarser level of gran-ularity. In addition, there exist gray- box protocols whichcombine the black- box approaches with a (limited) setof features from database server kernels [Jimenez- Perisand Patino- Martinez 2003], [Patino- Marfinez, Jinenez-Peris et al. 2005] .
ROWAA-Based Replication
[0127] Eager replication protocols have been basedon the read-one/write-all ROWA(A) approach [Bernstein,Hadzilacos et al. 1987]. While read operations are exe-cuted only at one replica (asymmetric reading) in ROWA(A), updates are performed on all (available) replicas.[0128] As suggested in [Kemme 2000] one of the draw-backs of traditional ROWAA solutions is the messageoverhead. If the updates of a transaction are executedimmediately on all replicas, an update message involvesa request and an acknowledgement per each copy ofdata item. Clearly, this will have a significant impact onthe scalability of this approach. It is also the case thataborting a transaction will cost less if the update has beenexecuted only on a single replica than if the updates havebeen immediately propagated to all replicas.[0129] Deferred writing [Bernstein, Hadziacos et al.1987] was proposed as an alternative to immediate writ-ing employed in early versions of eager, update any-where protocols. All the writes are executed on one (local)replica and at the end of a transaction they are bundledtogether in one message and sent to all other (remote)replicas. Deferred writing, however, exhibits an overheadbecause the commitment of each transaction will be de-layed by possible large volume of writes to be executedon the remote replicas in the end of the transaction. Theexecution of writes in the critical path is somewhat min-imised with the use of WriteSets - the modifications todata items made by a transaction on the local replica areextracted and propagated to the remote replicas in a sin-gle message to be applied on each (asymmetric writing),instead of executing full SQL operations. This drawbackdoes not exist when using immediate writing approachwhere processing of the writes happens in parallel on allreplicas.[0130] Another drawback of deferred writing is that de-tection of possible conflicts among transactions is de-layed. While immediate writing might detect conflict dur-ing the execution of transactions, the conflict detectionis performed at the end of transaction executions whendeferred writing is the technique of choice.
Correctness in Replicated Databases
[0131] The strongest correctness criterion for replicat-ed databases is 1-copy serializability (1-copy SR) [Bern-stein, Hadzilacos et al. 1987]. It represents an extensionof the conflict-serializability defined for centralized data-
33 34

EP 2 470 994 B1
19
5
10
15
20
25
30
35
40
45
50
55
bases. The criterion states that a replication protocol en-sures 1-copy SR if for any interleaved execution of trans-actions there is an equivalent serial execution of thosetransactions performed on the logical copy of the data-base, see Figure 21. More specifically, Figure 21 is aschematic block diagram representing the interaction be-tween clients 211 and replicated DBs 213a..n. The rep-licated databases appear to clients as one logical entity213.[0132] Lin et al. [Lin, Kemme et al. 2005] defined cri-teria for correctness of replicated databases when eachof the underlying replicas offers snapshot isolation. Thecorrectness criterion, referred to as 1- copy snapshot iso-lation (1- copy- SI) , guarantees that an execution oftransactions over a set of replicas produces a globalschedule that is equivalent to a schedule produced by acentralised database system which offers snapshot iso-lation.[0133] Similarly to 1-copy-SI, Elnikety et al. [Elnikety,Zwaenepoel et al. 2005] defined Generalised SnapshotIsolation (GSI) - a correctness criterion for replicated da-tabases that offer snapshot isolation. GSI is an extensionto the snapshot isolation as found in centralized databas-es. The authors formalize the "centralized" snapshot iso-lation and refer to it as Conventional Snapshot Isolation(CSI).[0134] The DivRep protocol of the present inventionassumes that underlying databases offer snapshot iso-lation and thus the latter two correctness criteria, 1-copySI and GSI, apply to the present invention.
Conflicts and Deadlocks
[0135] Earlier sections indicated how conflicts be-tween concurrent transactions can ensue. Certain data-base replication solutions are prone to a specific conflictsituation - distributed deadlock. This happens if the lockfor a data item is acquired in different order on differentreplicas. Figure 22 shows two concurrent transactionsT1 and T2, which are competing for data item A, whileexecuting in a replicated database system with two rep-licas Rx and Ry. The order of lock requests by T1 and T2is different on the two replicas, i.e. T2 is blocked 224waiting for T1 on Rx and vice versa is true on Ry. As aresult, in the replication schemes where a transactioncommits only after all the replicas are ready to do so,the transactions would be deadlocked without possibilityto progress further, unless a dedicated deadlock detec-tion mechanism of the distributed database protocol is inplace to resolve the conflict.[0136] It has been suggested that group communica-tion systems (GCS) [Hadzilacos and Toueg 1993] beused as a means of reducing conflicts and avoiding dead-locks as well as ensuring consistent data on multiple rep-licas. A GCS makes it possible for any replica to send amessage to all other replicas (including itself) with theguarantee that the message will be delivered if no failuresoccur. These systems are capable of ensuring that a
message multicast in a group will be delivered in thesame, system-wide total order on all group members, i.e.database replicas. This holds for the sender of the mes-sage too. Many replication protocols, e.g., [Agrawal,Alonso et al. 1997], [Kemme and Alonso 2000] combinegroup communication primitives with an asymmetricwrites technique, in which, usually, the write operationsof a transaction are executed on one replica, grouped inone message (WriteSet) and delivered to all the replicasin the same total order, see Figure 23. The installationof the WriteSets in the same total order is necessary toavoid data inconsistencies due to non-determinism of thereplicas. Otherwise, if the total order was not respectedit would be possible that two replicas install overlappingWriteSets in a different order, which would result in aninconsistent state of the replicated system.[0137] Referring to Figure 23 in greater detail, a high-level schematic representation of a Group Communica-tion System (GCS) 231 used for consistent database rep-lication is shown. Figure 23 shows three concurrent,modifying transactions, Tk, Ti and Tj, are being executedon the three replicas, Rx, Ry, Rz, respectively. Each trans-action execution comprises the following: transaction op-erations, reads and writes, are executed on the local rep-lica (not shown in the figure); the results of the write op-erations are extracted in a WriteSet (WS) and sent 232i,232j, 232k to the underlying GCS 231; the GCS delivers233 the WriteSets in the consistent, total order on all rep-licas. The total order is not necessarily the same as theorder in which the WriteSets are received by the GCS.
Transaction Atomicity
[0138] In replicated databases atomicity of a transac-tion has to be guaranteed - it is necessary to make surethat all replicas terminate the transaction in the sameway, i.e. all replicas either commit or abort a transaction.As described in [Weismann, Pedone et al. 2000] thereare two techniques to ensure transaction atomicity in areplicated database system: voting and non-voting tech-nique. Voting techniques, traditionally, use atomic com-mitment protocols to terminate transactions. A well-known variant of the atomic commitment protocol is the2-Phase Commit (2PC) protocol [Skeen 1981]. The phas-es of a 2PC protocol could be summarised as follows:
- A coordinator sends a request to each replica for avote (to commit or abort).
- Upon receiving the request each replica replies witha message, YES (commit) or NO (abort). If the voteis NO the replica aborts the execution.
- Upon collecting all the votes, the coordinator decideson the outcome of the transaction:
o If all replicas have voted YES, the coordinatornotifies the replicas to commit.
35 36

EP 2 470 994 B1
20
5
10
15
20
25
30
35
40
45
50
55
o If a replica voted NO, the coordinator notifiesthe replicas to abort.
- Upon receiving the notification (commit or abort)from the coordinator, a replica decides accordingly.
References
[0139]
[Adya, A., B. Liskov, et al. 2000] "Generalized Snap-shot Isolation Levels". IEEE International Confer-ence on Data Engineering (ICDE) San Diego, CA.[Agrawal, D., G. Alonso, et al. 1997] "ExploitingAtomic Broadcast in Replicated Databases". In Pro-ceedings of EuroPar (EuroPar’97), Passau (Germa-ny) .[ANSI 1992] "ANSI X3.135-1992", American Nation-al Standard for Information Systems.[Berenson, H., P. Bernstein, et al. 1995] "A Critiqueof ANSI SQL Isolation Levels". SIGMOD internation-al Conference on Management of Data, San Jose,California, United States, ACM Press New York, NY,USA.[Bernstein, A., V. Hadzilacos, et al. 1987] "Concur-rency Control and Recovery in Database Systems".Reading, Mass., Addison-Wesley.[Elnikety, S., W. Zwaenepoel, et al. 2005] "DatabaseReplication Using Generalized Snapshot Isolation".Proceedings of the 24th IEEE Symposium on Reli-able Distributed Systems (SRDS’05), IEEE Compu-ter Society, pages 73- 84.[Fekete, A., E. O’Neil, et al. 2004] "A read-only trans-action anomaly under snapshot isolation" ACM SIG-MOD Record 33(3): 12-14.[Gashi, I. and P. Popov 2006] "Rephrasing Rules forOff-the-Shelf SQL Database Servers". Sixth Euro-pean Dependable Computing Conference, 2006.EDCC ’06..[Gashi, I., P. Popov, et al. 2007] "Fault tolerance viadiversity for off-the-shelf products: a study with SQLdatabase server" IEEE Transactions on Dependableand Secure Computing.[Gray, J. 1981] "The Transaction Concept: Virtuesand Limitations". 7th International Conference onVery Large Data Bases (VLDB), Cannes, France,IEEE Computer Society.[Gray, J., R. Lorie, et al. 1975] "Granularity of locksand degrees of consistency in a shared data base"."IFIP Working Conference on Modelling of DataBase Management Systems". Freudenstadt.[Gray, J. and A. Reuter 1993] "Transactionprocessing : concepts and techniques", MorganKaufmann.[Hadzilacos, V. and S. Toueg 1993] "Fault-tolerantbroadcast and related problems". Distributed Sys-tems. S. Mullander, Addison-Wesley: 97-145.[Jimenez- Peris, R. and M. Patino- Martinez 2003]
"D5: Transaction Support", ADAPT MiddlewareTechnologies for Adaptive and Composable Distrib-uted Components: 20.[Kemme, B. 2000] "Database Replication fo Clustersof Workstations". "Swiss Federal Institute of Tech-nology". Zurich: 145.[Kemme, B. and G. Alonso 2000] "Don’t be lazy, beconsistent: Postgres-R, a new way to implement Da-tabase Replication". Int. Conf. on Very Large Data-bases (VLDB), Cairo, Egypt.[Kemme, B. and S. Wu 2005] "Postgres- R (SI) :Combining Replica Control with Concurrency Con-trol based on Snapshot Isolation". International Con-ference on Data Engineering, Tokyo, Japan, IEEEComputer Society.[Lamport, L., R. Shostak, et al. 1982] "The ByzantineGenerals Problem" ACM Transactions on Program-ming Language and Systems (TOPLAS) 4(3):382-401.[Lin, Y., B. Kemme, et al. 2005] "Middleware BasedData Replication Providing Snapshot Isolation".ACM SIGMOD International Conference on Man-agement of Data, Baltimore, Maryland, ACM Press.[Mullender, S. 1993] "Distributed Systems". NewYork, USA, ACM Press/Addison-Wesley PublishingCo.[Patino- Martinez, M., R. Jimenez- Peris, et al. 2005]"MIDDLE- R: Consistent database replication at themiddleware level" ACM Transactions on ComputerSystems (TOCS) 23 (4) : 375- 423.[Preguiça, N., R. Rodrigues, et al. 2008] "Byzantium:Byzantine-Fault-Tolerant Database Replication Pro-viding Snapshot Isolation". Fourth Workshop on HotTopics in System Dependability.[Skeen, D. 1981] "Nonblocking commit protocols".Proceedings of ACM SIGMOD International confer-ence on management of data, Ann Arbor, Michigan,ACM Press, New York, NY, USA.[Vandiver, B. 2008] "Detecting and Tolerating Byz-antine Faults in Database Systems". "ProgrammingMethodology Group". Boston, Massachusetts Insti-tute of Technology. PhD: 176.[Weismann, M., F. Pedone, et al. 2000] "DatabaseReplication Techniques: a Three Parameter Classi-fication". 19th IEEE Symposium on Reliable Distrib-uted Systems (SRDS’00), Numberg, Germany,IEEE.
Claims
1. A fault-tolerant node for synchronous heterogenousdatabase replication whereby the fault-tolerant node(50) is adapted to carry out a series of databasetransactions generated by a processor executing acomputer program at the fault-tolerant node (50),wherein the fault-tolerant node (50) comprises atleast two relational database management systems
37 38

EP 2 470 994 B1
21
5
10
15
20
25
30
35
40
45
50
55
(51, 52), the systems being instances of different re-lational database management system productswhich provide snapshot isolation between concur-rent transactions and each system (51, 52) compris-ing a database and a database management com-ponent, wherein for each database transaction, op-eration instructions are provided concurrently toeach of the systems to carry out operations on theirrespective databases and to provide respective re-sponses;wherein the responses generated by the systemseither comprise an operation result or an exception,and where only one of the systems is configured witha NOWAIT exception function enabled which returnsan exception when it is detected that two or moreconcurrent transactions are attempting to modify thesame data item and the other systems are configuredwith the NOWAIT exception function disabled,whereby the fault-tolerant node (50) is adapted todetect that two or more concurrent transactions areattempting to modify the same data item and to blockone or more of the transactions to ensure that allsystems apply the same order of modification of thedata item by the concurrent transactions.
2. A fault-tolerant node as claimed in claim 1, whereina set of operation instructions includes a begin in-struction, a commit instruction and an abort instruc-tion for control of execution of a transaction and fur-ther comprises a read operation and a write opera-tion, and wherein in executing a write operation thenode first extracts a write set on which operationsare performed before the transaction is committedand wherein the fault-tolerant node treats a failureto provide an operation result to a read operation ora write operation within a predetermined time as anexception.
3. A fault-tolerant node as claimed in claim 1 or claim2, wherein the fault-tolerant node (50) comprises atransaction manager (63) to control the execution ofthe operations for one transaction in each of the sys-tems and a replica manager (64, 65) for each of thesystems used to execute a transaction to provideoperations to its associated system, wherein for eachtransaction, the transaction manager (63) providesoperations required for execution of the transactioninto a queue for each system managed by the replicamanager (64, 65) for that system, wherein the oper-ations are provided to each system from the queueby the replica manager for that system.
4. A fault-tolerant node as claimed in any precedingclaim, wherein the fault-tolerant node (50) comprisesa comparator function to compare operation resultsreceived from the systems to enable the fault-toler-ant node to determine whether the transaction hascompleted successfully.
5. A fault-tolerant node as claimed in claim 4 whereina set of operation instructions includes a begin in-structions, a commit instruction and an abort instruc-tion for control of execution of a transaction andwherein only one transaction can execute a begininstructions or a commit instruction at a time for allthe systems , whereby on mismatch between the op-eration results received from the systems the fault-tolerant node (50) raises an exception to abort thetransaction.
6. A fault-tolerant node as claimed in any precedingclaim, wherein either the fault-tolerant node returnsthe first operation result received from any of thesystems to the computer program, and provides afurther message to the computer program if thetransaction aborts, or the fault tolerant node returnsan operation result to the computer program onlywhen the operation results from all the systems havebeen received and evaluated by the fault tolerantnode.
7. A database server comprising a fault tolerant nodeas claimed in any of claims 1 to 6.
8. A method for performing a synchronous heteroge-nous database replication, for a series of databasetransactions provided by a processor executing acomputer program, at a fault-tolerant node (50) com-prising at least two relational database managementsystems (51, 52), the systems being instances ofdifferent relational database management systemproducts which provide snapshot isolation with eachsystem comprising a database and a database man-agement component, the method comprising:
receiving a database transaction at the fault-tol-erant node (50);providing operation instructions for the databasetransaction concurrently to each of the systems(51, 52) to carry out operations on their respec-tive databases and to provide respective re-sponses;the systems each generating a response to anoperation instruction which comprises an oper-ation result or an exception, wherein only oneof the systems is configured with a NOWAIT ex-ception function enabled such that that systemreturns an exception when it is detected that twoor more concurrent transactions are attemptingto modify the same data item and the other sys-tems are configured with the NOWAIT exceptionfunction disabled;whereby the fault-tolerant node (50) detects thattwo or more concurrent transactions are at-tempting to modify the same data item and al-lows the transactions that accesses the dataitem first on the system with NOWAIT enabled
39 40

EP 2 470 994 B1
22
5
10
15
20
25
30
35
40
45
50
55
to proceed on all the systems, and prevents ex-ecution of all the other transactions attemptingto modify the same data item on all the systems,thereby achieving that all systems apply thesame order of modification of the data item bythe concurrent transactions.
9. A method as claimed in claim 8, wherein a set ofoperation instructions includes a begin instruction, acommit instruction and an abort instruction for controlof execution of a transaction and wherein only onetransaction can execute a begin instruction or a com-mit instruction at a time for all the systems.
10. A method as claimed in claim 9, wherein when anexception is received as an operation result from oneof the systems, the fault-tolerant node (50) providesan abort instruction for that transaction for all thesystems.
11. A method as claimed in claim 9 or claim 10, whereinexecution of a commit operation for a transactioncomprises determining whether the transaction hasbeen aborted, determining that the operation resultsfrom the systems allow a transaction result to be pro-vided, and by acquiring control of commit and beginoperations so that no other begin or commit opera-tion can take place until the begin operation is com-pleted and wherein execution of a begin operationfor a transaction comprises setting a variable indi-cating that the transaction is not aborted, and by ac-quiring control of commit and begin operations sothat no other begin or commit operation can takeplace until the begin operation is completed.
12. A method as claimed in any of claims 9 to 11, whereinthe set of operations comprises a read operation anda write operation, and wherein in executing a writeoperation the node first extracts a write set on whichoperations are performed before the transaction iscommitted.
13. A method as claimed in claim 12, wherein the fault-tolerant node treats a failure to provide an operationresult to a read operation or a write operation withina predetermined time as an exception.
14. A method as claimed in any of claims 8 to 13, furthercomprising comparing operation results receivedfrom the systems to enable the fault-tolerant nodeto determine whether the transaction has completedsuccessfully and further comprising aborting thetransaction if the step of comparing operation resultsindicates a mismatch between operation results re-ceived from different systems.
15. A method as claimed in any of claims 8 to 14, furthercomprising either returning the first operation result
received from any of the systems to the computerprogram, and providing a further message to thecomputer program if the transaction aborts or return-ing an operation result to the computer program onlywhen the operation results from all the systems havebeen received and evaluated by the fault tolerantnode (50).
Patentansprüche
1. Fehlertoleranter Knoten für synchrone heterogeneDatenbankreplikation, wodurch der fehlertoleranteKnoten (50) angepasst ist, um eine Reihe von Da-tenbanktransaktionen, die von einem ein Computer-programm ausführenden Prozessor erzeugt wer-den, am fehlertoleranten Knoten (50) durchzufüh-ren, wobei der fehlertolerante Knoten (50) minde-stens zwei Verwaltungssysteme für relationale Da-tenbanken (51, 52) umfasst, wobei die Systeme In-stanzen unterschiedlicher Produkte von Verwal-tungssystemen für relationale Datenbanken sind,die Snapshot-Isolation zwischen gleichzeitigenTransaktionen bereitstellen, und jedes System (51,52) eine Datenbank und eine Datenbankverwal-tungskomponente umfasst, wobei für jede Daten-banktransaktion Vorgangsbefehle für jedes der Sy-steme gleichzeitig bereitgestellt werden, um Vorgän-ge in ihren jeweiligen Datenbanken durchzuführenund jeweilige Antworten bereitzustellen; wobei diedurch die Systeme erzeugten Antworten entwederein Vorgangsergebnis oder eine Ausnahme umfas-sen, und wobei nur eines der Systeme mit einer ak-tivierten NOWAIT-Ausnahmefunktion konfiguriertist, die eine Ausnahme zurückgibt, wenn erkanntwird, dass zwei oder mehr gleichzeitige Transaktio-nen gerade versuchen, dasselbe Datenelement zumodifizieren, und die anderen Systeme mit der de-aktivierten NOWAIT-Ausnahmefunktion konfiguriertsind, wodurch der fehlertolerante Knoten (50) ange-passt ist, um zu erkennen, dass zwei oder mehrgleichzeitige Transaktionen gerade versuchen, das-selbe Datenelement zu modifizieren und eine odermehr der Transaktionen zu blockieren, um sicherzu-stellen, dass alle Systeme dieselbe Reihenfolge derModifikation des Datenelements durch die gleichzei-tigen Transaktionen anwenden.
2. Fehlertoleranter Knoten nach Anspruch 1, wobei einSatz von Vorgangsbefehlen einen Begin-Befehl, ei-nen Commit-Befehl und einen Abort-Befehl zurSteuerung der Ausführung einer Transaktion enthältund ferner einen Lesevorgang und einen Schreib-vorgang umfasst, und wobei der Knoten beim Aus-führen eines Schreibvorgangs zuerst ein Write-Setextrahiert, gemäß dem Vorgänge umgesetzt wer-den, bevor für die Transaktion ein Commit ausge-führt wird, und wobei der fehlertolerante Knoten eine
41 42

EP 2 470 994 B1
23
5
10
15
20
25
30
35
40
45
50
55
Nichtbereitstellung eines Vorgangsergebnisses füreinen Lesevorgang oder einen Schreibvorgang in-nerhalb eines vorbestimmten Zeitraums als Ausnah-me behandelt.
3. Fehlertoleranter Knoten nach Anspruch 1 oder An-spruch 2, wobei der fehlertolerante Knoten (50) ei-nen Transaktionsverwalter (63) zum Steuern derAusführung der Vorgänge für eine Transaktion in je-dem der Systeme und einen Replikatverwalter (64,65) für jedes der Systeme umfasst, die genutzt wer-den, um eine Transaktion auszuführen, um Vorgän-ge für ihr assoziiertes System bereitzustellen, wobeider Transaktionsverwalter (63) für jede TransaktionVorgänge, die zur Ausführung der Transaktion er-forderlich sind, in eine Warteschlange für jedes Sy-stem, die vom Replikatverwalter (64, 65) für diesesSystem verwaltet wird, bereitstellt, wobei die Vor-gänge für jedes System aus der Warteschlangedurch den Replikatverwalter für dieses System be-reitgestellt werden.
4. Fehlertoleranter Knoten nach einem vorhergehen-den Anspruch, wobei der fehlertolerante Knoten (50)eine Vergleicherfunktion umfasst, um von den Sy-stemen her empfangene Vorgangsergebnisse zuvergleichen, um zu ermöglichen, dass der fehlerto-lerante Knoten bestimmt, ob die Transaktion erfolg-reich abgeschlossen wurde.
5. Fehlertoleranter Knoten nach Anspruch 4, wobei einSatz von Vorgangsbefehlen einen Begin-Befehl, ei-nen Commit-Befehl und einen Abort-Befehl zurSteuerung der Ausführung einer Transaktion enthältund wobei jeweils nur eine Transaktion einen Begin-Befehl oder einen Commit-Befehl für alle Systemeausführen kann, wodurch der fehlertolerante Knoten(50) bei einer Nichtübereinstimmung zwischen denvon den Systemen her empfangenen Vorgangser-gebnissen eine Ausnahme auslöst, um die Transak-tion abzubrechen.
6. Fehlertoleranter Knoten nach einem vorhergehen-den Anspruch, wobei entweder der fehlertoleranteKnoten das von einem beliebigen der Systeme herempfangene erste Vorgangsergebnis an das Com-puterprogramm zurückgibt und für das Computer-programm eine weitere Nachricht bereitstellt, fallsdie Transaktion abgebrochen wird, oder der fehler-tolerante Knoten ein Vorgangsergebnis an das Com-puterprogramm nurzurückgibt, wenn die Vorgangs-ergebnisse von allen Systemen her durch den feh-lertoleranten Knoten empfangen und bewertet wur-den.
7. Datenbankserver, der einen fehlertoleranten Knotennach einem der Ansprüche 1 bis 6 umfasst.
8. Verfahren zum Umsetzen einer synchronen hetero-genen Datenbankreplikation, für eine Reihe von Da-tenbanktransaktionen, die von einem ein Computer-programm ausführenden Prozessor bereitgestelltwerden, an einem fehlertoleranten Knoten (50), dermindestens zwei Verwaltungssysteme für relationa-le Datenbanken (51, 52) umfasst, wobei die SystemeInstanzen unterschiedlicher Produkte von Verwal-tungssystemen für relationale Datenbanken sind,die Snapshot-Isolation bereitstellen, wobei jedes Sy-stem eine Datenbank und eine Datenbankverwal-tungskomponente umfasst, wobei das VerfahrenFolgendes umfasst:
Empfangen einer Datenbanktransaktion amfehlertoleranten Knoten (50);gleichzeitiges Bereitstellen von Vorgangsbefeh-len für die Datenbanktransaktion für jedes derSysteme (51, 52), um Vorgänge in ihren jewei-ligen Datenbanken durchzuführen und jeweiligeAntworten bereitzustellen;wobei die Systeme je eine Antwort auf einenVorgangsbefehl erzeugen, die ein Vorgangser-gebnis oder eine Ausnahme umfasst, wobei nureines der Systeme mit einer aktivierten NO-WAIT-Ausnahmefunktion konfiguriert ist, so-dass das System eine Ausnahme zurückgibt,wenn erkannt wird, dass zwei oder mehr gleich-zeitige Transaktionen gerade versuchen, das-selbe Datenelement zu modifizieren, und die an-deren Systeme mit der deaktivierten NOWAIT-Ausnahmefunktion konfiguriert sind;wodurch der fehlertolerante Knoten (50) er-kennt, dass zwei oder mehr gleichzeitige Trans-aktionen gerade versuchen, dasselbe Daten-element zu modifizieren, und zulässt, dass dieTransaktionen, die auf das Datenelement im Sy-stem zuerst zugreifen, wenn NOWAIT aktiviertist, in allen Systemen fortfahren, und die Aus-führung aller anderen Transaktionen verhindert,die gerade versuchen, dasselbe Datenelementin allen Systemen zu modifizieren, wodurch er-reicht wird, dass alle Systeme dieselbe Reihen-folge der Modifikation des Datenelements durchdie gleichzeitigen Transaktionen anwenden.
9. Verfahren nach Anspruch 8, wobei ein Satz von Vor-gangsbefehlen einen Begin-Befehl, einen Commit-Befehl und einen Abort-Befehl zur Steuerung derAusführung einer Transaktion enthält und wobei je-weils nur eine Transaktion einen Begin-Befehl odereinen Commit-Befehl für alle Systeme ausführenkann.
10. Verfahren nach Anspruch 9, wobei, wenn von einemder Systeme her eine Ausnahme als Vorgangser-gebnis empfangen wird, der fehlertolerante Knoten(50) einen Abort-Befehl für diese Transaktion für alle
43 44

EP 2 470 994 B1
24
5
10
15
20
25
30
35
40
45
50
55
Systeme bereitstellt.
11. Verfahren nach Anspruch 9 oder Anspruch 10, wobeidie Ausführung eines Commit-Vorgangs für eineTransaktion Bestimmen umfasst, ob die Transaktionabgebrochen wurde, Bestimmen, dass die Vor-gangsergebnisse von den Systemen her zulassen,dass ein Transaktionsergebnis bereitgestellt wird,und durch Übernehmen der Steuerung von Commit-und Begin-Vorgängen, sodass kein anderer Begin-oder Commit-Vorgang erfolgen kann, bis der Begin-Vorgang abgeschlossen ist, und wobei die Ausfüh-rung eines Begin-Vorgangs für eine Transaktion Set-zen einer Variable umfasst, die anzeigt, dass dieTransaktion nicht abgebrochen ist, und durch Über-nehmen der Steuerung von Commit- und Begin-Vor-gängen, sodass kein anderer Begin- oder Commit-Vorgang erfolgen kann, bis der Begin-Vorgang ab-geschlossen ist.
12. Verfahren nach einem der Ansprüche 9 bis 11, wobeider Satz von Vorgängen einen Lesevorgang und ei-nen Schreibvorgang umfasst, und wobei der Knotenbeim Ausführen eines Schreibvorgangs zuerst einWrite-Set extrahiert, gemäß dem Vorgänge umge-setzt werden, bevor für die Transaktion ein Commitausgeführt wird.
13. Verfahren nach Anspruch 12, wobei der fehlertole-rante Knoten eine Nichtbereitstellung eines Vor-gangsergebnisses für einen Lesevorgang oder ei-nen Schreibvorgang innerhalb eines vorbestimmtenZeitraums als Ausnahme behandelt.
14. Verfahren nach einem der Ansprüche 8 bis 13, dasferner Vergleichen von von den Systemen her emp-fangenen Vorgangsergebnissen umfasst, um zu er-möglichen, dass der fehlertolerante Knoten be-stimmt, ob die Transaktion erfolgreich abgeschlos-sen wurde, und das ferner Abbrechen der Transak-tion umfasst, falls der Schritt des Vergleichens vonVorgangsergebnissen eine Nichtübereinstimmungzwischen von unterschiedlichen Systemen her emp-fangenen Vorgangsergebnissen anzeigt.
15. Verfahren nach einem der Ansprüche 8 bis 14, dasferner entweder Zurückgeben des von einem belie-bigen der Systeme her empfangenen ersten Vor-gangsergebnisses an das Computerprogramm undBereitstellen einer weiteren Nachricht für das Com-puterprogramm, falls die Transaktion abgebrochenwird, oder Zurückgeben eines Vorgangsergebnis-ses an das Computerprogramm nur, wenn die Vor-gangsergebnisse von allen Systemen her durch denfehlertoleranten Knoten (50) empfangen und bewer-tet wurden, umfasst.
Revendications
1. Noeud tolérant les défaillances pour réplication debase de données hétérogène synchrone où le noeudtolérant les défaillances (50) est adapté pour réaliserune série de transactions de base de données gé-nérée par un processeur exécutant un programmeinformatique au niveau du noeud tolérant les dé-faillances (50), dans lequel le noeud tolérant les dé-faillances (50) comprend au moins deux systèmesde gestion de base de données relationnelle (51,52), les systèmes étant des exemples de différentsproduits de système de gestion de base de donnéesrelationnelle qui fournissent un isolement instantanéentre des transactions simultanées et chaque sys-tème (51, 52) comprenant une base de données etune composante de gestion de base de données,dans lequel pour chaque transaction de base de don-nées, des instructions d’opération sont fournies si-multanément à chacun des systèmes pour réaliserdes opérations sur leur base de données respectiveet pour fournir des réponses respectives ;dans lequel les réponses générées par les systèmescomprennent soit un résultat d’opération, soit uneexception, et où seul l’un des systèmes est configuréavec une fonction d’exception NOWAIT (PAS D’AT-TENTE) activée qui renvoie une exception lors de ladétection que deux transactions simultanées ou plustentent de modifier la même donnée et les autressystèmes sont configurés avec la fonction d’excep-tion NOWAIT désactivée, moyennant quoi le noeudtolérant les défaillances (50) est adapté pour détec-ter que deux transactions simultanées ou plus ten-tent de modifier la même donnée et pour bloquerune ou plusieurs des transactions afin de garantirque tous les systèmes appliquent le même ordre demodification de la donnée par les transactions simul-tanées.
2. Noeud tolérant les défaillances selon la revendica-tion 1, dans lequel un ensemble d’instructions d’opé-ration comprend une instruction de démarrage, uneinstruction d’archivage et une instruction d’abandonafin de commander l’exécution d’une transaction etcomprend en outre une opération de lecture et uneopération d’écriture, et dans lequel lors d’une exé-cution d’une opération d’écriture, le noeud extraitd’abord un ensemble d’écriture sur lequel des opé-rations sont réalisées avant que la transaction nesoit archivée et dans lequel le noeud tolérant les dé-faillances traite un échec de la fourniture d’un résul-tat d’opération à une opération de lecture ou uneopération d’écriture dans une période prédétermi-née en tant qu’exception.
3. Noeud tolérant les défaillances selon la revendica-tion 1 ou la revendication 2, dans lequel le noeudtolérant les défaillances (50) comprend un gestion-
45 46

EP 2 470 994 B1
25
5
10
15
20
25
30
35
40
45
50
55
naire de transactions (63) afin de commander l’exé-cution des opérations pour une transaction danschacun des systèmes et un gestionnaire de réplique(64, 65) pour chacun des systèmes utilisés pour exé-cuter une transaction afin de fournir des opérationsà son système associé, dans lequel pour chaquetransaction, le gestionnaire de transactions (63)fournit les opérations nécessaires à l’exécution dela transaction dans une file d’attente pour chaquesystème géré par le gestionnaire de réplique (64,65) pour ce système, dans lequel les opérations sontfournies à chaque système à partir de la file d’attentepar le gestionnaire de réplique pour ce système.
4. Noeud tolérant les défaillances selon l’une quelcon-que des revendications précédentes, dans lequel lenoeud tolérant les défaillances (50) comprend unefonction de comparateur afin de comparer les résul-tats d’opération reçus en provenance des systèmesafin de permettre au noeud tolérant les défaillancesde déterminer si la transaction s’est terminée avecsuccès.
5. Noeud tolérant les défaillances selon la revendica-tion 4, dans lequel un ensemble d’instructions d’opé-ration comprend une instruction de démarrage, uneinstruction d’archivage et une instruction d’abandonafin de commander l’exécution d’une transaction etdans lequel seule une transaction peut exécuter uneinstruction de démarrage ou une instruction d’archi-vage à la fois pour tous les systèmes, moyennantquoi lors d’un défaut de correspondance entre lesrésultats d’opération reçus en provenance des sys-tèmes, le noeud tolérant les défaillances (50) déclen-che une exception afin d’abandonner la transaction.
6. Noeud tolérant les défaillances selon l’une quelcon-que des revendications précédentes, dans lequelsoit le noeud tolérant les défaillances renvoie le pre-mier résultat d’opération reçu en provenance de l’unquelconque des systèmes au programme informati-que, et fournit un message supplémentaire au pro-gramme informatique si la transaction est abandon-née, soit le noeud tolérant les défaillances renvoieun résultat d’opération au programme informatiqueuniquement lorsque les résultats d’opération en pro-venance de tous les systèmes ont été reçus et ana-lysés par le noeud tolérant les défaillances.
7. Serveur de base de données comprenant un noeudtolérant les défaillances selon l’une quelconque desrevendications 1 à 6.
8. Procédé de réalisation d’une réplication de base dedonnées hétérogène synchrone, pour une série detransactions de base de données fournie par un pro-cesseur exécutant un programme informatique, auniveau d’un noeud tolérant les défaillances (50) com-
prenant au moins deux systèmes de gestion de basede données relationnelle (51, 52), les systèmes étantdes exemples de différents produits de système degestion de base de données relationnelle qui four-nissent un isolement instantané, chaque systèmecomprenant une base de données et une compo-sante de gestion de base de données, le procédécomprenant :
la réception d’une transaction de base de don-nées au niveau du noeud tolérant les défaillan-ces (50) ;la fourniture d’instructions d’opération pour latransaction de base de données simultanémentà chacun des systèmes (51, 52) pour réaliserdes opérations sur leurs bases de données res-pectives et fournir des réponses respectives ;les systèmes générant chacun une réponse àune instruction d’opération qui comprend un ré-sultat d’opération ou une exception, où seul undes systèmes est configuré avec une fonctiond’exception NOWAIT activée de sorte que lesystème renvoie une exception lors de la détec-tion que deux transactions simultanées ou plustentent de modifier la même donnée et les autressystèmes sont configurés avec la fonction d’ex-ception NOWAIT désactivée ;moyennant quoi le noeud tolérant les défaillan-ces (50) détecte que deux transactions simulta-nées ou plus tentent de modifier la même don-née et permet aux transactions qui accèdent àla donnée en premier sur le système avec lafonction NOWAIT activée de continuer sur tousles systèmes, et empêche l’exécution de toutesles autres transactions tentant de modifier la mê-me donnée sur tous les systèmes, permettantainsi l’application par tous les systèmes du mê-me ordre de modification de la donnée par lestransactions simultanées.
9. Procédé selon la revendication 8, dans lequel un en-semble d’instructions d’opération comprend une ins-truction de démarrage, une instruction d’archivageet une instruction d’abandon afin de commanderl’exécution d’une transaction et dans lequel seuleune transaction peut exécuter une transaction de dé-marrage ou une transaction d’archivage à la fois pourtous les systèmes.
10. Procédé selon la revendication 9, dans lequel lors-qu’une exception est reçue en tant que résultatd’opération en provenance de l’un des systèmes, lenoeud tolérant les défaillances (50) fournit une ins-truction d’abandon pour cette transaction pour tousles systèmes.
11. Procédé selon la revendication 9 ou 10, dans lequell’exécution d’une opération d’archivage pour une
47 48

EP 2 470 994 B1
26
5
10
15
20
25
30
35
40
45
50
55
transaction comprend le fait de déterminer si la tran-saction a été abandonnée, de déterminer que lesrésultats d’opération en provenance des systèmespermettent de fournir un résultat de transaction, etd’acquérir une commande des opérations d’archiva-ge et de démarrage de sorte qu’aucune autre opé-ration d’archivage ou de démarrage ne peut avoirlieu jusqu’à ce que l’opération de démarrage soit ter-minée et dans lequel l’exécution d’une opération dedémarrage pour une transaction comprend l’établis-sement d’une variable indiquant que la transactionn’est pas abandonnée, et d’acquérir la commandedes opérations de démarrage et d’archivage de sortequ’aucune autre opération de démarrage ou d’archi-vage ne peut avoir lieu jusqu’à ce que l’opération dedémarrage soit terminée.
12. Procédé selon l’une quelconque des revendications9 à 11, dans lequel l’ensemble d’opérations com-prend une opération de lecture et une opérationd’écriture, et dans lequel lors de l’exécution d’uneopération d’écriture, le noeud extrait d’abord un en-semble d’écriture sur lequel des opérations sont réa-lisées avant que la transaction ne soit archivée.
13. Procédé selon la revendication 12, dans lequel lenoeud tolérant les défaillances traite un échec de lafourniture d’un résultat d’opération à une opérationde lecture ou une opération d’écriture dans une pé-riode prédéterminée en tant qu’exception.
14. Procédé selon l’une quelconque des revendications8 à 13, comprenant en outre la comparaison de ré-sultats d’opération reçus en provenance des systè-mes afin de permettre au noeud tolérant les dé-faillances de déterminer si la transaction s’est termi-née avec succès et comprenant en outre l’abandonde la transaction si l’étape de comparaison des ré-sultats d’opération indique un défaut de correspon-dance entre les résultats d’opération reçus en pro-venance des différents systèmes.
15. Procédé selon l’une quelconque des revendications8 à 14, comprenant en outre soit le renvoi du premierrésultat d’opération en provenance de l’un quelcon-que des systèmes au programme informatique, etla fourniture d’un message supplémentaire au pro-gramme informatique si la transaction est abandon-née, soit le renvoi d’un résultat d’opération au pro-gramme informatique uniquement lorsque les résul-tats d’opération en provenance de tous les systèmesont été reçus et analysés par le noeud tolérant lesdéfaillances (50).
49 50
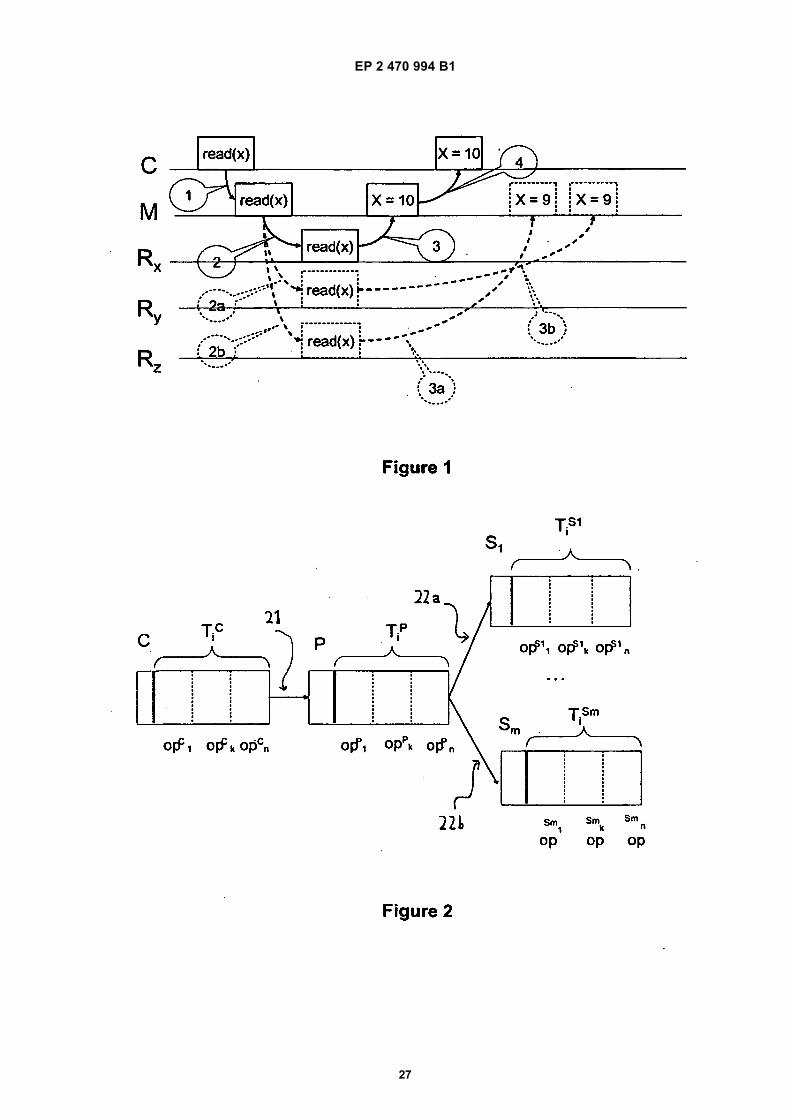
EP 2 470 994 B1
27
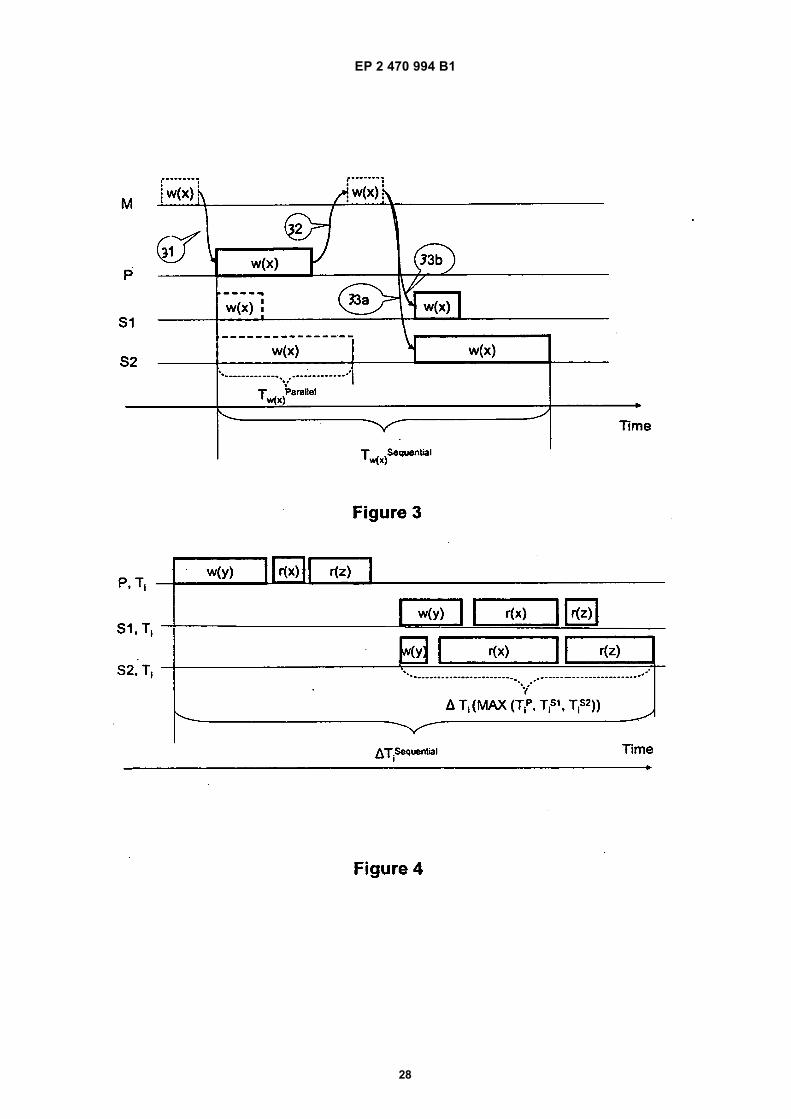
EP 2 470 994 B1
28

EP 2 470 994 B1
29
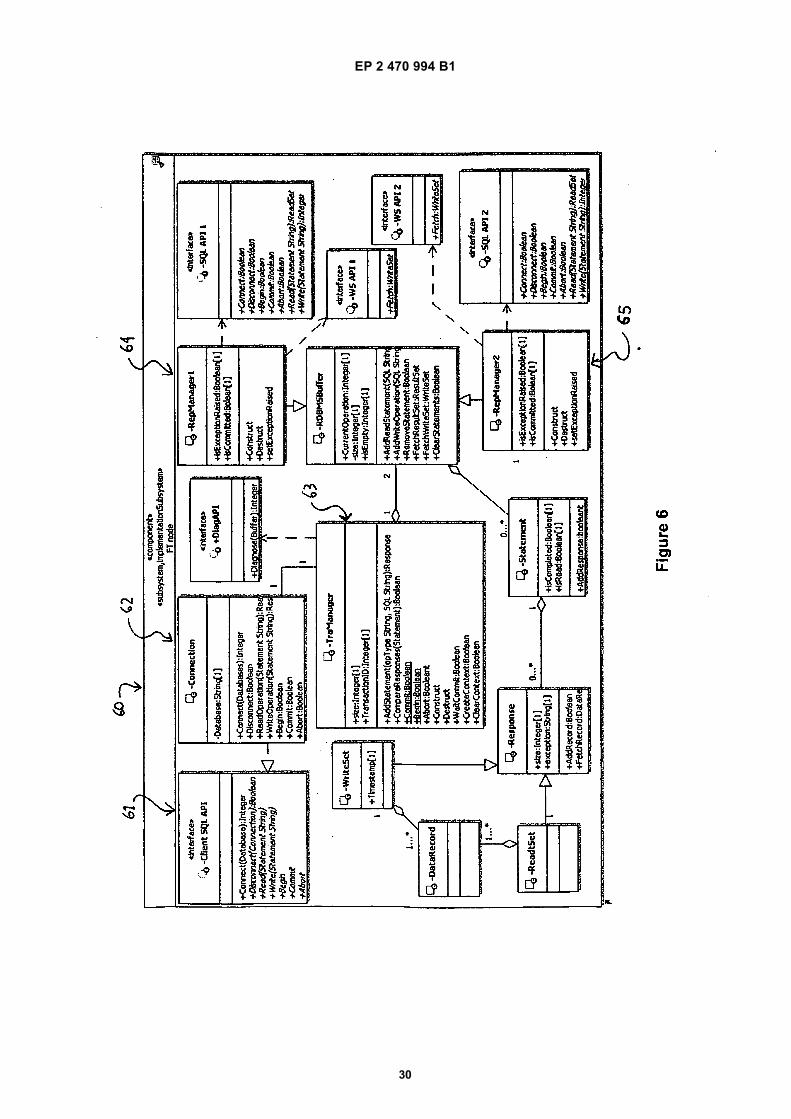
EP 2 470 994 B1
30
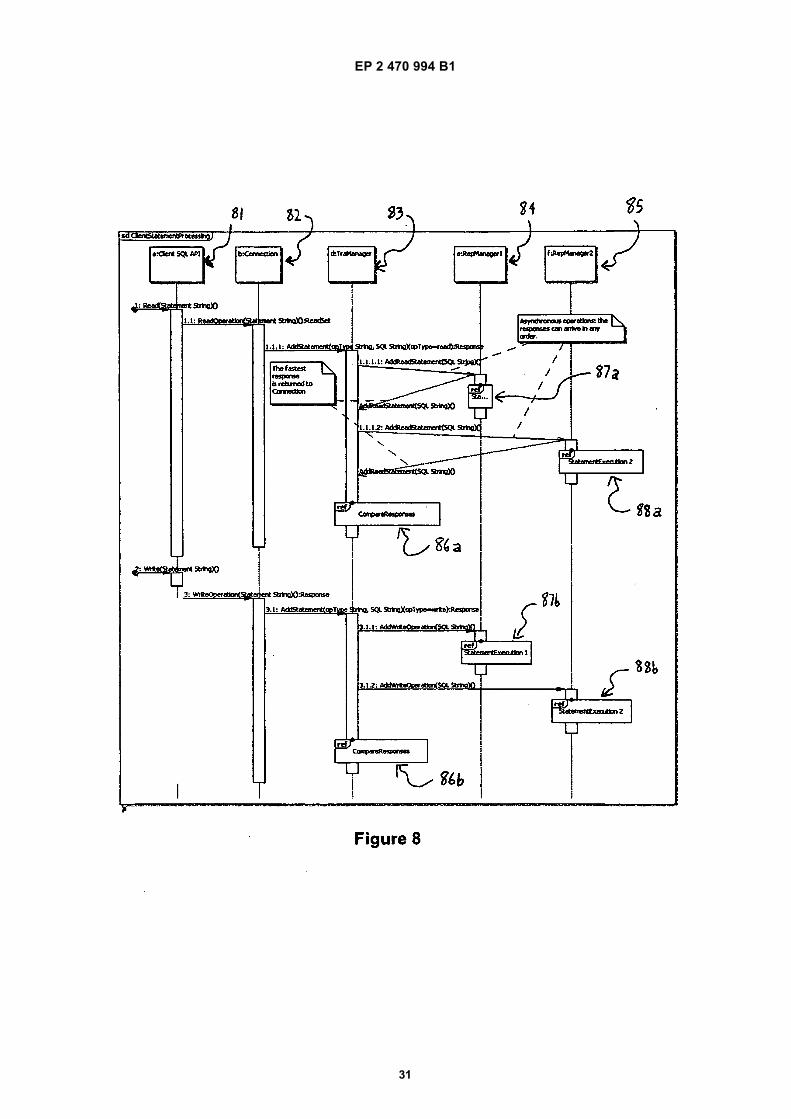
EP 2 470 994 B1
31

EP 2 470 994 B1
32

EP 2 470 994 B1
33
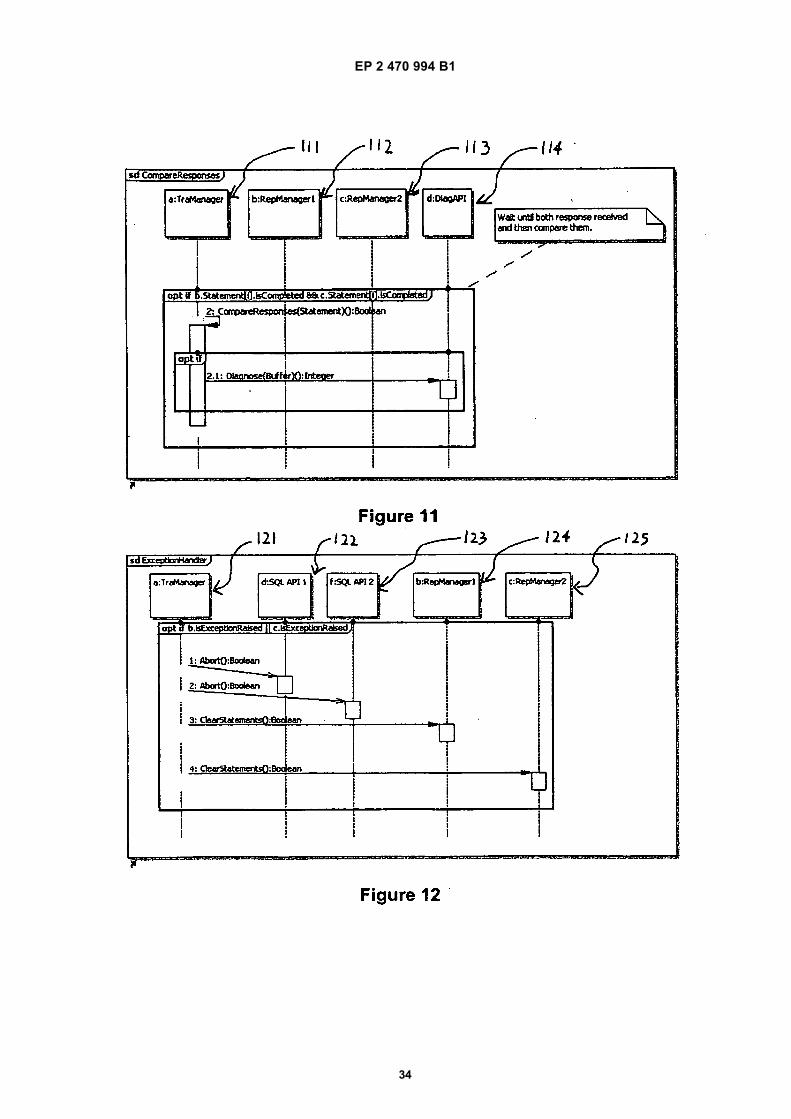
EP 2 470 994 B1
34

EP 2 470 994 B1
35

EP 2 470 994 B1
36
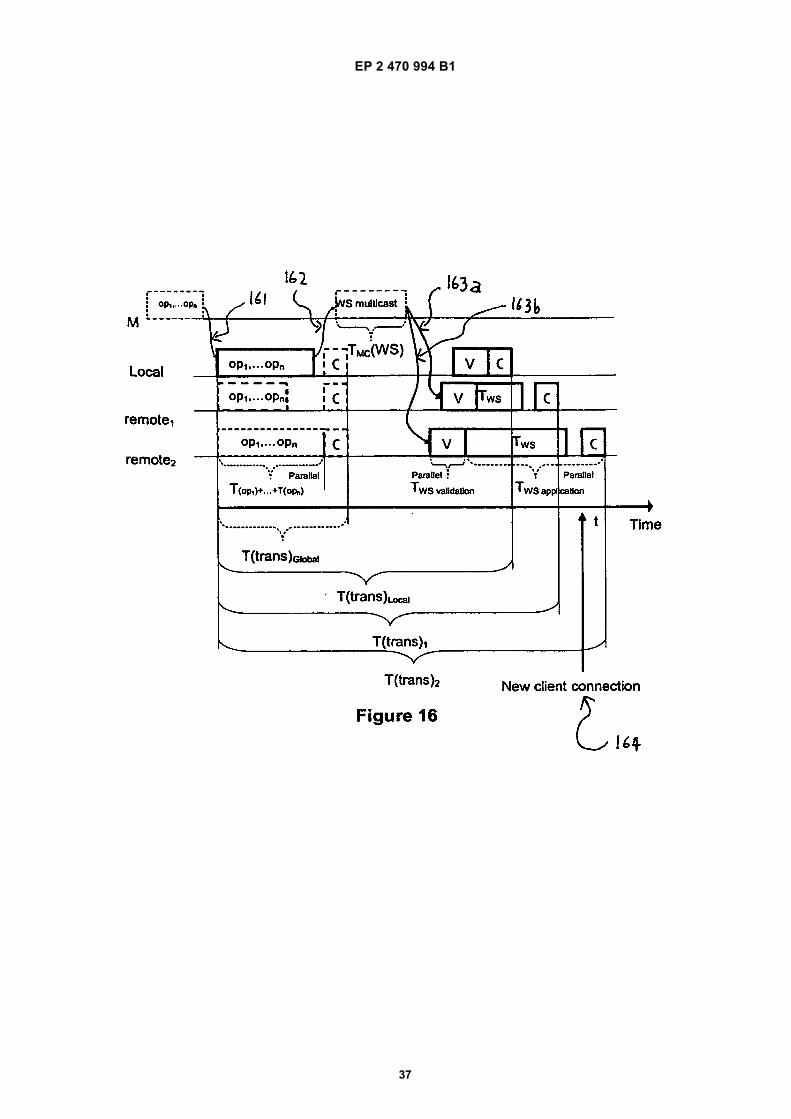
EP 2 470 994 B1
37

EP 2 470 994 B1
38
EP 2 470 994 B1
39

EP 2 470 994 B1
40
EP 2 470 994 B1
41

EP 2 470 994 B1
42
REFERENCES CITED IN THE DESCRIPTION
This list of references cited by the applicant is for the reader’s convenience only. It does not form part of the Europeanpatent document. Even though great care has been taken in compiling the references, errors or omissions cannot beexcluded and the EPO disclaims all liability in this regard.
Patent documents cited in the description
• EP 1349085 A [0008]
Non-patent literature cited in the description
• ADYA, A. ; B. LISKOV et al. Generalized SnapshotIsolation Levels. IEEE International Conference onData Engineering (ICDE, 2000 [0139]
• AGRAWAL, D. ; G. ALONSO et al. Exploiting AtomicBroadcast in Replicated Databases. Proceedings ofEuroPar (EuroPar’97, 1997 [0139]
• ANSI X3.135-1992. American National Standard forInformation Systems, 1992 [0139]
• A Critique of ANSI SQL Isolation Levels. BEREN-SON, H. ; P. BERNSTEIN et al. SIGMOD interna-tional Conference on Management of Data. ACMPress, 1995 [0139]
• Concurrency Control and Recovery in Database Sys-tems. BERNSTEIN, A. ; V. HADZILACOS et al.Reading, Mass. Addison-Wesley, 1987 [0139]
• Database Replication Using Generalized SnapshotIsolation. ELNIKETY, S. ; W. ZWAENEPOEL et al.Proceedings of the 24th IEEE Symposium on Relia-ble Distributed Systems (SRDS’05. IEEE ComputerSociety, 2005, 73-84 [0139]
• FEKETE, A. ; E. O’NEIL et al. A read-only transac-tion anomaly under snapshot isolation. ACM SIG-MOD Record, 2004, vol. 33 (3), 12-14 [0139]
• GASHI, I. ; P. POPOV. Rephrasing Rules forOff-the-Shelf SQL Database Servers. Sixth Europe-an Dependable Computing Conference, 2006. EDCC’06, 2006 [0139]
• GASHI, I. ; P. POPOV et al. Fault tolerance via di-versity for off-the-shelf products: a study with SQLdatabase server. IEEE Transactions on Dependableand Secure Computing, 2007 [0139]
• The Transaction Concept: Virtues and Limitations.GRAY, J. 7th International Conference on Very LargeData Bases (VLDB. IEEE Computer Society, 1981[0139]
• GRAY, J. ; R. LORIE et al. Granularity of locks anddegrees of consistency in a shared data base. IFIPWorking Conference on Modelling of Data Base Man-agement Systems, 1975 [0139]
• GRAY, J. ; A. REUTER. Transaction processing :concepts and techniques. Morgan Kaufmann, 1993[0139]
• Fault-tolerant broadcast and related problems.HADZILACOS, V. ; S. TOUEG. Distributed Systems.Addison-Wesley, 1993, 97-145 [0139]
• JIMENEZ-PERIS, R. ; M. PATINO-MARTINEZ. D5:Transaction Support. ADAPT Middleware Technolo-gies for Adaptive and Composable Distributed Com-ponents, 2003, 20 [0139]
• KEMME, B. Database Replication fo Clusters ofWorkstations. Swiss Federal Institute of Technology,2000, 145 [0139]
• KEMME, B. ; G. ALONSO. Don’t be lazy, be consist-ent: Postgres-R, a new way to implement DatabaseReplication. Int. Conf. on Very Large Databases(VLDB, 2000 [0139]
• Postgres-R(SI): Combining Replica Control with Con-currency Control based on Snapshot Isolation.KEMME, B. ; S. WU. International Conference on Da-ta Engineering. IEEE Computer Society, 2005 [0139]
• LAMPORT, L. ; R. SHOSTAK et al. The ByzantineGenerals Problem. ACM Transactions on Program-ming Language and Systems (TOPLAS, 1982, vol. 4(3), 382-401 [0139]
• Middleware Based Data Replication Providing Snap-shot Isolation. LIN, Y. ; B. KEMME et al. ACM SIG-MOD International Conference on Management ofData, Baltimore. ACM Press, 2005 [0139]
• MULLENDER, S. Distributed Systems. ACMPress/Addison-Wesley Publishing Co, 1993 [0139]
• PATINO-MARTINEZ, M. ; R. JIMENEZ-PERIS et al.MIDDLE-R: Consistent database replication at themiddleware level. ACM Transactions on ComputerSystems (TOCS), 2005, vol. 23 (4), 375-423 [0139]
• PREGUIÇA, N. ; R. RODRIGUES et al. Byzantium:Byzantine-Fault-Tolerant Database Replication Pro-viding Snapshot Isolation. Fourth Workshop on HotTopics in System Dependability, 2008 [0139]
• Nonblocking commit protocols. SKEEN, D. Proceed-ings of ACM SIGMOD International conference onmanagement of data. ACM Press, 1981 [0139]
• Detecting and Tolerating Byzantine Faults in Data-base Systems. VANDIVER, B. Programming Meth-odology Group. Massachusetts Institute of Technol-ogy, 2008, 176 [0139]

EP 2 470 994 B1
43
• WEISMANN, M. ; F. PEDONE et al. Database Rep-lication Techniques: a Three Parameter Classifica-tion. 19th IEEE Symposium on Reliable DistributedSystems (SRDS’00, 2000 [0139]