15-447 computer architecturefall 2007 © november 12th, 2007 majd f. sakr [email protected]...
Post on 22-Dec-2015
215 views
TRANSCRIPT

15-447 Computer Architecture Fall 2007 ©
November 12th, 2007
Majd F. Sakr
www.qatar.cmu.edu/~msakr/15447-f07/
CS-447– Computer Architecture
M,W 10-11:20am
Lecture 20Cache Memories

15-447 Computer Architecture Fall 2007 ©
Processor-DRAM Memory Gap (latency)
µProc60%/yr.(2X/1.5yr)
DRAM9%/yr.(2X/10 yrs)1
10
100
1000198
0198
1 198
3198
4198
5 198
6198
7198
8198
9199
0199
1 199
2199
3199
4199
5199
6199
7199
8 199
9200
0
DRAM
CPU
198
2Processor-MemoryPerformance Gap:(grows 50% / year)
Per
form
ance
Time
“Moore’s Law”

15-447 Computer Architecture Fall 2007 ©
Locality
°A principle that makes having a memory hierarchy a good idea
° If an item is referenced,
temporal locality: it will tend to be referenced again soon
spatial locality: nearby items will tend to be referenced soon.

15-447 Computer Architecture Fall 2007 ©
A View of the Memory Hierarchy
Regs
L2 Cache
Memory
Disk
Tape
Instr. Operands
Blocks
Pages
Files
Upper Level
Lower Level
Faster
Larger
CacheBlocks

15-447 Computer Architecture Fall 2007 ©
Our initial focus: two levels (upper, lower)
block: minimum unit of data
hit: data requested is in the upper level
miss: data requested is not in the upper level
Why Does Code Have Locality?

15-447 Computer Architecture Fall 2007 ©
Cache Design° How do we organize cache?
° Where does each memory address map to?(Remember that cache is subset of memory, so
multiple memory addresses map to the same cache location.)
° How do we know which elements are in cache?
° How do we quickly locate them?

15-447 Computer Architecture Fall 2007 ©
Block Size Tradeoff (1/3)°Benefits of Larger Block Size
• Spatial Locality: if we access a given word, we’re likely to access other nearby words soon
• Very applicable with Stored-Program Concept: if we execute a given instruction, it’s likely that we’ll execute the next few as well
• Works nicely in sequential array accesses too

15-447 Computer Architecture Fall 2007 ©
Block Size Tradeoff (2/3)°Drawbacks of Larger Block Size
• Larger block size means larger miss penalty
- on a miss, takes longer time to load a new block from next level
• If block size is too big relative to cache size, then there are too few blocks
- Result: miss rate goes up
° In general, minimize Average Access Time
= Hit Time x Hit Rate + Miss Penalty x Miss Rate

15-447 Computer Architecture Fall 2007 ©
Block Size Tradeoff (3/3)°Hit Time = time to find and retrieve data from current level cache
°Miss Penalty = average time to retrieve data on a current level miss (includes the possibility of misses on successive levels of memory hierarchy)
°Hit Rate = % of requests that are found in current level cache
°Miss Rate = 1 - Hit Rate
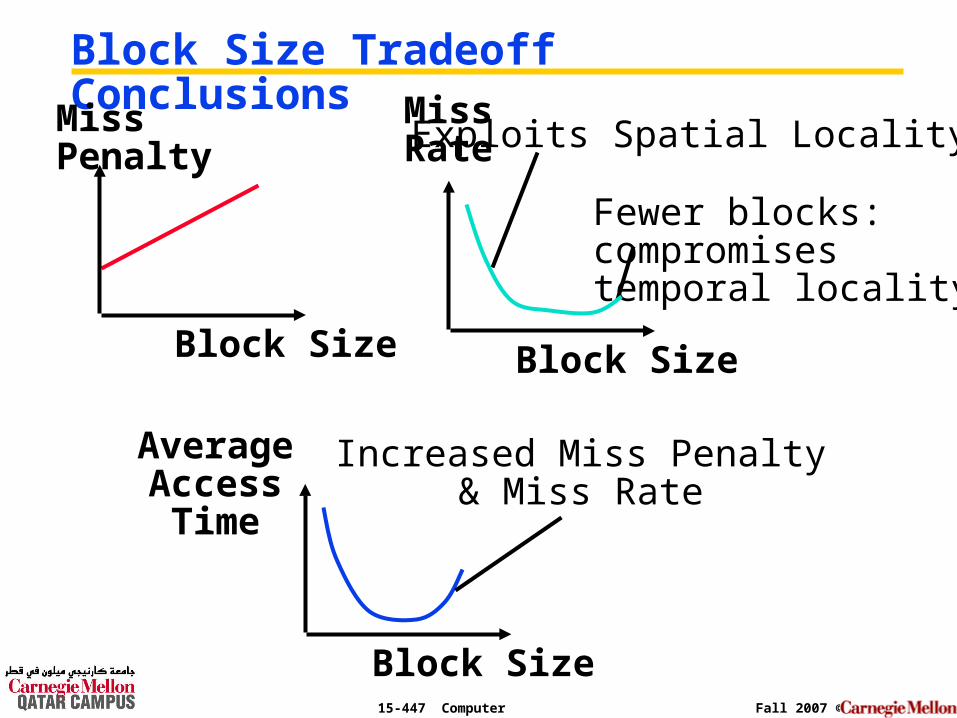
15-447 Computer Architecture Fall 2007 ©
Block Size Tradeoff ConclusionsMissPenalty
Block Size
Increased Miss Penalty& Miss Rate
AverageAccess
Time
Block Size
Exploits Spatial Locality
Fewer blocks: compromisestemporal locality
MissRate
Block Size

15-447 Computer Architecture Fall 2007 ©
Cache Design° How do we organize cache?
° Where does each memory address map to?(Remember that cache is subset of memory, so
multiple memory addresses map to the same cache location.)
° How do we know which elements are in cache?
° How do we quickly locate them?

15-447 Computer Architecture Fall 2007 ©
Direct Mapped Cache
00001 00101 01001 01101 10001 10101 11001 11101
000
Cache
Memory
001
010
011
100
101
110
111
°Mapping: address is modulo the number of blocks in the cache

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache (1/2)° In a direct-mapped cache, each memory address is associated with one possible block within the cache
• Therefore, we only need to look in a single location in the cache for the data if it exists in the cache
• Block is the unit of transfer between cache and memory

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache (2/2)
° Cache Location 0 can be occupied by data from:
• Memory location 0, 4, 8, ...
• 4 blocks => any memory location that is multiple of 4
MemoryMemory Address
0123456789ABCDEF
4 Byte Direct Mapped Cache
Cache Index
0123

15-447 Computer Architecture Fall 2007 ©
Issues with Direct-Mapped° Since multiple memory addresses map to same
cache index, how do we tell which one is in there?
° What if we have a block size > 1 byte?
° Answer: divide memory address into three fields
ttttttttttttttttt iiiiiiiiii oooo
tag index byteto check to offsetif have select withincorrect block block block

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache Terminology° All fields are read as unsigned integers.
° Index: specifies the cache index (which “row” of the cache we should look in)
° Offset: once we’ve found correct block, specifies which byte within the block we want
° Tag: the remaining bits after offset and index are determined; these are used to distinguish between all the memory addresses that map to the same location

15-447 Computer Architecture Fall 2007 ©
Caching Terminology° When we try to read memory,
3 things can happen:
1. cache hit: cache block is valid and contains proper address, so read desired word
2. cache miss: nothing in cache in appropriate block, so fetch from memory
3. cache miss, block replacement: wrong data is in cache at appropriate block, so discard it and fetch desired data from memory (cache always copy)

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache Example (1/3)° Suppose we have a 16KB of data in a direct-mapped cache with 4 word blocks
° Determine the size of the tag, index and offset fields if we’re using a 32-bit architecture
° Offset
• need to specify correct byte within a block
• block contains 4 words
= 16 bytes
= 24 bytes
• need 4 bits to specify correct byte

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache Example (2/3)° Index: (~index into an “array of blocks”)
• need to specify correct row in cache
• cache contains 16 KB = 214 bytes
• block contains 24 bytes (4 words)
• # blocks/cache
= bytes/cachebytes/block
= 214 bytes/cache 24 bytes/block
= 210 blocks/cache
• need 10 bits to specify this many rows

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache Example (3/3)° Tag: use remaining bits as tag
• tag length = addr length – offset - index = 32 - 4 - 10 bits
= 18 bits
• so tag is leftmost 18 bits of memory address
° Why not full 32 bit address as tag?
• All bytes within block need same address (4b)
• Index must be same for every address within a block, so it’s redundant in tag check, thus can leave off to save memory (here 10 bits)
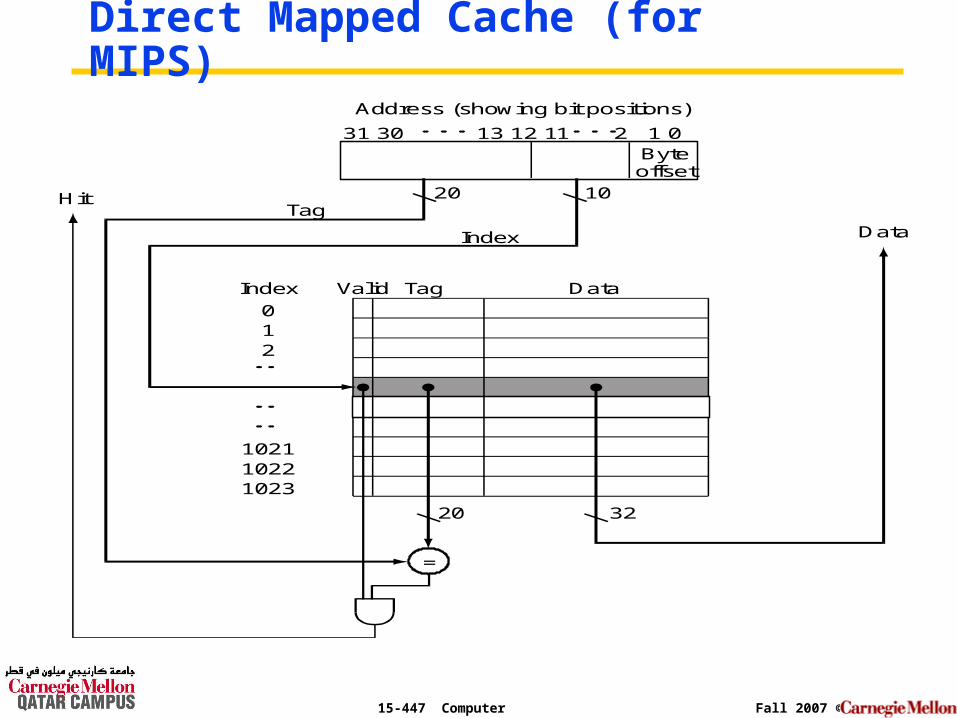
15-447 Computer Architecture Fall 2007 ©
Direct Mapped Cache (for MIPS)Address (showing bit positions)
Data
Hit
Data
Tag
Valid Tag
3220
Index
012
102310221021
=
Index
20 10
Byteoffset
31 30 13 12 11 2 1 0

15-447 Computer Architecture Fall 2007 ©
°Read hits• this is what we want!
°Read misses• stall the CPU, fetch block from memory, deliver to cache, restart
Hits vs. Misses

15-447 Computer Architecture Fall 2007 ©
°Write hits:• can replace data in cache and memory (write-through)
• write the data only into the cache (write-back the cache later)
°Write misses:• read the entire block into the cache, then write the word
Hits vs. Misses

15-447 Computer Architecture Fall 2007 ©
°Make reading multiple words easier by using banks of memory
Hardware IssuesCPU
Cache
Memory
Bus
One-word-widememory organization
a.
b. Wide memory organization
CPU
Cache
Memory
Bus
Multiplexor
CPU
Cache
Bus
Memory
bank 0
Memory
bank 1
Memory
bank 2
Memory
bank 3
c. Interleaved memory organization
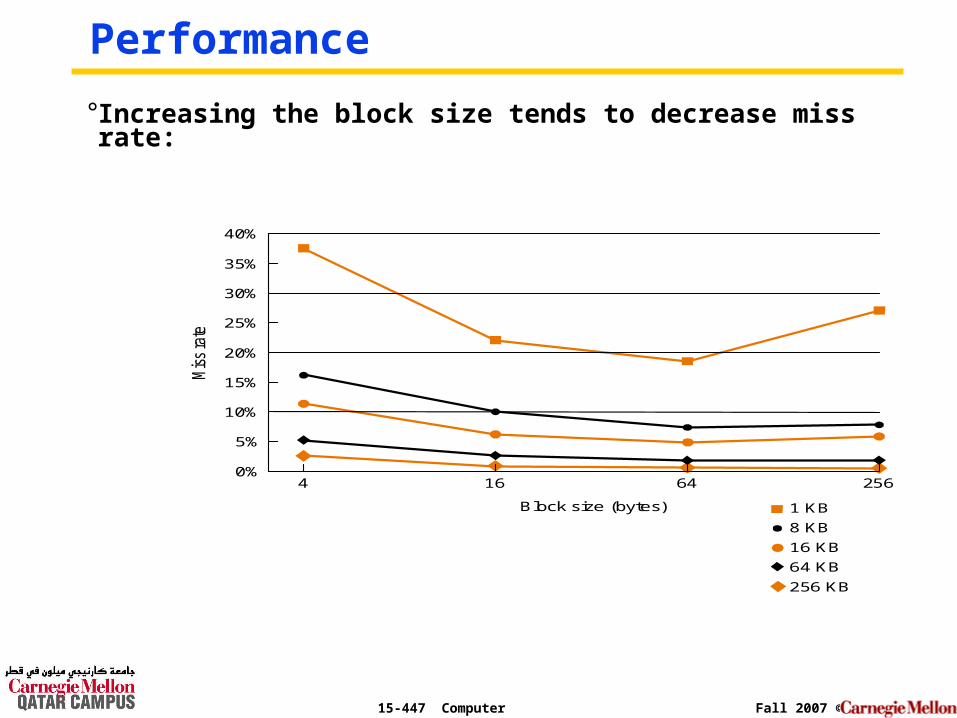
15-447 Computer Architecture Fall 2007 ©
° Increasing the block size tends to decrease miss rate:
Performance
1 KB
8 KB
16 KB
64 KB
256 KB
256
40%
35%
30%
25%
20%
15%
10%
5%
0%
Miss
rate
64164
Block size (bytes)

15-447 Computer Architecture Fall 2007 ©
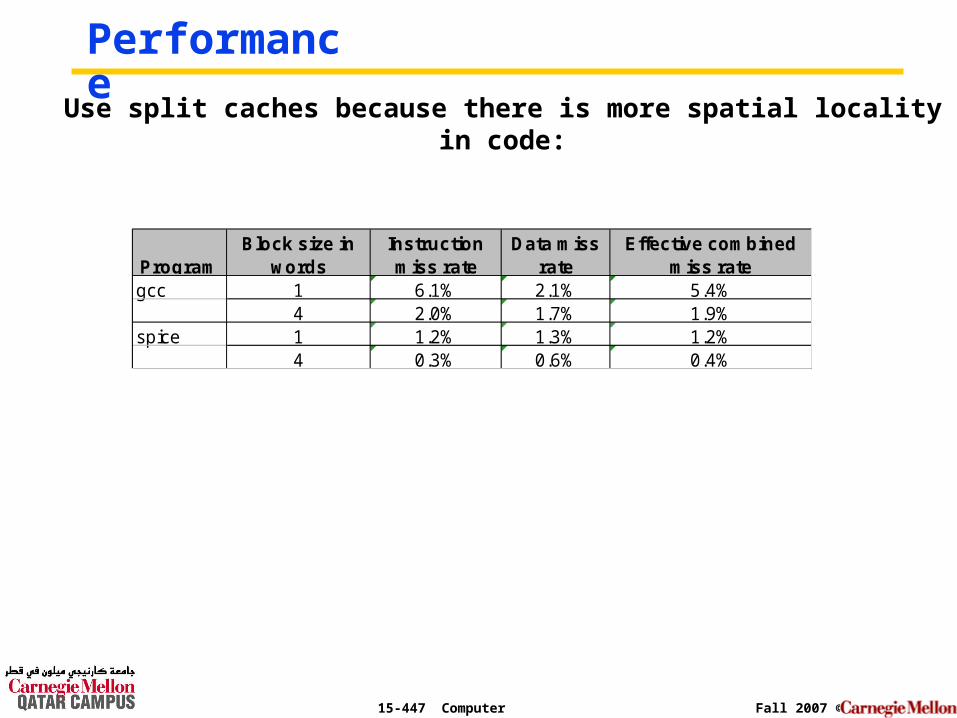
Performance
ProgramBlock size in
wordsInstruction miss rate
Data miss rate
Effective combined miss rate
gcc 1 6.1% 2.1% 5.4%4 2.0% 1.7% 1.9%
spice 1 1.2% 1.3% 1.2%4 0.3% 0.6% 0.4%
Use split caches because there is more spatial locality in code:

15-447 Computer Architecture Fall 2007 ©
Performance
°Simplified model:
execution time = (execution cycles + stall cycles) cycle time
stall cycles = # of instructions miss ratio miss penalty
°Two ways of improving performance:• decreasing the miss ratio• decreasing the miss penalty
What happens if we increase block size?

15-447 Computer Architecture Fall 2007 ©
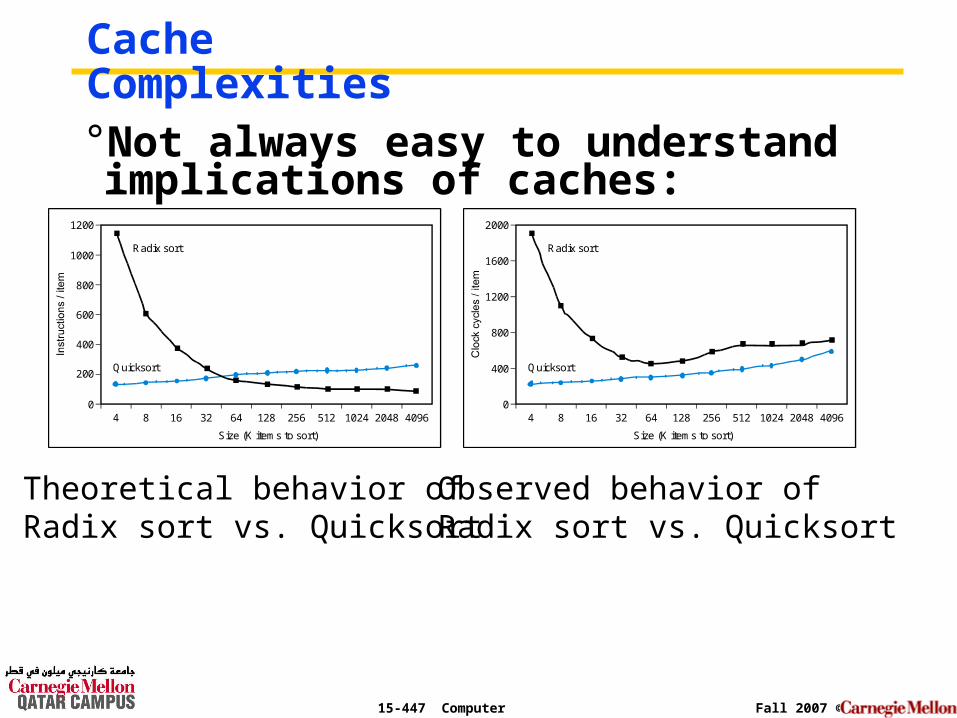
Cache Complexities°Not always easy to understand implications of caches:
Radix sort
Quicksort
Size (K items to sort)
04 8 16 32
200
400
600
800
1000
1200
64 128 256 512 1024 2048 4096
Radix sort
Quicksort
Size (K items to sort)
04 8 16 32
400
800
1200
1600
2000
64 128 256 512 1024 2048 4096
Theoretical behavior of Radix sort vs. Quicksort
Observed behavior of Radix sort vs. Quicksort

15-447 Computer Architecture Fall 2007 ©
Cache Complexities
° Here is why:
Radix sort
Quicksort
Size (K items to sort)
04 8 16 32
1
2
3
4
5
64 128 256 512 1024 2048 4096

15-447 Computer Architecture Fall 2007 ©
Cache Complexities
°Memory system performance is often critical factor
• multilevel caches, pipelined processors, make it harder to predict outcomes
• Compiler optimizations to increase locality sometimes hurt ILP
°Difficult to predict best algorithm: need experimental data

15-447 Computer Architecture Fall 2007 ©
Summary
°The :

15-447 Computer Architecture Fall 2007 ©
Our initial focus: two levels (upper, lower)
block: minimum unit of data
hit: data requested is in the upper level
miss: data requested is not in the upper level
Why Does Code Have Locality?

15-447 Computer Architecture Fall 2007 ©
°Two issues:• How do we know if a data item is in the cache?
• If it is, how do we find it?
°Our first example:• block size is one word of data
• "direct mapped"
For each item of data at the lower level, there is exactly one location in the cache where it might be.
e.g., lots of items at the lower level share locations in the upper level
Cache

15-447 Computer Architecture Fall 2007 ©
Cache Design° How do we organize cache?
° Where does each memory address map to?(Remember that cache is subset of memory, so
multiple memory addresses map to the same cache location.)
° How do we know which elements are in cache?
° How do we quickly locate them?

15-447 Computer Architecture Fall 2007 ©
Block Size Tradeoff (1/3)°Benefits of Larger Block Size
• Spatial Locality: if we access a given word, we’re likely to access other nearby words soon
• Very applicable with Stored-Program Concept: if we execute a given instruction, it’s likely that we’ll execute the next few as well
• Works nicely in sequential array accesses too

15-447 Computer Architecture Fall 2007 ©
Block Size Tradeoff (2/3)°Drawbacks of Larger Block Size
• Larger block size means larger miss penalty
- on a miss, takes longer time to load a new block from next level
• If block size is too big relative to cache size, then there are too few blocks
- Result: miss rate goes up
° In general, minimize Average Access Time
= Hit Time x Hit Rate + Miss Penalty x Miss Rate

15-447 Computer Architecture Fall 2007 ©
Block Size Tradeoff (3/3)°Hit Time = time to find and retrieve data from current level cache
°Miss Penalty = average time to retrieve data on a current level miss (includes the possibility of misses on successive levels of memory hierarchy)
°Hit Rate = % of requests that are found in current level cache
°Miss Rate = 1 - Hit Rate
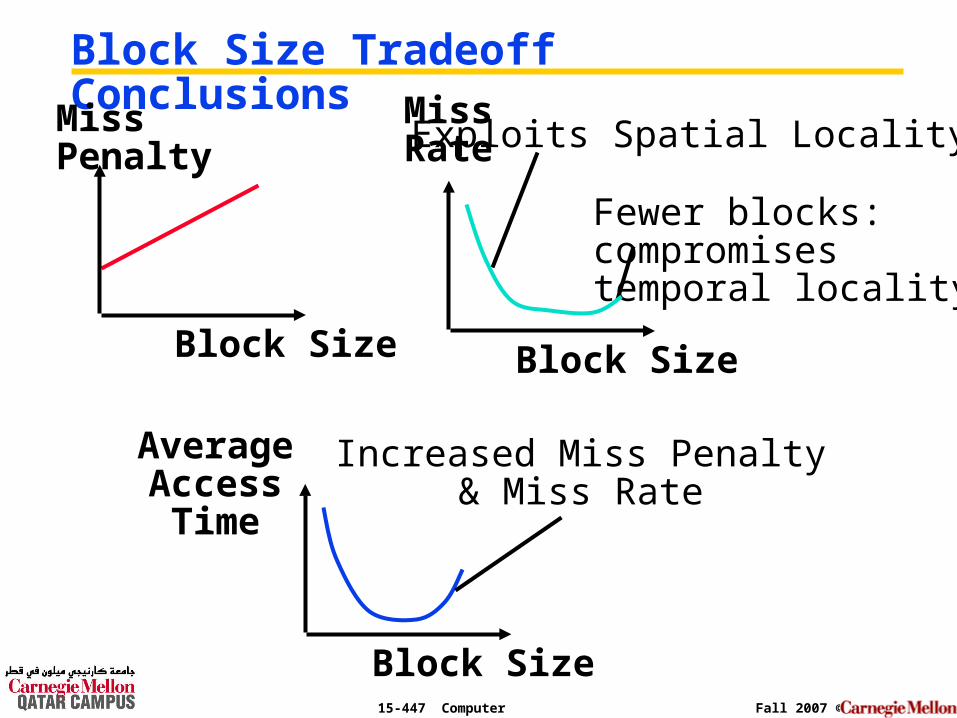
15-447 Computer Architecture Fall 2007 ©
Block Size Tradeoff ConclusionsMissPenalty
Block Size
Increased Miss Penalty& Miss Rate
AverageAccess
Time
Block Size
Exploits Spatial Locality
Fewer blocks: compromisestemporal locality
MissRate
Block Size

15-447 Computer Architecture Fall 2007 ©
Caching Terminology° When we try to read memory,
3 things can happen:
1. cache hit: cache block is valid and contains proper address, so read desired word
2. cache miss: nothing in cache in appropriate block, so fetch from memory
3. cache miss, block replacement: wrong data is in cache at appropriate block, so discard it and fetch desired data from memory (cache always copy)

15-447 Computer Architecture Fall 2007 ©
Cache Design° How do we organize cache?
° Where does each memory address map to?(Remember that cache is subset of memory, so
multiple memory addresses map to the same cache location.)
° How do we know which elements are in cache?
° How do we quickly locate them?

15-447 Computer Architecture Fall 2007 ©
Direct Mapped Cache
00001 00101 01001 01101 10001 10101 11001 11101
000
Cache
Memory
001
010
011
100
101
110
111
°Mapping: address is modulo the number of blocks in the cache

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache (1/2)° In a direct-mapped cache, each memory address is associated with one possible block within the cache
• Therefore, we only need to look in a single location in the cache for the data if it exists in the cache
• Block is the unit of transfer between cache and memory

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache (2/2)
° Cache Location 0 can be occupied by data from:
• Memory location 0, 4, 8, ...
• 4 blocks => any memory location that is multiple of 4
MemoryMemory Address
0123456789ABCDEF
4 Byte Direct Mapped Cache
Cache Index
0123

15-447 Computer Architecture Fall 2007 ©
Issues with Direct-Mapped° Since multiple memory addresses map to same
cache index, how do we tell which one is in there?
° What if we have a block size > 1 byte?
° Answer: divide memory address into three fields
ttttttttttttttttt iiiiiiiiii oooo
tag index byteto check to offsetif have select withincorrect block block block

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache Terminology° All fields are read as unsigned integers.
° Index: specifies the cache index (which “row” of the cache we should look in)
° Offset: once we’ve found correct block, specifies which byte within the block we want
° Tag: the remaining bits after offset and index are determined; these are used to distinguish between all the memory addresses that map to the same location

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache Example (1/3)° Suppose we have a 16KB of data in a direct-mapped cache with 4 word blocks
° Determine the size of the tag, index and offset fields if we’re using a 32-bit architecture
° Offset
• need to specify correct byte within a block
• block contains 4 words
= 16 bytes
= 24 bytes
• need 4 bits to specify correct byte

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache Example (2/3)° Index: (~index into an “array of blocks”)
• need to specify correct row in cache
• cache contains 16 KB = 214 bytes
• block contains 24 bytes (4 words)
• # blocks/cache
= bytes/cachebytes/block
= 214 bytes/cache 24 bytes/block
= 210 blocks/cache
• need 10 bits to specify this many rows

15-447 Computer Architecture Fall 2007 ©
Direct-Mapped Cache Example (3/3)° Tag: use remaining bits as tag
• tag length = addr length – offset - index = 32 - 4 - 10 bits
= 18 bits
• so tag is leftmost 18 bits of memory address
° Why not full 32 bit address as tag?
• All bytes within block need same address (4b)
• Index must be same for every address within a block, so it’s redundant in tag check, thus can leave off to save memory (here 10 bits)

15-447 Computer Architecture Fall 2007 ©
Direct Mapped Cache (for MIPS)Address (showing bit positions)
Data
Hit
Data
Tag
Valid Tag
3220
Index
012
102310221021
=
Index
20 10
Byteoffset
31 30 13 12 11 2 1 0

15-447 Computer Architecture Fall 2007 ©
°Read hits• this is what we want!
°Read misses• stall the CPU, fetch block from memory, deliver to cache, restart
Hits vs. Misses

15-447 Computer Architecture Fall 2007 ©
°Write hits:• can replace data in cache and memory (write-through)
• write the data only into the cache (write-back the cache later)
°Write misses:• read the entire block into the cache, then write the word
Hits vs. Misses

15-447 Computer Architecture Fall 2007 ©
°Make reading multiple words easier by using banks of memory
Hardware IssuesCPU
Cache
Memory
Bus
One-word-widememory organization
a.
b. Wide memory organization
CPU
Cache
Memory
Bus
Multiplexor
CPU
Cache
Bus
Memory
bank 0
Memory
bank 1
Memory
bank 2
Memory
bank 3
c. Interleaved memory organization

15-447 Computer Architecture Fall 2007 ©
° Increasing the block size tends to decrease miss rate:
Performance
1 KB
8 KB
16 KB
64 KB
256 KB
256
40%
35%
30%
25%
20%
15%
10%
5%
0%
Miss
rate
64164
Block size (bytes)
15-447 Computer Architecture Fall 2007 ©
Performance
ProgramBlock size in
wordsInstruction miss rate
Data miss rate
Effective combined miss rate
gcc 1 6.1% 2.1% 5.4%4 2.0% 1.7% 1.9%
spice 1 1.2% 1.3% 1.2%4 0.3% 0.6% 0.4%
Use split caches because there is more spatial locality in code:

15-447 Computer Architecture Fall 2007 ©
Performance
°Simplified model:
execution time = (execution cycles + stall cycles) cycle time
stall cycles = # of instructions miss ratio miss penalty
°Two ways of improving performance:• decreasing the miss ratio• decreasing the miss penalty
What happens if we increase block size?
15-447 Computer Architecture Fall 2007 ©
Cache Complexities°Not always easy to understand implications of caches:
Radix sort
Quicksort
Size (K items to sort)
04 8 16 32
200
400
600
800
1000
1200
64 128 256 512 1024 2048 4096
Radix sort
Quicksort
Size (K items to sort)
04 8 16 32
400
800
1200
1600
2000
64 128 256 512 1024 2048 4096
Theoretical behavior of Radix sort vs. Quicksort
Observed behavior of Radix sort vs. Quicksort

15-447 Computer Architecture Fall 2007 ©
Cache Complexities
° Here is why:
Radix sort
Quicksort
Size (K items to sort)
04 8 16 32
1
2
3
4
5
64 128 256 512 1024 2048 4096

15-447 Computer Architecture Fall 2007 ©
Cache Complexities
°Memory system performance is often critical factor
• multilevel caches, pipelined processors, make it harder to predict outcomes
• Compiler optimizations to increase locality sometimes hurt ILP
°Difficult to predict best algorithm: need experimental data