(141205) masters_thesis_defense_sundong_kim
TRANSCRIPT

1
Maximizing Influence over a
Target User through
Friend Recommendation
Master’s Thesis Defense
December 5th, 2014
Sundong Kim
Department of Industrial & Systems Engineering
Korea Advanced Institute of Science and Technology
Professor Kyoung-Kuk Kim (Chair)
Professor James Morrison
Professor Jae-Gil Lee

2
Outline
Introduction
Our Model
Information Propagation Model
Influence & Reluctance
K-node Suggestion Problem
Proposed Algorithm
Candidate Reduction
Approximation & Incremental Update
Experiments
Conclusions

3
Online Social Network with Target
A user wants to
expose him/herself
to the target user.
Target’s web feed

4
New Concept of Friend Recommendation
Suggesting relevant
friends to promote
information flow
How can we
suggest helpful
friends to the user?
Target’s web feed

5
Without Target vs. With Target
<Without considering target> <Considering target>
Recommend users which have high
node-to-node similarity (Content-
based, Topology-based)
Recommend users in order to maximize
influence over the target node
Source
TargetTarget
Source

Design the problem of friend recommendation
with a target user
Basic rule of information propagation
Influence & Reluctance
K-node suggestion problem
Develop an algorithm to solve this problem
IKA(Incremental Katz Approximation) algorithm
Candidate reduction
Approximation & Incremental update
6
Our Contribution

7
Outline
Introduction
Our Model
Information Propagation Model
Influence & Reluctance
K-node Suggestion Problem
Proposed Algorithm
Candidate Reduction
Approximation & Incremental Update
Experiments
Conclusions

8
Influence
Definition : Ratio of source
node(ns)’s article on target node
(nt)’s web feed on underlying
graph G
𝐼𝑠𝑡 𝐺 = 𝐼𝑠𝑡 =𝑟𝑠𝑡 𝑠 𝑟𝑠𝑡
Issue : How can we estimate 𝑟𝑠𝑡?
Need information propagation model.
𝑟𝑠𝑡 = 3, 𝑠 𝑟𝑠𝑡 = 8

In online social network
Action : Each individual shows interest on
someone’s article (like, share, retweet)
Effect : Information can transmit beyond
neighbor by cascading effect
9
Information Propagation
Source Target
Share Share

10
Four Principles
Source Target
ShareSource Target
Share
Share
Source
Target
Source Target
(a) Direct neighbors can receive
a post without any action. (b) An article is reached over its
neighbors by a sharing action.
(c) Users can receive the same
message multiple times.
(d) Every user can upload and
share articles.

Assumptions
Deterministic sharing probability 𝑝𝑠 Single article by each user
Independent behavior
Number of 𝑛𝑠’ article on 𝑛𝑡’s wall
11
Back to Influence
Independent
action
𝑤 ∶ 𝑊𝑎𝑙𝑘 𝑤𝑖𝑡ℎ 𝑡𝑤𝑜 𝑒𝑛𝑑𝑝𝑜𝑖𝑛𝑡 𝑛𝑠 𝑎𝑛𝑑 𝑛𝑡 𝑆 ∶ 𝑆𝑒𝑡 𝑜𝑓 𝑤𝑎𝑙𝑘𝑠 𝑏𝑒𝑡𝑤𝑒𝑒𝑛 𝑛𝑠 𝑎𝑛𝑑 𝑛𝑡 𝑙𝑒𝑛𝑔𝑡ℎ𝑤 ∶ 𝐿𝑒𝑛𝑔𝑡ℎ 𝑜𝑓 𝑤𝑎𝑙𝑘 𝑤
Example
Source Target
𝑟𝑠𝑡 = 𝑝𝑠2 + 𝟑𝑝𝑠
4 +⋯
Sequence of graph vertices
and edges
Total number of walk of
length 5 (1-2-3-2-3-4)
Number of edges in w
1 2 3 4

Katz[1] centrality
Centrality measure which considers the total number
of walks between two nodes
CKatz t = 𝑘=1∞ 𝑗=1
𝑛 𝛼𝑘 𝐴𝑘𝑠𝑡
C𝑃Katz 𝑠, t = 𝑖=1∞ 𝛼𝑘 𝐴𝑘
𝑠𝑡
Relation between Katz centrality and Influence
𝐼𝑠𝑡 =𝑟𝑠𝑡 𝑠 𝑟𝑠𝑡
=𝑟𝑠𝑡
𝑖 𝑁 𝑑𝑖𝑠𝑡 = 𝑖 𝑝𝑠𝑖−1 =
𝐶𝑃𝐾𝑎𝑡𝑧(𝑠,𝑡)
𝐶𝐾𝑎𝑡𝑧(𝑡)
12
Influence Representation
𝛼 ∶ Attenuation Factor
𝐴 ∶ Adjacency Matrix
Sharing probability =
Attenuation factorTotal number of walks from t
which length is equal to i
[1] Katz, L. (1953) A New Status Index Derived from Sociometric Analysis. Psychometrika 18. 1. : 39–43.

Awkwardness between two nodes
Definition : Negative exponential to Adamic-Adar[2] similarity
𝜌𝑖𝑗= 𝑒−𝑠𝑖𝑚(𝑖,𝑗)
Adamic-Adar similarity : sim i, j = 𝑛∈Γ 𝑖 ⋂Γ 𝑗1
log |Γ 𝑛 |
Purpose : Constraints when two nodes make connection
Example : 𝜌𝑖𝑗 = 1, where two vertices has no mutual friend
13
Reluctance
Γ 𝑖 = 𝑁𝑒𝑖𝑔ℎ𝑏𝑜𝑟 𝑜𝑓 𝑖
[2] Adamic, L., Adar, E. (2003) Friends and Neighbors on the Web. Social Networks 25. : 211–230.

14
𝐾-node Suggestion Problem
Goal : Maximize 𝐼𝑠𝑡 𝐺′ − 𝐼𝑠𝑡(𝐺)
by making connection to 𝑘-nodes
Input : G = (𝑉, 𝐸) , Source node 𝑛𝑠, Target node 𝑛𝑡 Output : Ordered set of 𝑘 suggested nodes for 𝑛𝑠 :
S = 𝑛𝑖1 , 𝑛𝑖2 , … , 𝑛𝑖𝑘 Constraint : ρ𝑠𝑖 < 1 for every suggestion
Source
Target
Source
Target
Source
Target
Good Suggestion Bad Suggestion

Computation cost for the global optimal solution
𝑛𝑘
different combination for 𝑘-node suggestion
Exponential problem with a unknown 𝑘
⇒ Greedy Algorithm
Large matrix inversion
Needed for computing influence(Katz centrality)
⇒ Approximation by Monte-Carlo simulation
Computation overlap
Occurred when computing influence on 𝐺′
⇒ Incremental update of influence
15
Major Difficulties

16
Outline
Introduction
Our Model
Information Propagation
Influence & Reluctance
K-node Suggestion Problem
Proposed Algorithm
Candidate Reduction
Approximation & Incremental Update
Experiments
Conclusions

Procedure
17
Baseline Greedy Algorithm
Calculate Ist on
original graph GCalculate ΔIst, ρ𝑠𝑖 on
G′ = G + e(ns, ni)
For all n𝑖 in
Candidate set
Find the best node n𝑏Set G + e ns, nb as G
Update
candidate set
Finish algorithm∀Δ Ist < 0
Start

Procedure
Approximate Iston original graph G
18
Proposed Algorithm
Update Ist, ρ𝑠𝑖 on
G′ = G + e(ns, ni)
For all n𝑖 in
Candidate set
Find the best node n𝑏Set G + e ns, nb as G
Update
candidate set
Finish algorithm∀Δ Ist < 0
Start
1. Candidate Reduction
1. Candidate Reduction
2. Influence Approximation 3. Incremental Update

Reduction 1 : Restrict the candidate set to the two-
hop neighbors of 𝑛𝑠 Effect : Size decreases 𝑂 𝑛 → 𝑂 𝑑2
Reason : Constraint 𝝆𝒔𝒊 < 𝟏 implies recommended
nodes should have at least one mutual friend
Reduction 2 : Gradually remove non-beneficial node
𝑛𝑖, the connection of which 𝜟𝑰𝒔𝒕 < 𝟎
Reason : Each step we suggest only one node,
there is low chance that 𝑛𝑖 would be chosen later
19
Candidate Reduction

Initial candidate set (Two-hop neighbor)
20
Working Example (Greedy Algorithm)
Candidate node
Non-beneficial node
Source user
Target user

First recommendation result
21
Working Example (Greedy Algorithm)
Candidate node
Non-beneficial node
1𝑠𝑡 suggestion
which satisfies
𝑎𝑟𝑔𝑚𝑎𝑥 Δ𝐼𝑠𝑡and Δ𝐼𝑠𝑡 > 0
Δ𝐼𝑠𝑡 < 0

Update candidate set : Remove non-beneficial
nodes from the candidate set
22
Working Example (Greedy Algorithm)
Candidate node
Non-beneficial node
1𝑠𝑡 suggestion

Update candidate set : Effect of having a new
connection
23
Working Example (Greedy Algorithm)
Candidate node
Non-beneficial node
1𝑠𝑡 suggestion

Second recommendation result
24
Working Example (Greedy Algorithm)
Candidate node
Non-beneficial node
1𝑠𝑡 suggestion
2𝑛𝑑 suggestion

Update the candidate set
25
Working Example (Greedy Algorithm)
Candidate node
Non-beneficial node
1𝑠𝑡 suggestion
2𝑛𝑑 suggestion

Third recommendation result
26
Working Example (Greedy Algorithm)
Candidate node
Non-beneficial node
1𝑠𝑡 suggestion
2𝑛𝑑 suggestion
3𝑟𝑑 suggestion
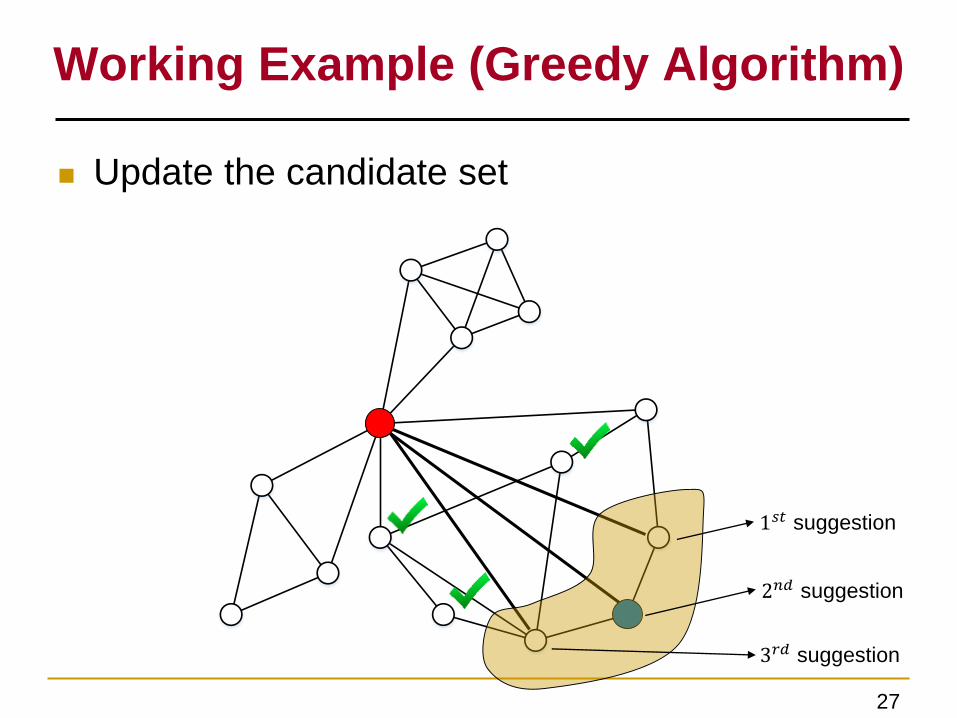
Update the candidate set
27
Working Example (Greedy Algorithm)
1𝑠𝑡 suggestion
2𝑛𝑑 suggestion
3𝑟𝑑 suggestion

No more beneficial nodes on the candidate set
28
Working Example (Greedy Algorithm)
Candidate node
Non-beneficial node
1𝑠𝑡 suggestion
2𝑛𝑑 suggestion
3𝑟𝑑 suggestion

Result of k-node recommendation
29
Working Example (Greedy Algorithm)
2
Candidate node
Non-beneficial node
1
3
1𝑠𝑡 suggestion
2𝑛𝑑 suggestion
3𝑟𝑑 suggestion

Procedure
Approximate Iston original graph G
30
Proposed Algorithm
Update Ist, ρ𝑠𝑖 on
G′ = G + e(ns, ni)
For all n𝑖 in
Candidate set
Find the best node n𝑏Set G + e ns, nb as G
Update
candidate set
Finish algorithm∀Δ Ist < 0
Start
1. Candidate Reduction
1. Candidate Reduction
2. Influence Approximation 3. Incremental Update

31
Monte-Carlo Simulation
Purpose : To get the numerical result of 𝐼𝑠𝑡 and Δ𝐼𝑠𝑡
Influence approximation (𝐼𝑠𝑡)
Simulation of Katz centrality ( 𝑠 𝑟𝑠𝑡) and personalized Katz
centrality (𝑟𝑠𝑡) using our information propagation model
Save interim result for Δ𝐼𝑠𝑡
Incremental update of influence (Δ𝐼𝑠𝑡)
Update 𝐼𝑠𝑡 𝐺′ based on I𝑠𝑡 𝐺 and 𝑒 𝑛𝑠, 𝑛𝑖1
By Initializing new diffusion starting from 𝑛𝑠 𝑎𝑛𝑑 𝑛𝑖1
32
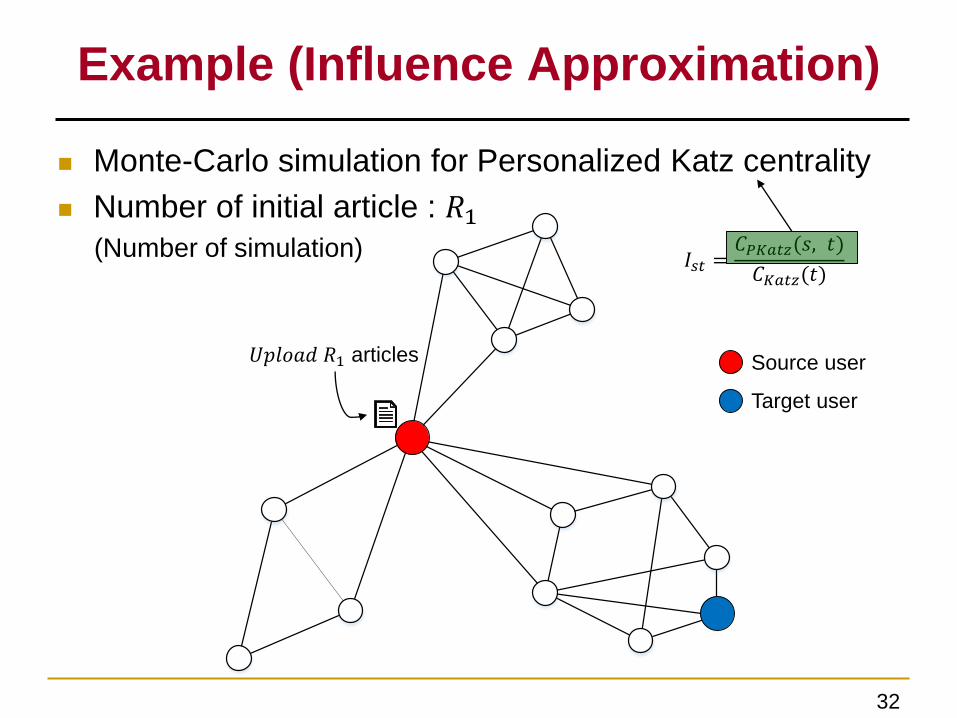
Example (Influence Approximation)
Monte-Carlo simulation for Personalized Katz centrality
Number of initial article : 𝑅1(Number of simulation)
𝑈𝑝𝑙𝑜𝑎𝑑 𝑅1 articles
𝐼𝑠𝑡 =𝐶𝑃𝐾𝑎𝑡𝑧(𝑠, 𝑡)
𝐶𝐾𝑎𝑡𝑧(𝑡)
Source user
Target user
33
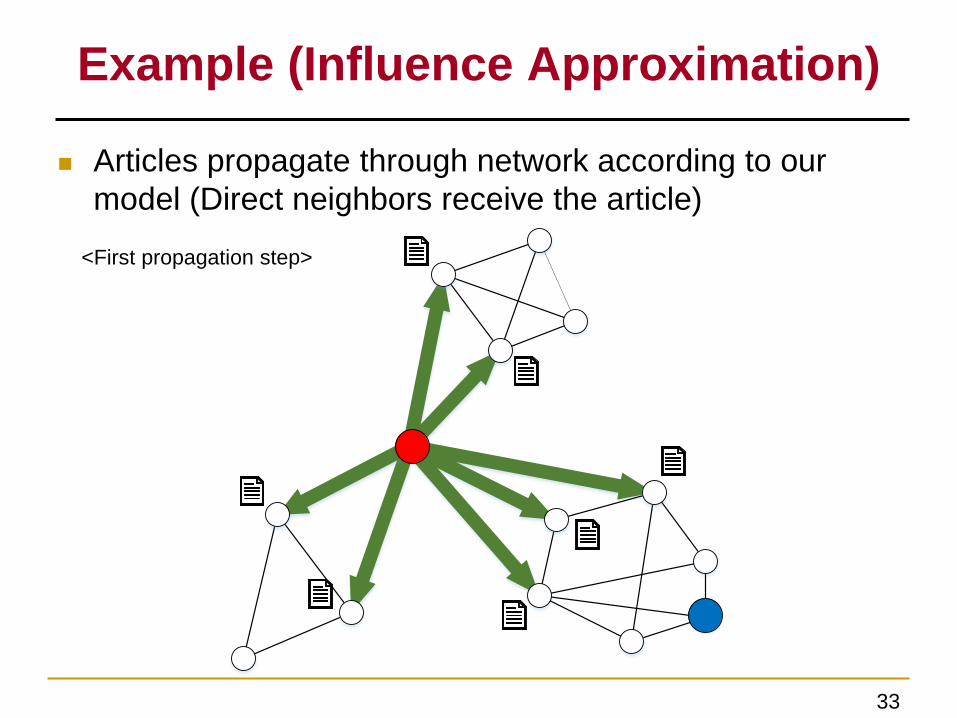
Articles propagate through network according to our
model (Direct neighbors receive the article)
Example (Influence Approximation)
<First propagation step>

34
Information propagation from a node stops if the sharing
condition (e.g. ps = 0.2) hasn’t met
Share
No sharing from this node
Example (Influence Approximation)
𝑥1 ~ 𝑈 0,1 = 0.18 < 𝑝𝑠No sharing
<Second propagation step>

Finish the simulation (Fixed step n) and count the total
number of articles which passed 𝑛𝑡
Number of article each node upload : 𝑅2Number of article 𝑛𝑡 received : 1.25𝑅2→ 𝑠 rst = 𝐶𝐾𝑎𝑡𝑧(𝑡) ≈ 1.25
𝐼𝑠𝑡 =𝐶𝑃𝐾𝑎𝑡𝑧(𝑠, 𝑡)
𝐶𝐾𝑎𝑡𝑧(𝑡)≈0.17
1.25
35
<Example>
Number of articles 𝑛𝑠 uploaded : 𝑅1Number of articles 𝑛𝑡 received : 0.17𝑅1→ rst = 𝐶𝑃𝐾𝑎𝑡𝑧 𝑠, 𝑡 ≈ 0.17
𝑅1
0.17𝑅1
Example (Influence Approximation)

Procedure
Approximate Iston original graph G
36
Proposed Algorithm
Update Ist, ρ𝑠𝑖 on
G′ = G + e(ns, ni)
For all n𝑖 in
Candidate set
Find the best node n𝑏Set G + e ns, nb as G
Update
candidate set
Finish algorithm∀Δ Ist < 0
Start
1. Candidate Reduction
1. Candidate Reduction
2. Influence Approximation 3. Incremental Update

Update part : Simulate the effect of new diffusion
occurred by a new edge
37
Example (Incremental Update)
New edge New diffusion

Continue diffusion if sharing condition has met.
Finish at the same time with the original simulation
and update the influence value
38
Example (Incremental Update)
𝑥1 ~ 𝑈 0,1 = 0.35 > 𝑝𝑠Sharing
Original diffusion
New diffusion
𝐶𝑃𝐾𝑎𝑡𝑧(𝑠, 𝑡) = +

39
Outline
Introduction
Our Model
Information Propagation
Influence & Reluctance
K-node Suggestion Problem
Proposed Algorithm
Candidate Reduction
Approximation & Incremental Update
Experiments
Conclusions

40
Network Datasets
Density
Size
Topology
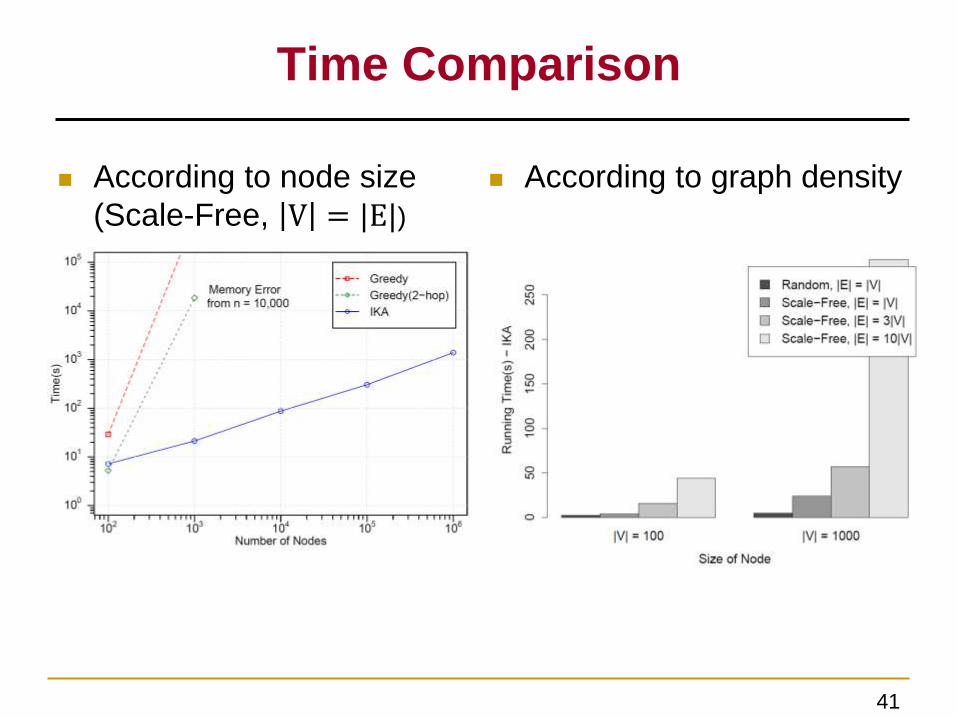
According to graph density
41
Time Comparison
According to node size
(Scale-Free, V = |E|)

Variance of influence (x-axis : 𝑅1, y-axis : 𝑅2)
42
Error Analysis
Relative error
according to the
number of initial seeds
𝑅1 : Number of initial article to approximate CPKatz(s, t)𝑅2 : Number of initial article to approximate CKatz(t)
(x-axis : 𝑅1, y-axis : 𝑅2)
43
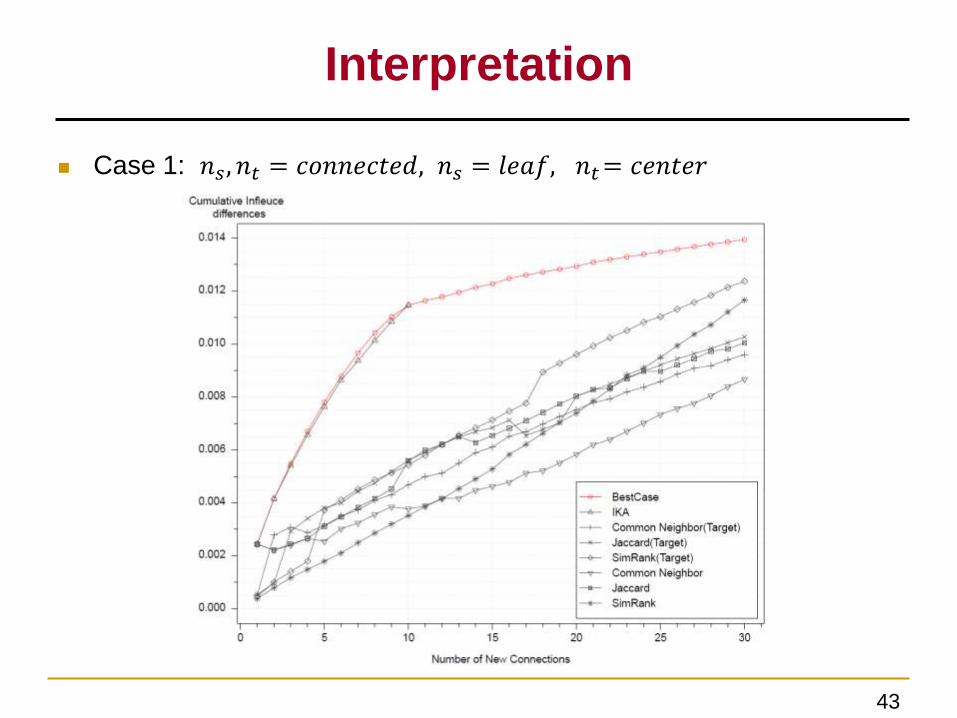
Interpretation
Case 1: 𝑛𝑠, 𝑛𝑡 = 𝑐𝑜𝑛𝑛𝑒𝑐𝑡𝑒𝑑, 𝑛𝑠 = 𝑙𝑒𝑎𝑓, 𝑛𝑡= 𝑐𝑒𝑛𝑡𝑒𝑟

44
Interpretation
Case 2: 𝑛𝑠, 𝑛𝑡 = 𝑐𝑜𝑛𝑛𝑒𝑐𝑡𝑒𝑑, 𝑛𝑠 = 𝑙𝑒𝑎𝑓, 𝑛𝑡= 𝑙𝑒𝑎𝑓

45
Outline
Introduction
Our Model
Information Propagation
Influence & Reluctance
K-node Suggestion Problem
Algorithm
Candidate Reduction
Approximation & Incremental Update
Experiments
Conclusions

46
Summary
Proposed the problem of friend recommendations having
a target user
Defined the new measure called Influence, and found
out the relation with Katz centrality
Proposed Incremental Katz Approximation (IKA)
algorithm to recommend friends effectively
Conducted various experiments and proved that IKA
effectively suggests the close persons of the target

47
Thank you

48
Future Work
Solve scalability issue (for dense graph)
Extend to multiple targets
Apply more realistic settings
Generalize sharing probability
Asymmetric behavior in social network

Initial candidate set size:
O n → 𝑂 𝑑2
Number of candidate to check in whole process:
O( 𝑖=1𝑘 𝑑(𝑑 + 𝑖)) = O kd2 + dk2 = O(kd k + d )
Overall algorithm complexity on random graph:
𝑂 𝑘𝑛4 → 𝑂 𝑘𝑑 𝑘 + 𝑑 𝑛3
Computation of Katz centrality - O n3 is a big burden →
Necessary to do approximation & incremental update
49
Appendix : Algorithm Complexity on Random graph
𝑛 ∶ 𝑁𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑛𝑜𝑑𝑒𝑠 𝑖𝑛 𝐺𝑑 ∶ 𝐴𝑣𝑒𝑟𝑎𝑔𝑒 𝑑𝑒𝑔𝑟𝑒𝑒 𝑜𝑓 𝐺
𝑘 ∶ 𝑁𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑟𝑒𝑐𝑜𝑚𝑚𝑒𝑛𝑑𝑎𝑡𝑖𝑜𝑛𝑝𝑠 ∶ 𝑆ℎ𝑎𝑟𝑖𝑛𝑔 𝑝𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑡𝑦

50
Appendix : Algorithm Complexity on Random graph
Approximation
Initializing a seed : O(n)
Approximating Katz centrality (Influence):
Θ(𝑛 + 𝑘=0∞ 𝑛𝑑 𝑑𝑝𝑠
𝑘) = Θ 𝑛 +𝑛𝑑
1−𝑑𝑝𝑠= Ο(𝑛𝑑)
Incremental update
Updating a Katz centrality for single candidate : O(d)
Find K best node: O(kd2 𝑘 + 𝑑 )
Total complexity : Ο(𝑛𝑑 + 𝑘2𝑑2 + 𝑘𝑑3)
Initialize Number of
initial neighborDecreasing
factor < 1Need to check
2 nodes over
total n nodes
Total number of
candidate set : O(kd(k + d))
𝑛 ∶ 𝑁𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑛𝑜𝑑𝑒𝑠 𝑖𝑛 𝐺𝑑 ∶ 𝐴𝑣𝑒𝑟𝑎𝑔𝑒 𝑑𝑒𝑔𝑟𝑒𝑒 𝑜𝑓 𝐺
𝑘 ∶ 𝑁𝑢𝑚𝑏𝑒𝑟 𝑜𝑓 𝑟𝑒𝑐𝑜𝑚𝑚𝑒𝑛𝑑𝑎𝑡𝑖𝑜𝑛𝑝𝑠 ∶ 𝑆ℎ𝑎𝑟𝑖𝑛𝑔 𝑝𝑟𝑜𝑏𝑎𝑏𝑖𝑙𝑖𝑡𝑦