1 progressive computation of constrained subspace skyline queries evangelos dellis 1 akrivi vlachou...
TRANSCRIPT

1
Progressive Computation of Constrained Subspace Skyline Queries
Evangelos Dellis1 Akrivi Vlachou1 Ilya Vladimirskiy1
Bernhard Seeger1 Yannis Theodoridis2
1 Department of Computer Science, University of Marburg, Germany2 Department of Computer Science, University of Piraeus, Greece

2
Overview
Introduction Motivation - Related Work Basic STA Improved Pruning Indexing using Low-dimensional R-trees Experimental Evaluation Conclusions – Future Work

3
Overview
Introduction Motivation - Related Work Basic STA Improved Pruning Indexing using Low-dimensional R-trees Experimental Evaluation Conclusions – Future Work

4
Finding A Hotel Close to the Beach
x
yb
a
i k
h
g
d
f
ec
l
o1 2 3 4 5 6 7 8 9 10
12
3
4
5
6
7
8
9
10
m
n
price
distance to the beach
Which one is better? i or h? (i, because its price and distance
dominate those of h) i or k?

5
Skyline Queries
Retrieve points not dominated by any other point:
A point p dominates another point q if it is as good or better as p in all
dimensions and better in at least one dimension.
x
yb
a
i k
h
g
d
f
ec
l
o1 2 3 4 5 6 7 8 9 10
12
3
4
5
6
7
8
9
10
m
n
price
distance

6
Skyline of Manhattan
Which buildings can we see? Higher or nearer (a building dominates another building if it is higher, closer to the
river, and has the same x position)

7
SQL Extension
Examples:
SQL syntax:
a) Find a hotel that is cheap andclose to the beach.
b) Find salespersons who were very successful in 1999 and have low salary

8
Overview
Introduction Motivation - Related Work Basic STA Improved Pruning Indexing using Low-dimensional R-trees Experimental Evaluation Conclusions – Future Work

9
Motivation
Constrained Skyline (car database):
A user may only be interested in records within the price range from 3 thousand to 7
thousand euros and with mileage reading between 20K and 100K.
The traditional skyline (dashed line) fails to return interesting points.

10
Motivation (continued) Subspace Skyline:
A car database could contain many other attributes of the cars:
horsepower, age, fuel consumption, etc…
A customer that is sensitive on the price and the mileage reading (2-dimensional subspace) would like to pose a skyline query on those attributes, rather than on the whole data space.
While the dimensionality of the corresponding data space might be rather high, skyline queries generally refer to a low dimensional subspace.
The constrained subspace skyline queries form the generalization of all meaningful skyline queries over a given dataset.

11
Related Work SKYCUBE [VLDB 2005, SIGMOD 2006]:
The Skyline Cube (SKYCUBE), consists of the skylines in all possible (2d-1) subspaces.
Drawback: It is not possible to pre-calculate the points of the full space skyline and their duplicates, since the result depends on the given constraints (static).
SUBSKY [ICDE 2006]:
Transforms the multi-dimensional data into one-dimensional, and therefore permits indexing the dataset with a B+-tree.
Drawbacks:
1. is unable to answer constrained subspace skyline queries as all points have to be transformed in a pre-processing step.
2. does not deliver the skyline points progressively.

12
x
yb
a
i k
N2N1
N3
N4
h
N6
N7
g
d
f
ec
l
o1 2 3 4 5 6 7 8 9 10
12
3
4
5
6
7
8
9
10
m
nN5
a b c d e f g h i l k
e1 e2 e3 e4
e6 e7
N1N2
N6
N3 N4
N7
R
m n
N5
e5
BBS [SIGMOD 2003, TODS 2005]:
all points are indexed in an R-tree. mindist(MBR) = the L1 distance between its
lower-left corner and the origin (NN). Keep a heap of index entries and objects,
ordered by mindist.
Is still the most efficient method for (constrained subspace) skyline retrieval!
Related Work (Continued)

13
Related Work (Continued)Shortcomings of BBS:
Maintaining a high-dimensional index to support constrained skyline queries in arbitrary dimensionality is not suitable:
It has been shown that the performance of such high-dimensional indexes deteriorates with an increasing number of dimensions. (Curse of Dimensionality)
The performance of low-dimensional constrained skyline queries decreases when the dimensionality of the indexed space is high in contrast to the query space that is low. (Random
Grouping Effect)
Only low-dimensional indexes, e.g. R-trees, seem to perform well in practice and for that reason have found their place in commercial database management systems (DBMS).

14
Our Approach
We partition vertically the data space among several low-dimensional subspaces and
index each of these subspaces using an R-tree.
A constrained skyline query is then partitioned into several sub-queries, each of them is
processed by utilizing the corresponding index using incremental NN search.
TA-INDEX [DAWAK 2005]: An algorithm for vertically partitioned nearest neighbor
queries.

15
Contributions
We present a threshold-based skyline algorithm (called STA), which exploits multiple indexes.
We propose different pruning strategies to identify dominated regions and to discard irrelevant sub-trees of the
indexes.
A workload-adaptive strategy for determining the number of indexes and the assignment of dimensions to the
indexes is presented.

16
Overview
Introduction Motivation - Related Work Basic STA Improved Pruning Indexing using Low-dimensional R-trees Experimental Evaluation Conclusions – Future Work

17
Problem Definition
Constrained Subspace Skyline Queries:
For a point p D∈ c in the dimension set S΄:
the dominance region contains points which are dominated by p.
the anti-dominance region refers to the set of points dominating p.
A point p D is said to ∈ dominate another point q D on subspace S΄ if:∈
1. on every dimension di S΄, p∈ i ≤ qi; and
2. on at least one dimension dj S΄, p∈ j < qj.

18
One-point Pruning Observation: A point p is a skyline point in S΄ if and only if there exists no point q that belongs to the anti-dominance area of p for all dimension sets Si΄
(1≤ i ≤ n).
Pruning with the Nearest Neighbor: need to prune objects not part of skyline.
1. because it is a member of the skyline, there is no dominating point.
2. among all the skyline points it is the one with a large volume, and hence, it is also expected to prune a large percentage of the data points.

19
STA: A Threshold-based Skyline Algorithm
Our algorithm works in two steps:
Filter step:
All retrieved points are organized in a priority queue (heap) based on their Manhattan distance according to the dimension set S΄.
We use the Manhattan distance of the last reported point of Si΄ as a threshold to speed up the filtering phase.
Refinement step: (domination test)
The refinement step begins when the first constrained nearest neighbor based on S΄ is returned by the filter step. This point is guaranteed to be a skyline point.
In the next iteration, where another candidate is found, the refinement step needs to determine whether this candidate is a skyline point or not.
The dominance test is performed in a way similar to traditional window queries using a main-memory R-tree whose dimensionality is equal to the query dimensionality.

20
Index Scheduling Round Robin strategy:
Inefficient
We are interested in more advanced strategies resulting in a fast increase of the threshold.
We choose the index that will increase the partial distance mostly as it is more beneficial for our threshold.
Strategies for index scheduling for nearest neighbor search on a vertically partitioned data set have been studied in [DAWAK 2005].

21
Overview
Introduction Motivation - Related Work Basic STA Improved Pruning Indexing using Low-dimensional R-trees Experimental Evaluation Conclusions – Future Work

22
Improved Pruning Motivating example:
Non uniform distributions Points form clusters
Need: Pruning using multiple points
Simultaneous pruning:
we are not able to prune simultaneously in both subspaces using the same point.

23
Multiple-point Pruning Observation: when points lying in the dominance region of a point are not discarded in at least one subspace, then we are able, under certain conditions,
to discard points in all remaining subspaces, while we guarantee no false dismissals.
we use the points that are retrieved as local constrained nearest neighbors from an index, for pruning in all other indexes.
Example: 4-dimensional data space is divided into two 2-dimensional subspaces. When the point p1 is retrieved from subspace S1 then the dominance area of the point p1 in subspace S2 is used for
pruning.

24
Avoiding False Hits Unfortunately, by following this strategy some skyline points are falsely discarded.
Case 1: Let the point q in the projection S2 collapse on the point q1. The point p is not a skyline point in S, since it is dominated by q in all dimensions sets of S.
Case 2: On the other hand, if the point q in the projection S2 collapses on the point q2, then point p may be discarded falsely, since it is a potential skyline point.
Solution: To discard points from the dominance area of p in S2, the point p and a point qi must be dominated by the projection of the
same point in S2 and S1 respectively. This condition must hold for each point qi which belongs in the discarded area of S1.

25
Overview
Introduction Motivation - Related Work Basic STA Improved Pruning Indexing using Low-dimensional R-trees Experimental Evaluation Conclusions – Future Work

26
Random Grouping Effect Random Grouping Effect: Since not all dimensions are used for splitting the axes during the index creation for a leaf node, when a query that requires projection is posed to the index the performance of the index corresponds to a random low-dimensional index,
i.e. an index that groups the points into leaf nodes in a mostly random manner.
Example: consider a 10-d data space and assume that we are interested in retrieving the skyline of any 2-d subspace.
If only two dimensions are used for splitting, then the probability that the chosen dimensions have been used for splitting is very small.
Thus, the query performance is similar to the performance of a 2-d index, where the data points were grouped together randomly.

27
Number of Indexes If every leaf node is splitted at least once in each dimension, we need a total number of at least 2d leaf nodes.
Well-performing index: every leaf node is splitted by each dimension once (L ≥ 2d).
(Defines a maximum dimensionality for a low-dimensional index)
Example: 32-d Color dataset, 68,040 records.
Our formula suggests 2 indexes
In this way we index more effectively high dimensional datasets, by avoiding performance degradation due to random grouping effect.

28
Dimension Assignment Algorithm Number of Distinct Values: a quality measure of a subspace Si
points whose projections coincide to a low-dimensional point, so that it is dominated by some duplicate point in the query-dimensional space.
DAA: a greedy algorithm to distribute the attributes over the n indexes.
restrict the random grouping effect
maximize the number of distinct values

29
Workload-adaptive Extension User preferences are correlated:
use multiple indexes, which are built on the most preferred subspaces
Simple, but very powerful extension:
associate some probability with each subspace
(the frequency with which it is queried)
weight the cost estimation of each dimension set by its probability.
This extension allows us to examine the performance of our algorithm under a workload, which is closer to real applications, instead of picking random subspaces.

30
Overview
Introduction Motivation - Related Work Basic STA Improved Pruning Indexing using Low-dimensional R-trees Experimental Evaluation Conclusions – Future Work

31
Experimental EvaluationDatasets: Three data sets from real-world applications:
NBA dataset contains 17,000 13-dimensional points, where each point corresponds to the statistics of a player in 13 categories. Color moments dataset contain 9-dimensional features of 68,040 photo images extracted from the Corel Draw database. Color histogram consists of 32-dimensional features, representing the histogram of an image.
Additionally, we generated 10-dimensional uniform datasets with a cardinality of 10,000, 50,000 and 100,000 data points.
Implementation Details: We compare our algorithm against the current state-of-the-art method BBS.
We set the page size for each R-tree to 4K and each dimension was represented by a real number.
Measurement: The number of disc I/O’s (page accesses)

32
Examination of Constrained Subspace Skylines
Effect of Constrained Region: Varying constrained region from 50% to 100% of each axis. We examine subspaces with dimensionality of dsub=3. Uniform dataset: full space dimensionality of 10-d and a cardinality of 50,000 points.
Observation: the performance of our algorithm is not affected significantly by the size of the constrained region.

33
Examination of Constrained Subspace Skylines
Effect of Subspace Dimensionality We vary the query subspace dimensionality from 2 to 4. We set the constrained region constant (represented as 60% of the values of each requested axis). These results demonstrate that the STA algorithm leads to
substantially less page accesses than BBS.
a) 10-d Uniform Dataset, 50k b) 9-d Color Dataset, 68k
These results demonstrate that the STA algorithm leads to substantially less page accesses than BBS.

34
Scalability with the Dataset Cardinality
We use uniform datasets, (dimensionality of 10-D) Vary the cardinality between 10,000 and 100,000 points. We set the constrained region to cover 60% of each axis. In addition we request the skyline of 3-dimensional subspaces.
The proposed method scale better with cardinality than BBS.

35
Scalability with Full-space Dimensionality
Varying the Full-space Dimensionality: We set the constrained region to cover 60% of each axis. In addition we request the skyline of 3-dimensional subspaces. Uniform dataset with varied dimensionality of 10, 20 and 30-d. Real datasets with varied dimensionality of 9, 13 and 32-d
a) Uniform Datasets b) Real Datasets
In both cases our algorithm constantly outperforms BBS in this experiment.
36
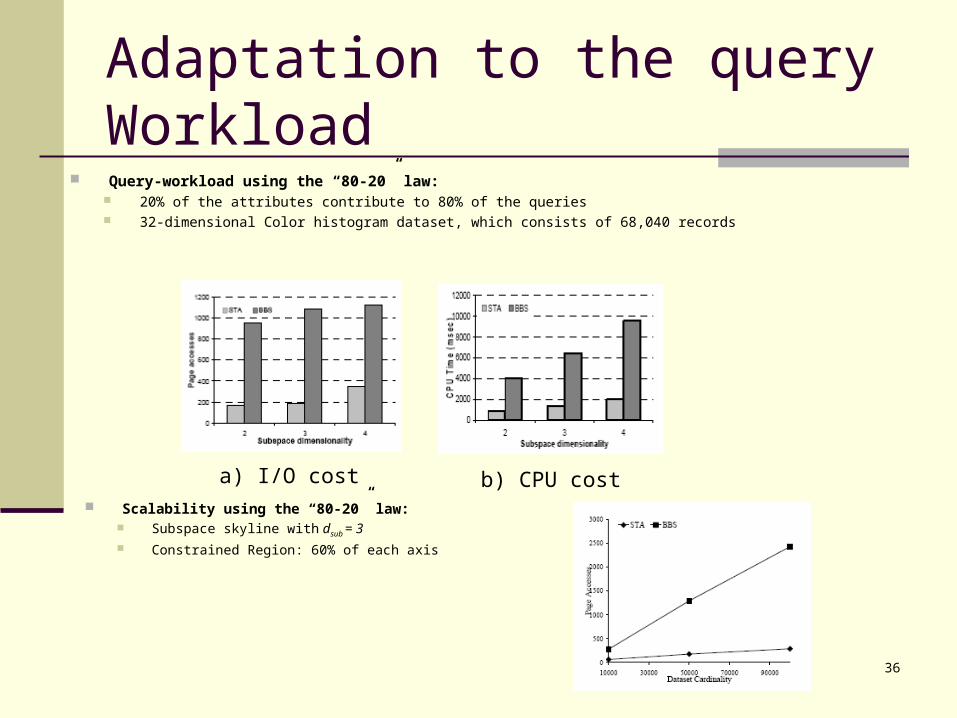
Adaptation to the query Workload Query-workload using the “80-20” law:
20% of the attributes contribute to 80% of the queries 32-dimensional Color histogram dataset, which consists of 68,040 records
a) I/O cost b) CPU cost Scalability using the “80-20” law:
Subspace skyline with dsub = 3 Constrained Region: 60% of each axis

37
Overview
Introduction Motivation - Related Work Basic STA Improved Pruning Indexing using Low-dimensional R-trees Experimental Evaluation Conclusions – Future Work

38
Conclusions – Future Work We addressed the problem of Constrained Subspace Skyline Queries and we have presented a threshold-based skyline algorithm, which exploits multiple indexes.
We proposed different pruning strategies to identify dominated regions and to discard irrelevant sub-trees of the indexes.
A workload-adaptive strategy for determining the number of indexes and the assignment of dimensions to the indexes is presented.
Extensive performance evaluation show the superiority of our proposed technique against related work.
Future Work may include: Examination of STA using external queues Development of a Cost Model for Constrained Subspace Skyline Queries

39
References SKYCUBE [VLDB 2005, SIGMOD 2006]:
Yuan, Y., Lin, X., Liu, Q., Wang, W., Yu, J., Zhang, Q.: Efficient Computation of the Skyline Cube. Very Large Data Bases Conference (VLDB), Trondheim, Norway, August 30 - September 2, 2005.
Pei, J. Jin, W, Ester, M., Tao, Y.: Catching the Best Views of Skyline: A Semantic Approach Based on Decisive Subspaces. Very Large Data Bases Conference (VLDB), Trondheim, Norway, August 30 - September 2, 2005.
Xia, T., Zhang, D.: Refreshing the Sky: The Compressed Skycube with Efficient Support for Frequent Updates. To appear in Proceedings of the 2006 ACM SIGMOD International Conforerence on Management of Data (SIGMOD), Chicago, IL, USA 2006.
SUBSKY [ICDE 2006]: Tao, Y., Xiao, X., Pei, J. SUBSKY: Efficient Computation of Skylines in Subspaces. IEEE
International Conference on Data Engineering (ICDE), Atlanta, Georgia, USA, April 3-7, 2006. BBS [SIGMOD 2003, TODS 2005]:
Papadias, D., Tao, Y., Fu, G., Seeger, B. An Optimal and Progressive Algorithm for Skyline Queries. ACM Conference on the Management of Data (SIGMOD), San Diego, CA, June 9-12, 2003.
Papadias, D., Tao, Y., Fu, G., Seeger, B. Progressive Skyline Computation in Database Systems. ACM Transactions on Database Systems, 30(1): 41-82, 2005.
TA-INDEX [DAWAK 2005]: Dellis, E., Seeger, B., Vlachou, A. Nearest Neighbor Search on Vertically Partitioned High-
Dimensional Data. In Proceedings of 7th International Conference on Data Warehousing and Knowledge Discovery (DaWaK), Copenhagen, Denmark, 2005

40
Thank You
Questions?