1 p2p querying wes hatch mumt-614 mar 27 2003. 2 what is p2p? nodes of equal roles exchanging...
TRANSCRIPT

1
P2P Querying
Wes HatchMUMT-614
Mar 27 2003

2
What is P2P?
Nodes of equal roles exchanging information and services directly
“distributed databases” good for file sharing, but…
no complex query optimization no guarantee on quality of results
Can also be used to foster collaboration among geographically distributed coworkers “Sharing computer cycles” --> SETI Institute created a
distributed virtual supercomputer.

3
P2P systems
Just beyond their infancy Many P2P projects are in their research
phases only a handful are in common use
Concerns regarding dependability
4
Gnutella
An open, online P2P network does not require a central server for
indexing data files not proprietary

5
Gnutella
Is both software and a communication protocol
Computer functions as both a client and server “Servent” runs on each member node

6
Gnutella basics
member node keeps track of three or four other member nodes (mean = 3.4) web of interlinked
member nodes
0
50
100
150
200
0 10000 20000 30000 40000 50000Number of nodes
Number of links ('000)

7
Quick review of architecture
Routing and TTL (time to live) DON’T forward every packet to every connected host
would swamp the network with duplicate packets (which it already is)
when a message is sent, it is stamped with a TTL each host which receives the TTL then decrements it Can change the value of the TTL in settings panel
Set the TTL to 255, if you want…

8
Basic Query
String matching Query sent to all computers that returned Pong packets. Each of these computers checks if it has any match,
If no, it sends the Query packet on to all the computers to which it is connected.
Process continues until TTL expires Could be awhile as most servents allow you to adjust the
TTL GUIDs in each computer ensure that the same
message does not get passed to the same computer again and again, creating a loop.

9
Downloading
The query by now has been distributed to a huge number of computers
QueryHit contains IP address and GUID of the
computer which has the desired content
Push For computers behind a firewall

10
Common Messages Message Frequency .
-
5
10
15
20
25
1 18 35 52 69 86 103 120 137 154 171 188 205 222 239 256 273 290 307 324 341 358 375
minute
messages per secod
PingPushQueryOther

11
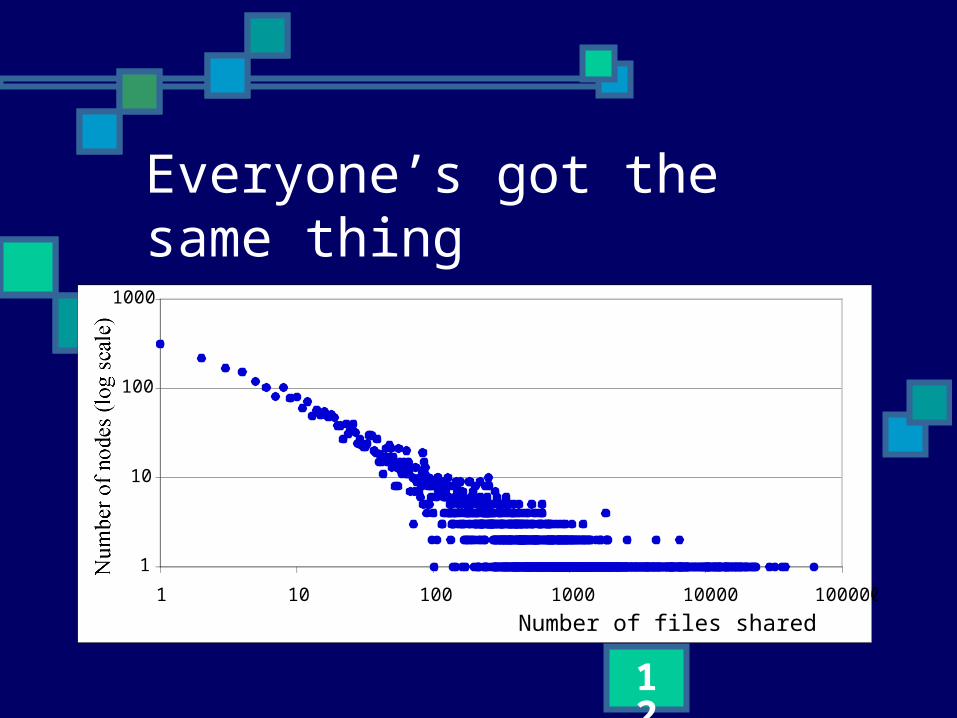
Everyone’s searching for the same thing small percentage of files make up the
bulk of queries query processing dominates the
workload of a node
12
Everyone’s got the same thing
1
10
100
1000
1 10 100 1000 10000 100000
Number of files shared (log scale)
Number of nodes (log scale)

13
One saving grace
“correlation between file and query distributions explains why Gnutella has not collapsed under the weight of its naive, flooding-based probe scheme” (Ledlie)
Query popularity follows a power-law distribution

14
Current limitations in Gnutella
Querying is: Slow Inefficient
Bandwidth hungry require symmetrical communication channel ( i.e. same
upstream and downstream channel bandwidths) Insecure “transient community”
member nodes do not have permanent IP addresses. A new IP addressing scheme is needed

15
More limitations
Problem: work well when the rate at which nodes enter and exit the system is small….but Doesn’t address the tradeoffs between the
type/reliability of information exchange, and how long each node is active
80% of the nodes exist for less than one hour!

16
Spectrum of “control”
Gnutella is “loose” Inefficient
Finding a needle in a haystack Simple
DHT Lookup queries only Efficient
measured in absolute resources consumed

17
DHT
“ like having a file cabinet distributed over numerous servers” (F.Kaashoek) if one server goes down, not all of the data is
compromised. no central server that contains a list of where all the
data is Scalable
Lookups can be resolved in log n hops Flexible Fault-tolerant

18
Why DHT?
SQL-like searching each server has a partial list (small
routing table) of where data is stored in the system The trick is to create a “lookup” algorithm that
allows data location to be easily found

19
N-grams
Technique from information retrieval to do inexact matching
Convert search strings into n-tuples Eg. Beethoven--> “Bee” “eth” “tho” …

20
DHT techniques
Query optimization like network routing? Hiearchical organization of data
Geographic layout Proximity routing Proximity neighbour selection

21
One example
directed BFS sends query to a subset of neighbours maintains statistics on neighbours
ping latency, history of # results chooses subset intelligently (via heuristics) to
maximize quality of results Eg neighbours w/shortest message queue (long
message queue implies that node is saturated or dead)

22
Semantic Overlay Networks
Nodes w/semantically similar content are clustered together
Depends on classifiers to determine “what similar content is!”

23
Semantic Overlay Networks
Granularity Too little will not generate enough locality; too
much will increase maintenance costs When to join a given SON
How much of a given content should a user have?
Tradeoff between search speed and quality of results

24
Semantic Overlay Networks
Queries are processed by identifying which SON (s) are best equipped to answer it
Nodes outside a given SON are not bothered by the query Saves time and resources

25
Semantic Overlay Networks
Classification hierarchy Buckets: a bucket is associated with each
concept in hierarchy All Music Guide
When querying, need to decide which buckets (ie. Nodes) to consider
If nodes have diverse files, won’t be enough clustering to justify the use of SONs

26
Semantic Overlay Networks
Need to classify queries so the request may be directed accordingly Manual Automatic
Text matching Bayesian networks

27
System schematic

28
Semantic Overlay Networks
Use only 10-20% of the message overhead of current P2P systems
Further improved query performance Marginal effect to maximum achievable recall
level

29
How will this affect queries?
SON Faster results as there is less time spent
processing queries Resources better spent Hierarchical distribution of data