1 ics-forth & univ. of crete selene november 2002 zacharioudakis giorgos p2p systems &...
TRANSCRIPT

1
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
P2P Systems & technologies
Zacharioudakis Giorgos

2
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Presentation overview
P2P architectures & typical systems Technical issues Popular P2P Systems Research areas Project JXTA technology Vision about SeLene project

3
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
What is Peer-to-Peer?
Definition: Nodes of equal roles exchanging information and services directly
Scale: millions (billions?) of peersNature of peers: PC’sApplication: lightweight semantics (e.g., file-sharing)
Is this a new idea?IP routingDNS, NTPDistributed Databases

4
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
P2P vs. Distributed DBMS
Traditional DDBMS Issues:
TransactionsNetwork PartitionsDistributed Query OptimizationInteroperation of
heterogeneous data sourcesReliability/failure of nodes
Complex features do not scale
Example P2P application: file-sharingSimple data model & query language
No complex query optimizationEasy interoperation
No guarantee on quality of resultsIndividual site availability
unimportantLocal updates
No transactionsNetwork partitions OK
Simple Amenable to large-scale network of PCs

5
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
P2P Applications
File sharingNapster, Gnutella
Instant MessagingJabber
Distributed ComputationSETI@home
Web servicesAkamai
Distributed storageFreenet
Anonymity, censorship resistanceMixmaster remailersRed Rover, Publius
Cooperative workGroove
Other ...

6
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Technical issues
scalability fault tolerance speed bandwidth consumption processing cost security anonymity
publishing/retrieval metadata semantic querying availability of results interoperability ...

7
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Metadata and Interoperability
MetadataSystem metadata (e.g filename, bitrate, filesize etc)Resource metadata (e.g relations, hierarchies etc)
Currently, queries are in the form of keyword matchingWe would like to perform queries in more expressive languages,
taking advantage of semantic knowledge metadata Technologies:
Programming interfaces:XML-RPC, SOAP, HTTP, JXTA
Data and metadata representation - common ontologies and formatXML, RDF

8
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Different Approaches to Distributed Search
Network topology based architecturesRelies on the organization of peers within the network to route
requestsThese approaches focus on how to reduce the diameter of the graph
representing the distributed networks
Content based approachesMessage content is used in either the organization of the network or
the routing of messages or bothThese approaches focus on how to reduce the query path-length of
the access structure they use
9
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
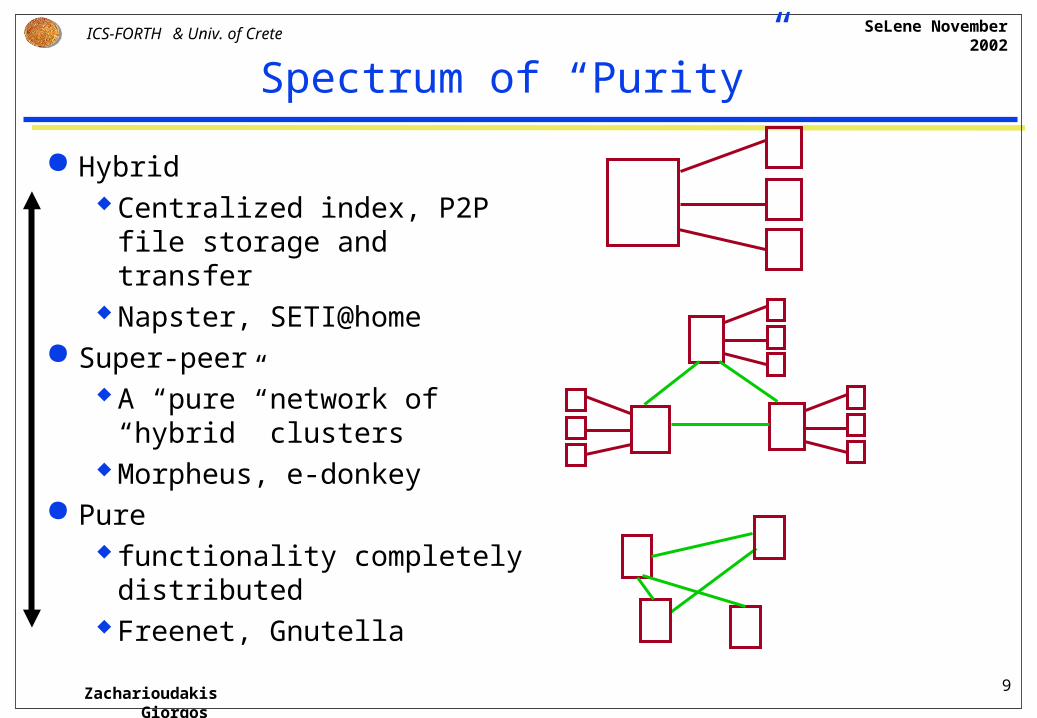
Spectrum of “Purity”
HybridCentralized index, P2P file
storage and transferNapster, SETI@home
Super-peerA “pure” network of “hybrid”
clustersMorpheus, e-donkey
Purefunctionality completely
distributedFreenet, Gnutella

10
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Publishing/Requesting/Responding
hybridcentral indexingeach node registers to a central indexqueries are performed to the central indexretrieval is done from other ‘peer’ nodes
pureeach ‘peer’ manages its own index about local (remote) resourcesqueries are typically performed with broadcastsretrieval is done from responding ‘peers’ that hold the requested resource
super-peerssome nodes act as coordinators and manage indices for a subset of nodes each node registers to its local coordinatorqueries are performed to the coordinators, which in turn communicate as in a distributed p2p system with other super-peersretrieval is done from other ‘peers’ that hold the requested resource

11
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Representative P2P Systems
Network topology based architecturesNapsterGnutellaMorpheus
Content based architecturesChordP-Grid

12
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Napster (hybrid)
Membership: Each client joins a server, where he registers its local files to the central index
Query: A client make queries to the central server which returns references to the clients that actually hold the resources
Retrieval: The client connects to other ‘peer’ clients and retrieves the resource. The selection is performed by the user but it could be done automatically based on bandwidth, load or other criteria

13
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Napster (hybrid)
server
membership / register resources
1
...
2
3
4
query
response {1,4}
get file

14
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
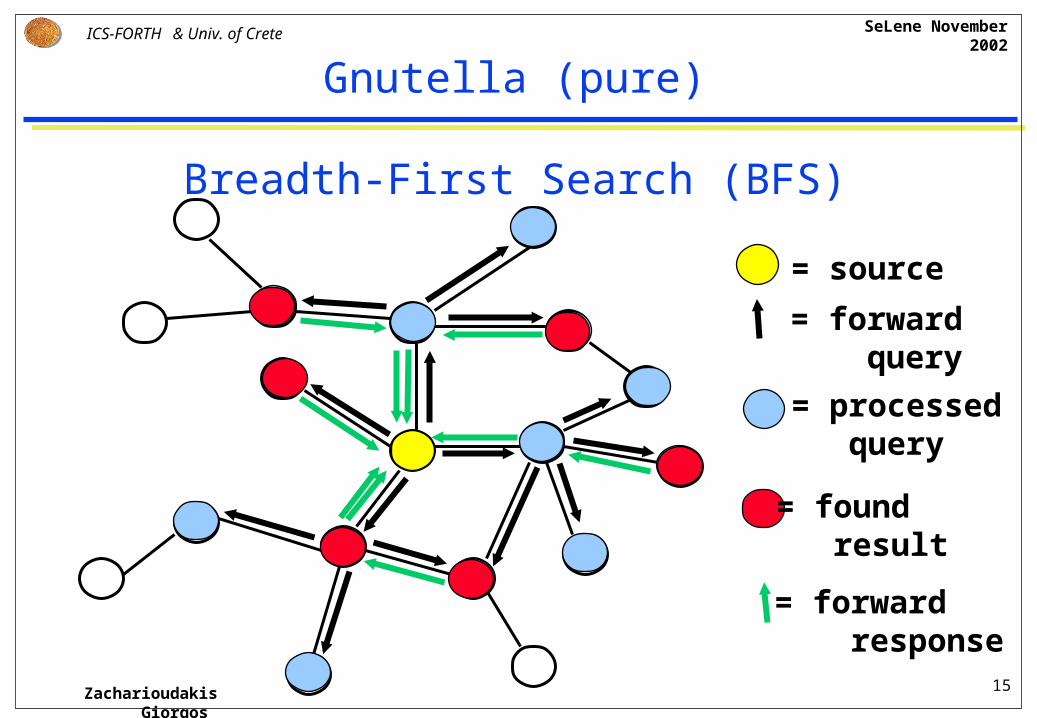
Gnutella (pure)
Gnutella is not a system: it is a protocol, with various existing gnutella clients that implement it.
Membership: Through a predefined static list with addresses or through “host caches”, a peer can connect to a set of gnutella clients. After connection a client expands its list of known addresses with the lists obtained from other peers.
Query: A peer broadcasts a query to its known peers; these forward the query to their known peers and so on until a max TTL (packet’s Time To Live) is reached, which is the depth limit of the query.
Retrieval: Peers that hold the requested resource respond to the peer that issued the query. Through the reverse path of the query, the originating peer finally discovers a list of peers having the resource and then obtains it from one of them.
15
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Gnutella (pure)
= forward query
= processed query
= source
= found result
= forward response
Breadth-First Search (BFS)

16
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Gnutella (pure)
Each peer maintains a small minimum number of simultaneous active connections These peers are selected from a locally maintained host catcher list
containing the addresses of all known peers Peer discovery
watching PING-PONG messages noting the addresses of peers initiating queries receiving connections from previously unknown hosts out-of-band channels (IRC, Web) host caches
Query propagation: upon receiving a query a peer broadcasts it to all peers that is currently connected to, and so on as a chain letter If a peer has a file that matches the query, sends an answer back
(though it still forwards the query). This process continues to a maximum depth (“search horizon”)

17
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Morpheus (Super-Peer)
Self organizing network Neither search requests nor actual downloads pass through any
central server The network is multi-layered, so that more powerful computers get to
become search hubs ("SuperNodes") Any client may become a SuperNode, if it meets the criteria of
processing power, bandwidth and latency Network management is automatic - SuperNodes appear and
disappear according to demand

18
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Morpheus (Super-Peer)
SN1SN3
SN2 SN4
SN412.34.56.78

19
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Morpheus (Super-Peer)
Intelligent downloads Morpheus implements a type of fail-over system that attempts to
locate another peer sharing the same file, and automatically resume the download where it left off at the failed host
When Morpheus search engine finds that more than one active peer is serving a particular file, it associates the list of peers with the file for later reference
If the user instructs Morpheus to download the file, it can distribute the download task over this list of peers
SuperNodes act like local search hubs and proxy search requests on behalf of their connected peers
Supernode
Peer 1 Peer 2 Peer 3
File 1File 2
.
.
.File n
File 1File 2
.
.
.File n
File 1File 2
.
.
.File n
Search queryPeer 2
:file 1
Get file 1

20
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Chord (content based search)
Chord is a lookup service, not a search service
Based on binary search trees Provides just one operation:
A peer-to-peer hash lookup:Lookup(key) IP addressChord does not store the data
Uses Hash function:Key identifier = SHA-1 (key)Node identifier = SHA-1 (IP
address)Both are uniformly distributedBoth exist in the same ID space
How to map key IDs to node IDs?A key is stored at its successor:
node with next higher ID (modulo N)
0 M
- an item- a node
0 1 4 6 7 10
N10N1
K0
K7
K4
CircularID space
K11

21
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Chord (content based search)
The goal of Chord is to provide the performance of a binary search which means O(log N) query path-lengthIn order to manage a maximum path-length O(log N) each node maintains a routing table (called “finger table”) with at most m entries (where m=logN) The ith entry in the table at node n contains the identity of the first node s that succeeds n by at least 2i-1 on the identifier circle (all arithmetic modulo 2m)
i.e., s = successor(n + 2i-1), 1≤ i ≤ m Note that the first finger of n is its immediate successor on the circle
1
6
54
0
3
2
7
Start (n + 2i-1) Interval of
responsibility
Successor
1 [1,2) 1
2 [2,4) 3
4 [4,0) 0
existing nodenot existing node, but a
possible value in ID space

22
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Chord (content based search)
Important characteristics Each node stores info only about a small number of possible IDs (at most logN) Knows more info about nodes closely following it on the identifier circle A node’s table does not generally contain enough info to locate the successor of an arbitrary key k
1
6
54
0
3
2
7
Start Int. Succ.
1 [1,2) 1
2 [2,4) 3
4 [4,0) 0
Start Int. Succ.
2 [2,3) 3
3 [3,5) 3
5 [5,1) 0
Start Int. Succ.
4 [4,5) 0
5 [5,7) 0
7 [7,3) 0

23
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Chord (content based search)
“Finger Table” Allows Log(n)-time Lookups
N32
N10
N5
N20
N110
N99
N80
N60
K19
How do we locate the successor of a key k?If n can find a node whose ID is closer than its own to k, that node will know more about the identifier circle in the region of k than n doesThus n searches its finger table for the node j whose ID most immediately precedes k, and asks j for the node it knows whose ID is closest to k
start
Interval Succ.
100 [100,101)
110
101 [101,103)
5
103 [103,107)
5
107 [107,115)
5
115 [115,3) 5
3 [3,35) 5
35 [35,100) 60
By repeating this process, n learns about nodes with IDs closer and closer to kGradually we will find the immediate predecessor of k
… … …
9 [9,13) 10
13 [13,21) 20
Lookup(K19)

24
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Chord Autonomy
When new keys are inserted the system is not affected. It just finds the appropriate node and stores it
When nodes join or leave, the finger tables must be correctly maintained and also some keys must be transferred to other nodes
Also, every key is stored only in one node, which means that if that node becomes unavailable the key is also unavailable
This incurs an O(log2N) cost for maintaining the finger tables and assuring correctness of the system while nodes join/leave the system
This imply a restricted autonomy of the system The only replicated information is (implicitly) the finger tables,
because each node has to maintain its own

25
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
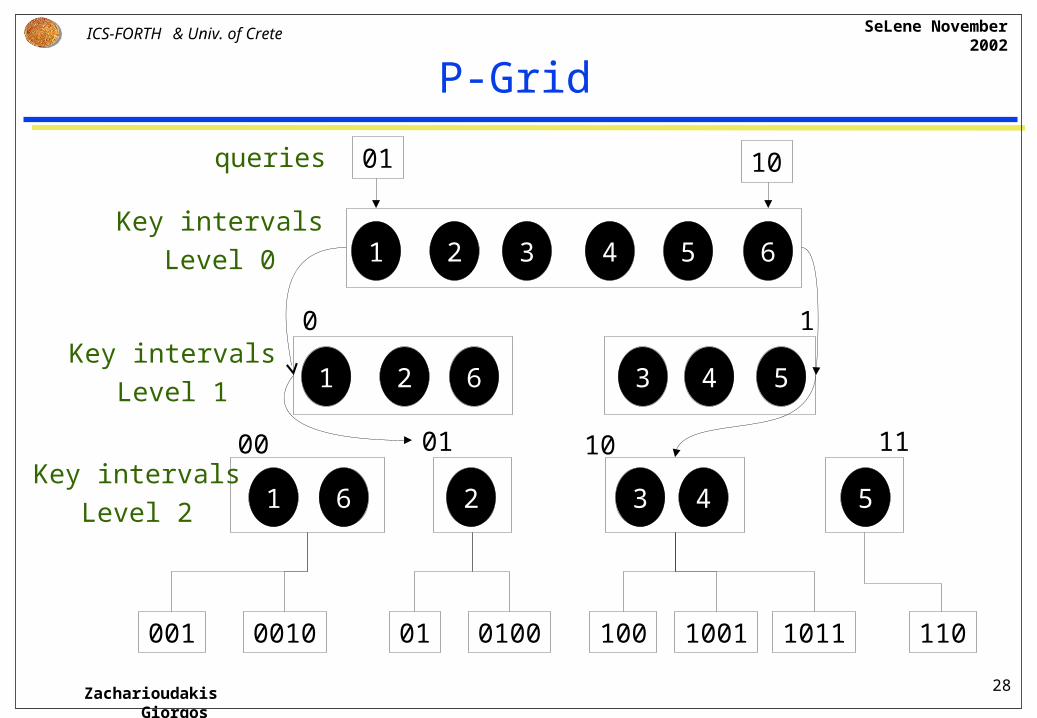
P-Grid
Basic characteristicsBased on building distributed, binary prefix treesUse of randomized algorithms for constructing the access structure,
updating the data and performing the searchScale gracefully, equally for all nodes
Access structureWe assume that the index terms are binary strings, built from 0’s & 1’sThe search space is partitioned into intervals Every peer takes over responsibility for one interval As each key corresponds to a path in the binary prefix tree the peer is
also responsible for one path of the search treeEach peer stores the peers responsible for the other branches of the
path for routingSearch requests are either processed locally or forwarded to the peers
on the alternative branches

27
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
P-Grid
1 52 3 4 6Key intervalsLevel 0
001 0010 01 0100 100 1001 1011 110
1
1 2 6 53 4Key intervalsLevel 1
0
1 6 2 3 4 5Key intervals
Level 2
00 01 10 11
28
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
P-Grid
1 52 3 4 6
1 2 6 53 4
1 6 2 3 4 5
Key intervalsLevel 0
Key intervalsLevel 1
Key intervalsLevel 2
queries 01 10
0
001 0010 01 0100 100 1001 1011 110
1
00 01 10 11

29
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
P-Grid Autonomy
The system implies that peers eventually meet, but does not examine how does this occur, i.e. it is possible that they never meet
As many peers can be responsible for the same key the general problem is how to find all those peers in case of an update
Proposed solutions multiple BFS or DFS searches for a key and propagating the
update to themCreating lists of “buddies” for each peer (i.e. other peers that
share the same key) and propagate the update to all buddies These imply that although the system is decentralized and peers
does not rely to central authorities, the construction and update of the access structure may impose some performance issues, especially when updating a key

30
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
P-Grid Autonomy
When a new node enters the system, assumes that he is responsible over the whole prefix namespace interval
When he meets with other nodes they split the interval and each maintain a reference to the other node
When a node leaves abruptly, the other nodes have incorrect references and as soon as they are aware of it they ‘resume’ responsibility over that prefix interval
The replicated information in this system is the multiple references to the same keys and the “buddies” lists (when used) in order to face the update problem

31
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
P2P comparison
Paradigm Search type Search cost (messages)
Autonomy
Napster Centralized indexing
String comparison
O(1) Low
Gnutella Breadth-first search on graph
String comparison
Very high
Morpheus
Super-peers Metadata comparison
O(logN)? High
Chord Implicit binary search trees
Equality O(logN) Restricted
P-Grid Binary prefix trees
Prefix O(logN) High
TTL
i
iCC0
)1(**2

32
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
P2P performance metrics
Bandwidth Storage (replication) Processing cost Path-length (required hops) Quality of Results
Number of resultsSatisfaction (true if # results >= X, false otherwise)Time to satisfaction

33
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Hybrid p2p
Advantages Simple to manage and
availability of results -due to central indexing
Less (aggregated) bandwidth consumption
Small processing cost for peers Idle nodes that do not offer
resources does not downscale system’s performance
Disadvantages Does not scale Single point of failure Great processing cost for server Vulnerable to censorship

34
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Pure p2p
Advantages Efficiency: harnessing unused
resources Self-organizing Robustness and availability
through replication Anonymity/legal
protection/censorship resistant
Disadvantages Difficult to manage and poor
results due to lack of central indexing
Bandwidth consuming Idle nodes downscale the
overall performance Higher processing cost for
peers

35
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Super peers
Advantages Scalable Fault tolerant Adaptable and self-organizing Efficient Low path-length
Disadvantages Hard to manage/maintain Complex topology, difficult to
evaluate its metrics (through simulation or trace driven analysis)

36
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Content-based searching architectures
Advantages Low search cost ( O(logN) ) Harnessing the content
information into queries. Good approach for content that
can be described with simple attributes.
Less messages per query than a random graph.
Load balancing.
Disadvantages More restrictions than topology-
based architectures: when nodes join/leave, rehashing and content migration needs to be performed.
A peer needs to know what is looking for, to map it to an address.
Not practical for content described by multiple attributes.
Storage and routing are closely connected

37
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Conclusions about p2p systems
Benefitsefficiency: harnessing
unused resources Self-organizingSharing cost of ownershipRobustness and availability
through replicationAnonymity/legal protection
ChallengesNo authority to enforce
behaviorCooperationUnreliability of individual
peersEfficiency of distributed
operations (absolute resources)
Imposed research issues• Resource Management• Security• Efficient Search

41
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Project JXTA
JXTA is a set of protocols which allow peers to discover and communicate with each other
Protocols are defined in terms of XML messages exchanged between peers
JXTA is platform (e.g Windows), language (e.g Java) and transport (e.g TCP/IP) independent

42
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
JXTA Concepts
Concepts:Peer - a node that speaks the JXTA
protocols Peer Group - a collection of
cooperating peers Message - a datagram containing an
envelope, protocol headers and bodies
Pipe - an async communication channel for sending/receiving messages
Advertisement - an XML document that publishes the existence of a resource (peer, peer group, pipe, service)
peer
peer
peer
peer
peer
peer grou
p
pipe advertisement

43
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
JXTA Model

44
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
JXTA Protocols
Peer Discovery Protocol - used between any peers to find other peers, peer groups, or advertisements
Peer Information Protocol - used to learn about another peer's properties
Peer Resolver Protocol - 'foundation protocol' for the Peer Discovery Protocol and the Peer Information Protocol. Can be used to build other protocols as well. Defines send/receive 'generic queries' and responses to be sent from one peer to another
Peer Membership Protocol - used to find out about, join and leave groups
Pipe Binding Protocol - used to bind a pipe to an actual endpoint
Peer Endpoint Protocol - used to provide routing information for paths between peers (if a direct connection is not possible)

45
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
JXTA Search
JXTASearch is a framework for searching in distributed networksA protocol for registration, query and responseA series of services for interacting via this protocol
Gnutella style peer search JXTA style peer search

46
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
JXTA Search
AdvantagesSupports very dynamic networksReduce publishing and query
response latencyCentralized control (centralized
implementation of security, accounting, membership, …)
DisadvantagesSingle point of failureScalabilityCentralized control …

47
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
Towards a Super-Peer Architecture for SeLene
Birkbeck
Orsay
Uoc UoCyprus

48
ICS-FORTH & Univ. of Crete SeLene November 2002
Zacharioudakis Giorgos
References
http://www.internet2.edu/presentations/20020131-P2P-Kan.htm http://softwaredev.earthweb.com/java/article/0,,12082_783281,00.html http://www.cs.vu.nl/pub/globe/cp2pc/notes/allnotes/jxta.overview http://wiki.cs.uiuc.edu/cs427/P2P+Architecture http://www.stanford.edu/class/cs347/handouts/p2p.ppt http://cv.uoc.es/~grc0_000228_web/Marques/Tesi_JM.htm http://iew3.technion.ac.il/~spektory/098223/presentations/fastTrack.ppt