1 hafta_dersi
TRANSCRIPT

TÜBİTAK
BYL 644
Giriş
1. Ders
Dr. Atakan ERDEM
2014

TÜBİTAK
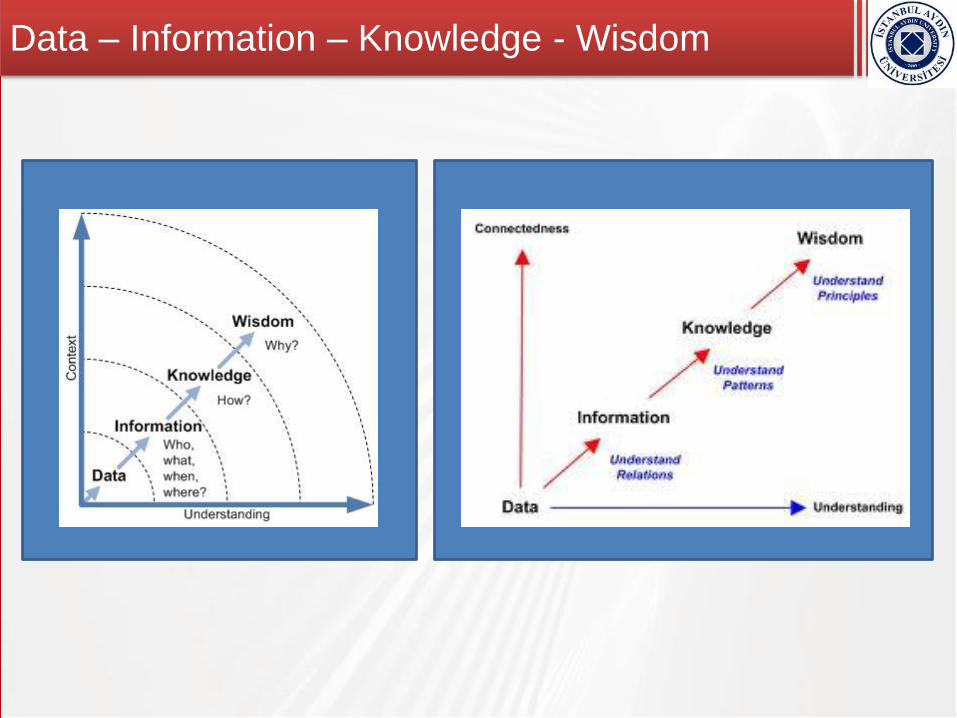
Data – Information – Knowledge - Wisdom
TÜBİTAK
Data – Information – Knowledge - Wisdom

TÜBİTAK
Büyük Veri Nedir ?

TÜBİTAK
Büyük Veri
Every minute of the day:
YouTube receives 48 hours of uploaded video (~15 GB)
Over 2 million search queries hit Google
Twitter users post about 100,000 tweets
571 new websites are created
Over 200,000,000 email messages are created and sent
Estimates place the size of digital data the world over to be
approaching 1.2 zettabytes;
TB -> PB -> EB -> ZB -> YB .......... ?

TÜBİTAK
Büyük Veri Yönetimi

TÜBİTAK
Büyük Veri Yönetimi

TÜBİTAK
Hadoop

TÜBİTAK
Hadoop
• Hadoop, sıradan sunuculardan (commodity hardware)
oluşan küme (cluster) üzerinde büyük verileri işlemek
amaçlı uygulamaları çalıştıran ve Hadoop Distributed File
System (HDFS) olarak adlandırılan bir dağıtık dosya sistemi
ile Hadoop MapReduce özelliklerini bir araya
getiren, Java ile geliştirilmiş açık kaynaklı bir kütüphanedir
• Daha yalın bir dille anlatmak gerekirse, Hadoop, HDFS ve
MapReduce bileşenlerinden oluşan bir yazılımdır.

TÜBİTAK
Hadoop HDFS
• HDFS sayesinde sıradan sunucuların diskleri bir araya
gelerek büyük, tek bir sanal disk oluştururlar.
• Bu sayede çok büyük boyutta bir çok dosya bu dosya
sisteminde saklanabilir.
• Bu dosyalar bloklar halinde birden fazla farklı sunucular
üzerine dağıtılarak RAID benzeri bir yapıyla yedeklenir.
• Bu sayede veri kaybı önlenmiş olur.

TÜBİTAK
Hadoop HDFS
• Ayrıca HDFS çok büyük boyutlu dosyalar üzerinde okuma
işlemi (streaming) imkanı sağlar.
• Ancak rastlantısal erişim (random access) özelliği
bulunmaz.
• HDFS, NameNode ve DataNode proseslerinden
oluşmaktadır.

TÜBİTAK
Hadoop HDFS - NameNode
• NameNode ana (master) proses olarak blokların sunucular
üzerindeki dağılımınından, yaratılmasından, silinmesinden,
bir blokta sorun meydana geldiğinde yeniden
oluşturulmasından ve her türlü dosya erişiminden
sorumludur.
• Kısacası HDFS üzerindeki tüm dosyalar hakkındaki bilgiler
(metadata) NameNode tarafından saklanır ve yönetilir.
• Her kümede yalnızca bir adet NameNode olabilir.

TÜBİTAK
Hadoop HDFS - DataNode
• DataNode ise işlevi blokları saklamak olan işçi
(slave) prosestir. Her DataNode kendi yerel diskindeki
veriden sorumludur.
• Ayrıca diğer DataNode’lardaki verilerin yedeklerini de
barındırır. DataNode’lar küme içerisinde birden fazla olabilir.

TÜBİTAK
Hadoop MapReduce
• Hadoop MapReduce HDFS üzerindeki büyük dosya verilerini
işleyebilmek amacıyla kullanılan bir yöntemdir.
• İstediğiniz verileri filtrelemek için kullanılan Map fonksiyonu ve
bu verilerden sonuç elde etmenizi sağlayan Reduce
fonksiyonlarından oluşan program yazıldıktan sonra Hadoop
üzerinde çalıştırılır.
• Hadoop Map ve Reduce’lerden oluşan iş parçacıklarını küme
üzerinde dağıtarak aynı anda işlenmesini ve bu işler sonucunda
oluşan verilerin tekrar bir araya getirilmesinden sorumludur.

TÜBİTAK
Hadoop MapReduce
• Hadoop’un gücü işlenen dosyaların her zaman ilgili
düğümün (node) yerel diskinden okunması ile ağ trafiğini
meşkul etmemesinden ve birden fazla işi aynı anda
işleyerek doğrusal olarak ölçeklenmesinden geliyor
diyebiliriz.

TÜBİTAK
Hadoop

TÜBİTAK
Hadoop MapReduce
• Aşağıdaki grafikte olduğu gibi Hadoop kümesindeki düğüm
sayısı arttıkça performansı da doğrusal olarak artmaktadır.

TÜBİTAK
Hadoop
• Hadoop şu anda Yahoo, Amazon, eBay, Facebook,
Linkedin gibi birçok lider firmada büyük verileri analiz
etmek amacıyla kullanılıyor.
• Hadoop projesi aynı zamanda büyük verileri işleme
konusundaki diğer projelere bir çatı görevi görüyor.

TÜBİTAK
Hadoop Alt Projeleri
• Hadoop projesinin altında
• Avro (veri dizileştirme (serialization) sistemi),
• Cassandra (yüksek erişilebilir, ölçeklenebilir NoSQL
veritabanı),
• HBase (Hadoop üzerinde çalışan, büyük veriler için
ölçeklenebilir, dağıtık NoSQL veritabanı),
• Hive (büyük veriler üzerinde iş zekası sistemi),

TÜBİTAK
Hadoop Alt Projeleri
• Hadoop projesinin altında
• Mahout (ölçeklenebilir yapay öğrenme (machine
learning) ve veri madenciliği kütüphanesi),
• Pig (paralel hesaplamalar için yüksek düzeyli bir
veri akışı dil ve yürütme kütüphanesi),
• ZooKeeper(dağıtık uygulamalar için yüksek ölçekli
koordinasyon uygulaması) projeleri geliştiriliyor.

TÜBİTAK
Hadoop

TÜBİTAK
Akan Verilerin İşlenmesi

TÜBİTAK
Bugünlük bu kadar
Dr. Atakan ERDEM
2014