1 foil per page - distributed and parallel systems group
TRANSCRIPT

1
Parallel SystemsyProgramming, Analysis and Optimization
for High Performance Computingfor High Performance Computing
Part 1:Introduction
foils by R. Buyya, F. Ercal, T. Fahringer, I. Foster, M. Gerndt, W. Jalby, B. Wilkinson
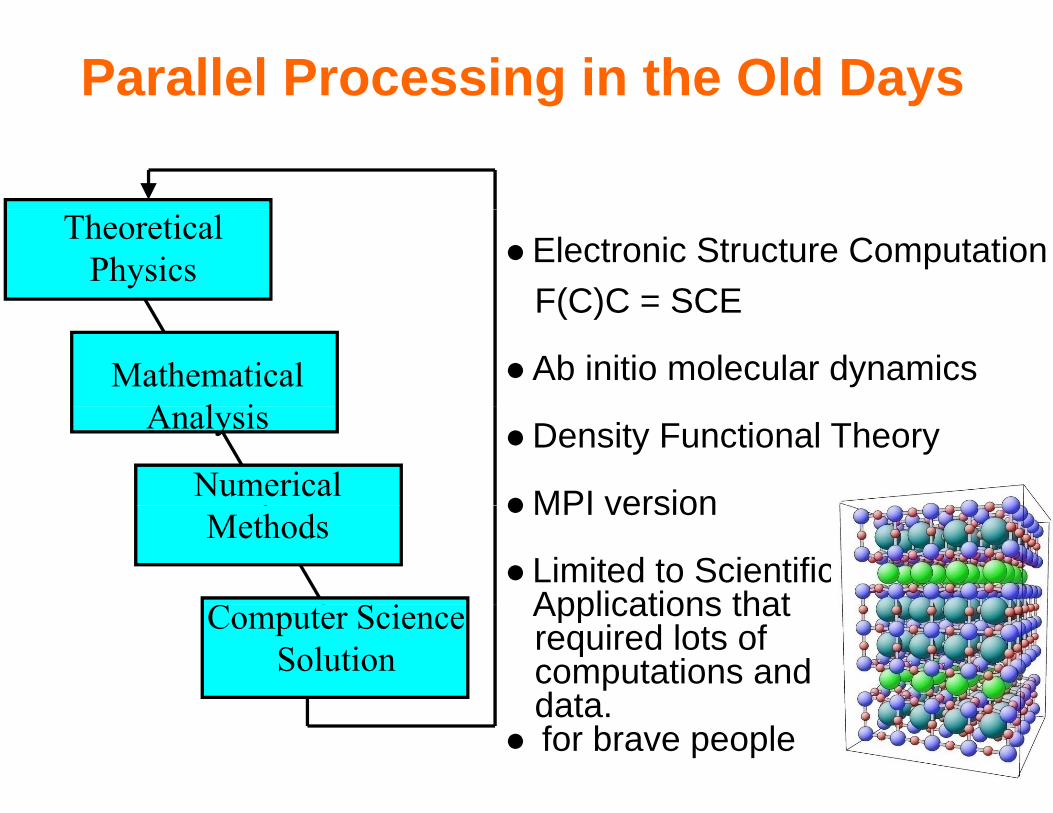
Parallel Processing in the Old Days
Theoretical Physics Electronic Structure Computation
F(C)C = SCE
Mathematical A l i
F(C)C SCE
Ab initio molecular dynamics Analysis
Numerical Density Functional Theory
MPI version with AskalonMethods
MPI version with Askalon
Limited to ScientificApplications thatComputer Science
SolutionApplications that required lots of computations and datadata.
for brave people

3
Parallel ProcessingB M i (1)
• Parallel processing becomes mainstream
Becomes Mainstream (1)• Parallel processing becomes mainstream
– Sony Playstation 3
M lti hit t• Multi-core architectures– Nr. of cores will double every 12 to 18 months
I 5 64 hi– In 5 years 64 cores on a chip
Sun Sparc T2 processor with 8 cores
IBM cell processor with 8 cores in Ps3

4
Parallel ProcessingB M i (2)
• All PCs ser ers notebooks game consoles ill come ith
Becomes Mainstream (2)• All PCs, servers, notebooks, game consoles will come with
processors that contain larger number of cores (probably up to 1000)to 1000)
• Major hardware and software companies will get problems– If they can’t figure out how the masses can benefit by these cores– No one wants to pay for 1000 cores on a notebook if only
a few cores are useda few cores are used– Benefit for price must be justified– This will be a major problem for Intel IBM Microsoft SAPThis will be a major problem for Intel, IBM, Microsoft, SAP, …
• We all have to learn how to make use of parallelism and how to create programs for parallel systems for everydayto create programs for parallel systems for everyday applications (software) on everyday’s computers.

5
Course Goals• Introduction to parallel architectures• Difference between conventional and parallel
systems and programming.y p g g– MPI programming– OpenMP programmingp p g g
• Performance oriented programming• Optimization for serial computers• Optimization for serial computers• Hands-on sessions with real parallel architectures
dand programs.• …aimed at producing and maintaining medium
sized software systems.

7
Books• Parallel Programming in C with MPI and OpenMP
Michael J Quinn McGraw HillMichael J. Quinn, McGraw Hill
• Parallel Computer Architecture: A H d /S ft A h Hardware/Software Approach David E. Culler, Jasweinder Pal Singh, Anoop Gupta, Morgan Kaufmann, 1999
• Designing and Building Parallel Programs Ian Foster, www.mcs.anl.gov/dbpp, g / pp

8
Webpagep g
The course web page is atp g
dps.uibk.ac.at/~tf/lehre/ss11/psdps.uibk.ac.at/ tf/lehre/ss11/ps
Th i l ili li t f thi There is also a mailing list for this course.Please register for it.They will be used for announcements and distribution of material.

9
Demand for Computational SpeedDemand for Computational Speed• Continuous demand for greater computational speed from Co t uous de a d o g eate co putat o a speed o
a computer system than is currently possible
• Areas requiring great computational speed include numerical modeling and simulation of scientific and engineering problems.
• Computations must be completed within a “reasonable” time period.

10
Grand Challenge ProblemsgOne that cannot be solved in a reasonable amount of time with today’s computers. Obviously, an execution time of 10 years is always unreasonable.
ExamplesExamples• Modeling large DNA structures
Gl b l h f i• Global weather forecasting• Modeling motion of astronomical bodies.

11
Motivating Example: Weather g pForecasting
• Atmosphere modeled by dividing it into 3-dimensional cells.
• Calculations of each cell repeated many times to model passage of time.p g

12
Global Weather Forecasting ExampleGlobal Weather Forecasting Example
• Suppose whole global atmosphere divided into cells of size 1 mile 1 mile 1 mile to a height of 10 miles (10 cells high) -b t 5 108 llabout 5 108 cells.
• Suppose each calculation requires 200 floating point operations. In one time step 1011 floating point operations necessaryIn one time step, 1011 floating point operations necessary.
• To forecast the weather over 7 days using 1-minute intervals, a computer operating at 1Gflops (109 floating point operations/s)computer operating at 1Gflops (10 floating point operations/s) takes 106 seconds or over 10 days.
• To perform calculation in 5 minutes requires computer operatingTo perform calculation in 5 minutes requires computer operating at 3.4 Tflops (3.4 1012 floating point operations/sec).

13
Motivating Example: Modeling Motion of Astronomical Bodies
• Each body attracted to each other body by gravitationalEach body attracted to each other body by gravitational forces. Movement of each body predicted by calculating total force on each bodytotal force on each body.
With N b di N 1 f t l l t f h b d• With N bodies, N - 1 forces to calculate for each body, or approx. N2 calculations. (N log2 N for an efficient
l ith )approx. algorithm.)
• After determining new positions of bodies, calculations repeated.p

14
• A galaxy might have, say, 1011 stars.
• Even if each calculation done in 1 ms (extremely optimistic figure), it takes 109 years for one iteration using N2 algorithm and almost a year for one iteration using an efficient N log N approximate algorithmefficient N log2 N approximate algorithm.
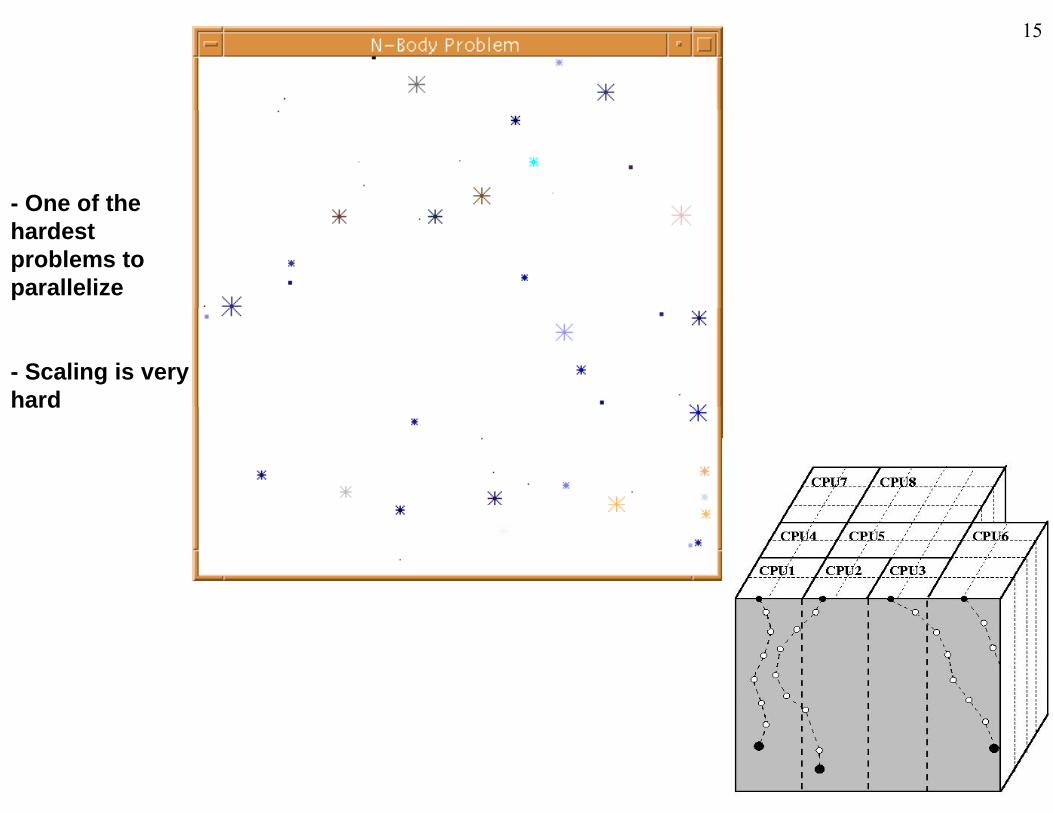
15
- One of theOne of the hardest problems to parallelize
- Scaling is very hardhard

20
Parallel Computingp g
• Using more than one computer, or a computer with more than one processor (or core) to solve a problemone processor (or core), to solve a problem.
Motives• Usually faster computation - very simple idea - that n computers y p y p p
operating simultaneously can achieve the result n times faster - it will not be n times faster for various reasons.
• Other motives include: fault tolerance, larger amount of memory available, ...

23
Backgroundg
• Parallel computers - computers with more thanParallel computers computers with more than one processor - and their programming - parallel programming - has been around for a long time.programming has been around for a long time.

24
History of Parallel Computing (1)Gill writes in 1958:
y p g ( )
“... There is therefore nothing new in the idea of parallel programming but its application to computers The author cannotprogramming, but its application to computers. The author cannot believe that there will be any insuperable difficulty in extending it to computers. It is not to be expected that the necessary programming p p y p g gtechniques will be worked out overnight. Much experimenting remains to be done. After all, the techniques that are commonly used i i d l h f id bl ilin programming today were only won at the cost of considerable toil several years ago. In fact the advent of parallel programming may do something to revive the pioneering spirit in programming whichsomething to revive the pioneering spirit in programming which seems at the present to be degenerating into a rather dull and routine occupation ...”p
Gill, S. (1958), “Parallel Programming,” The Computer Journal, vol. 1, April, pp. 2-10.

25
History of Parallel Computing (2)
Parallel Computing can be traced to a tabletParallel Computing can be traced to a tablet dated around 100 BC.
Tablet has 3 calculating positions– Tablet has 3 calculating positions.– Infer that multiple positions improved:
• ReliabilityReliability• Speed

26
Why Parallel Processing?y g
Computation requirements are ever i i i li i di ib dincreasing -- visualization, distributed databases, simulations, scientific , ,prediction (earthquake), gaming, web
h i tservers, search engines, etc.
T di i l f f i l Traditional software for serial computationp

27
Why Parallel Computers?y p• Performance growth of single processors cannot
be sustained indefinitely:– speed of light– limits of miniaturization (nr. of transistors per chip)– economic limitations– thermodynamics– DRAM latency
i d l– wire delays– diminishing returns on more instruction level parallelism
C i l i l ff h h lf i• Connecting multiple off-the-shelf processors is a logical way to gain performance beyond that of a i lsingle processor.
• Or putting multiple cores onto a single chip

31
Why Parallel Processing?Why Parallel Processing?
Hardware improvements like pipelining,superscalar, etc., are non-scalable and requiresuperscalar, etc., are non scalable and requiresophisticated compiler technology.
Vector processing works well for certain kindof problems.p
Multi-core technology is currently theeconomically best way forward to increaseperformance
virtually every HW will build on multicore technology
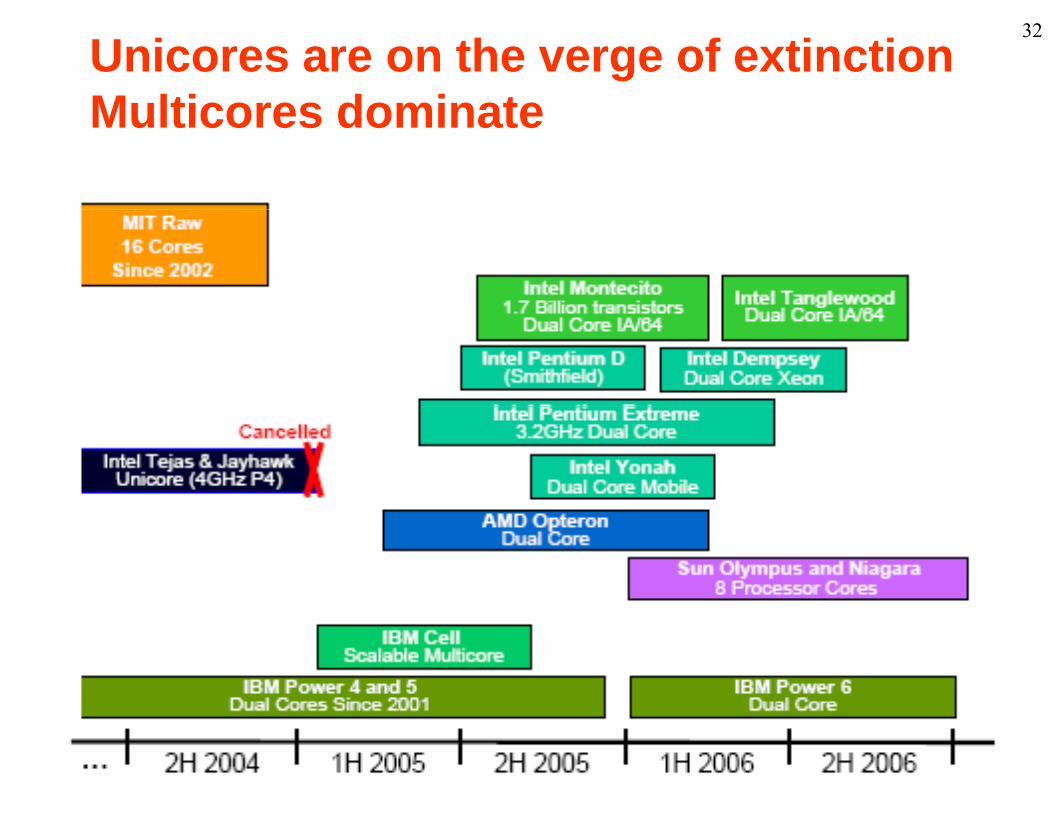
Unicores are on the verge of extinction Multicores dominate
32
Multicores dominate

36
Why use Parallel Computing?y p g
• save time – wall clock timel l bl• solve larger problems
• increased extensibility and configurability• possible better fault tolerance• cost savingscos s v gs• overcoming memory constraints
scientific interest• scientific interest

37
Speedup Factorp p
S(p) = Execution time using one processor (best sequential algorithm)Execution time using a multiprocessor with p processors
=ts
tp
where ts is execution time on a single processor and tp is execution ti ltitime on a multiprocessor.
S(p) gives increase in speed by using multiple processorsS(p) gives increase in speed by using multiple processors.
Use best sequential algorithm with single processor system instead ofUse best sequential algorithm with single processor system instead of parallel program run with 1 processor for ts. Underlying algorithm for parallel implementation might be (and is usually) different.

38
Speedup factor can also be cast in terms ofSpeedup factor can also be cast in terms of computational steps:
S(p) = Number of computational steps using one processorN b f ll l t ti l t ith
(p)Number of parallel computational steps with p processors

39
Maximum Speedupp pMaximum speedup is usually p with p processors (linear speedup).
Possible to get superlinear speedup (greater than p) but usually a specific reason such as:but usually a specific reason such as:
E i l i• Extra memory in multiprocessor system• Nondeterministic algorithm
40
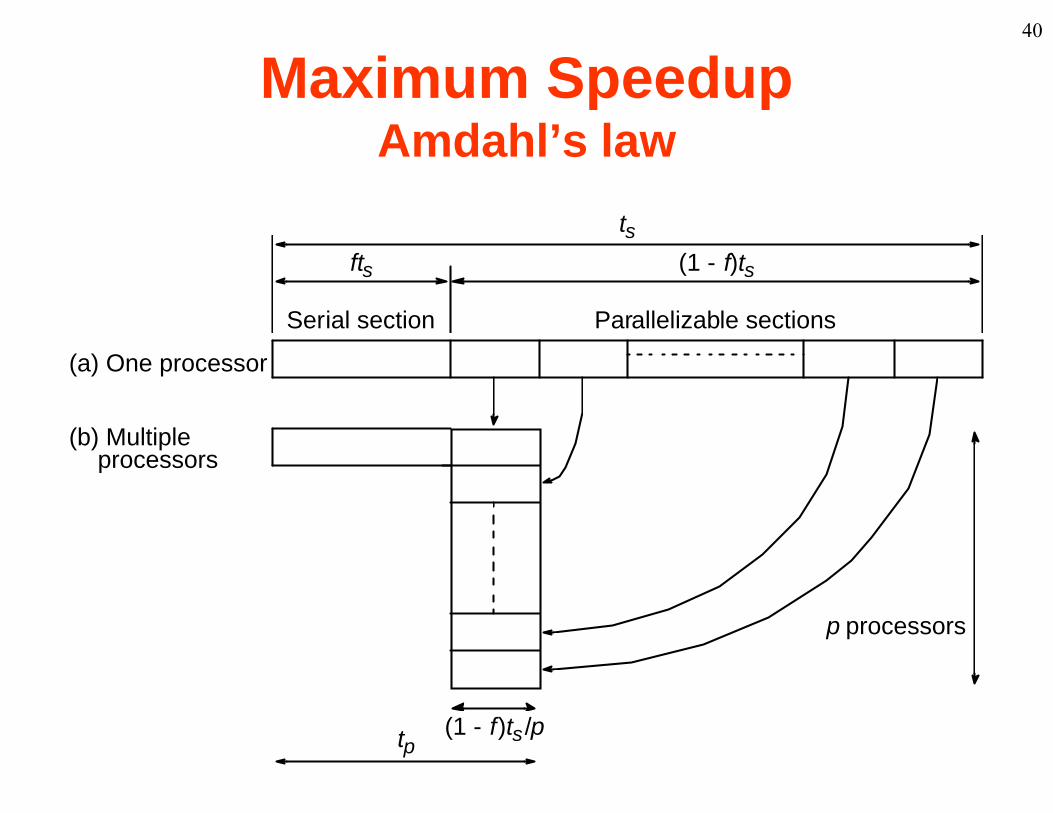
Maximum Speedup Amdahl’s law
fts (1 - f)ts
ts
Serial section Parallelizable sections
(a) One processor
(b) Multipleprocessors
p processors
(1 - f)ts /ptp

41
Speedup factor is given by:Speedup factor is given by:
S(p) ts pS(p) pfts (1 f )ts /p 1 (p 1)f
This equation is known as Amdahl’s law
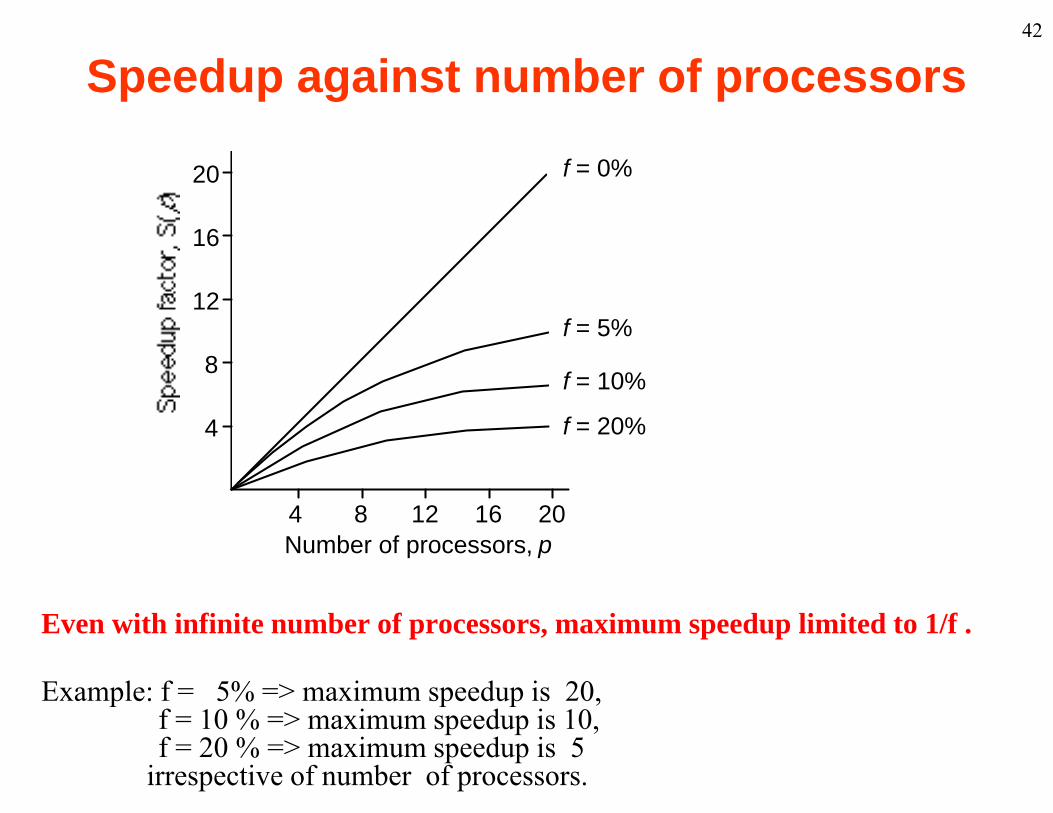
42
Speedup against number of processors
20 f = 0%
12
16
8
12
f = 10%
f = 5%
4
4 8 12 16 20
f = 20%
4 8 12 16 20Number of processors, p
Even with infinite number of processors, maximum speedup limited to 1/f .
Example: f = 5% => maximum speedup is 20,p p p ,f = 10 % => maximum speedup is 10,f = 20 % => maximum speedup is 5
irrespective of number of processors.
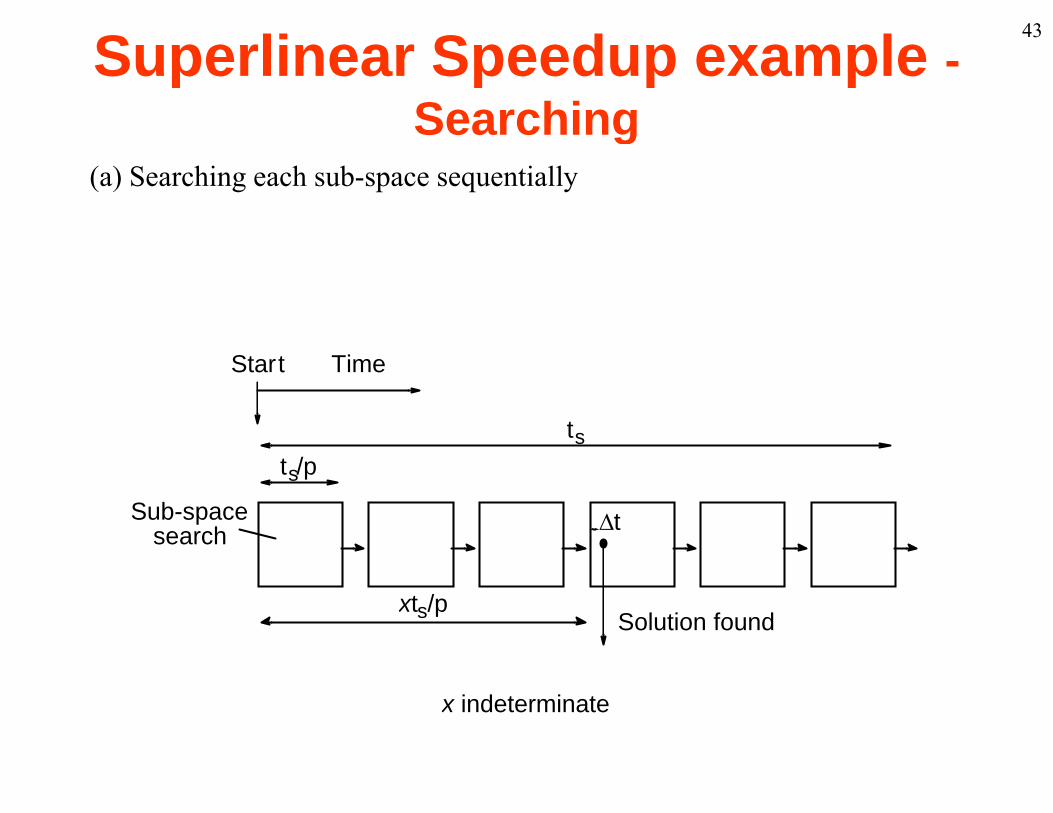
43Superlinear Speedup example -SearchingSearching
(a) Searching each sub-space sequentially
Start Time
tsts/p
S b t
xt /p
Sub-spacesearch
Solution foundxts/p
x indeterminatex indeterminate

44
(b) Searching each sub-space in parallel
t
Solution found
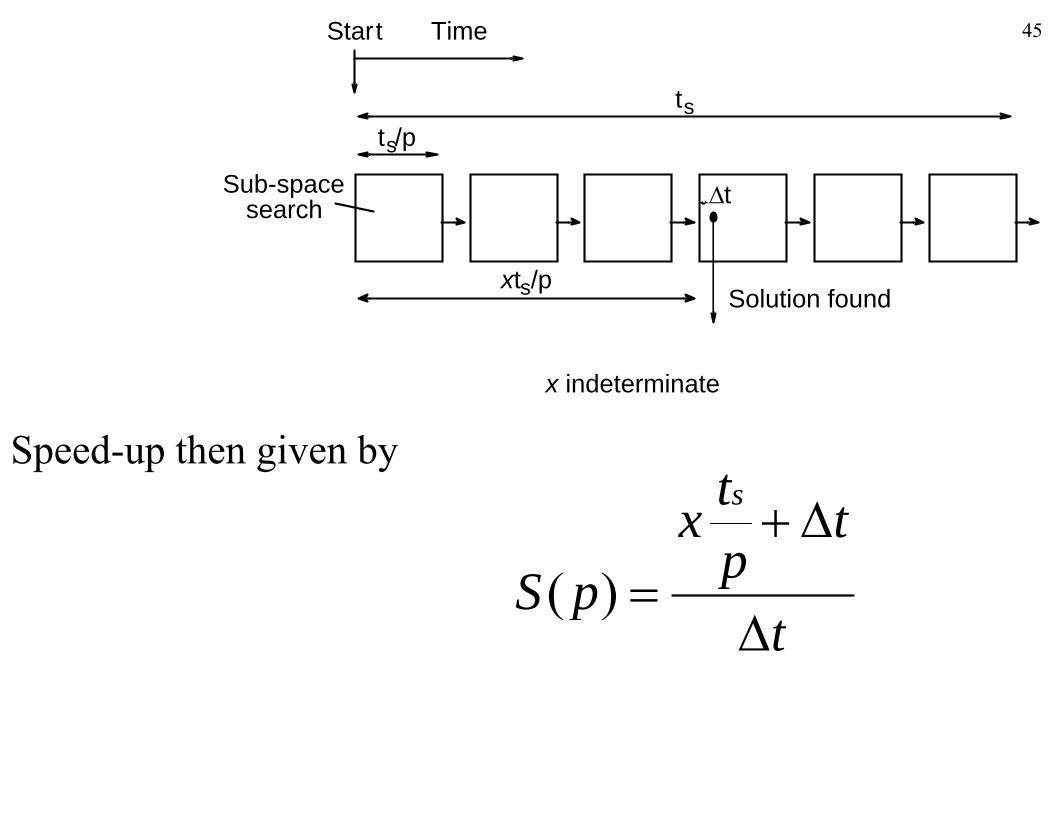
45
ts
Start Time
sts/p
tSub-spacesearch
Solution foundxts/p
search
x indeterminate
Speed-up then given byts
tp
xpS
)(
tpS
)(

46
Worst case for sequential search when solution found in last sub-space search. Then parallel version
ff b fi ioffers greatest benefit, i.e.
1
ttps
)(
t
ppS
2 as low as p with zero tot tends
ast

47
L d f ll l i h l iLeast advantage for parallel version when solution found in first sub-space search of the sequential
h isearch, i.e.
1)( tS 1)(
ttpS
Actual speed-up depends upon which subspace holds solution but could be extremely large.y g

48
Parallel Computersp• Task system: Set of tasks with a dependence
relation solving a given problem. • Concurrent: 2 tasks are called concurrent, if they , y
are not dependent on each other. • Simultaneous/parallel: 2 tasks are executed inSimultaneous/parallel: 2 tasks are executed in
parallel if at some point in time both tasks have been started and none terminatedbeen started and none terminated.
• Parallel computer: Computer executing concurrent tasks of task systems in paralleltasks of task systems in parallel.

51Computer ArchitectureParallelism for PerformanceParallelism for Performance
• Processor• Processor– Bit-level up to 128 Bit
Instruction level: pipelining functional units– Instruction-level: pipelining, functional units– Latency gets very important, branch-prediction– Latency ToleranceLatency Tolerance– Multi-core technology
• Memory: multiple memory banks• Memory: multiple memory banks• IO: hardware DMA, Raid arrays
l i l hi• Multiple chips

52
Parallelism within a Processora a e s t a ocesso

53
What is a Processor? • A single chip package that fits in a socket• A multi-core CPU combines independent processors or cores onto a single
silicon chipsilicon chip.• ≥1 core (not much point in <1 core…)
– Cores can have functional units, cache, etc.associated ith them j st as todaassociated with them, just as today
– Cores can be fast or slow, just as today• Shared resources
– More cache– Other integration: Northbridge, memory controllers, high-speed serial links, etc.
• One system interface no matter how many coresy y– Number of signal pins doesn’t scale with number
of cores• OS is aware of multiple coresp

56
A Multi-Core Processor
• Quad-core AMD Phenom™ processor is 285mm2processor is 285mmin 65nm
• Single-core AMD Opteron g pprocessor is 193mm2
in 130nm• Reducing Gigaherz to 10 or
20 % can cause reduction in ti f tpower consumption of up to
40 %.

Multi-Core Processor ArchitectureQuad Core AMD Phenom
57
Quad Core AMD Phenom

60
Parallel ArchitecturesSGI Power Challenge XLSGI Power Challenge XLIBMIBM RS/6000 SPRS/6000 SP
NEC SXNEC SX--5 multi node 5 multi node (8 CPUs pro Knoten)(8 CPUs pro Knoten)(8 CPUs pro Knoten)(8 CPUs pro Knoten)
Earth SimulatorEarth Simulator(540*8 CPUs)(540*8 CPUs)

Altix 4700

ccNUMA Architecture• Distributed Memory - Shared address space

Altix HLRB II – Phase 2• 19 partitions with 9728 cores
– Each with 256 Itanium dual-core processors, i.e., 512 cores• Clock rate 1.6 GHz
4 Fl l• 4 Flops per cycle per core• 12,8 GFlop/s (6,4 GFlop/s per core)
– 13 high-bandwidth partitionsg p• Blades with 1 processor (2 cores) and 4 GB memory• Frontside bus 533 MHz (8.5 GB/sec)
– 6 high-density partitions• Blades with 2 processors (4 cores) and 4 GB memory.• Same memory bandwidth.Same memory bandwidth.
• Peak Performance: 62,3 TFlops (6.4 GFlops/core)• Memory: 39 TB• Memory: 39 TB

Memory Hierarchyy y• L1D
– 16 KB, 1 cycle latency, 25,6 GB/s bandwidth – cache line size 64 bytes
• L2D– 256 KB, 6 cycles, 51 GB/s– cache line size 128 bytes
• L3– 9 MB, 14 cycles, 51 GB/s– cache line size 128 bytes

Interconnect• NUMAlink 4
– 2 links per blade– Each link 2*3,2 GB/s bandwidth– MPI latency 1-5µs

Disks• Direct attached disks (temporary large files)
– 600 TB– 40 GB/s bandwidth
• Network attached disks (Home Directories)– 60 TB– 800 MB/s bandwidth

Environment• Footprint: 24 m x 12 m• Weight: 103 metric tons• Electrical power: ~1 MW (~3 MW with cooling)Electrical power: 1 MW ( 3 MW with cooling)

NUMAlink Building Blockg
NUMALink 4 NUMALink 4NUMALink 4RouterLevel 1
NUMALink 4RouterLevel 1
8
BLA
BLA
BLA
BLA
IO
B
BLA
BLA
BLA
BLA
IO
B
SANSwitch
PCI/FC8 cores (high bandwidth) 16 cores (high-density)
DE
DE
DE
DE
BLADE
DE
DE
DE
DE
BLADE
10 GEE E
NUMALink 4RouterLevel 1
NUMALink 4RouterLevel 1
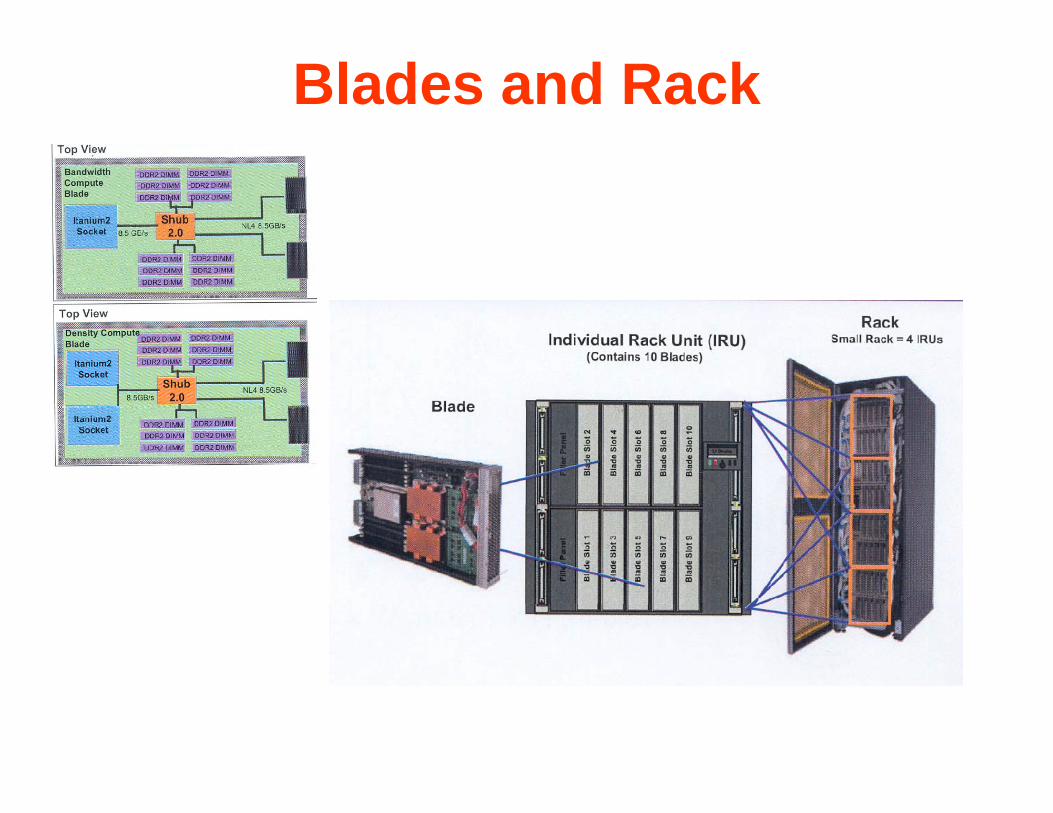
Blades and Rack
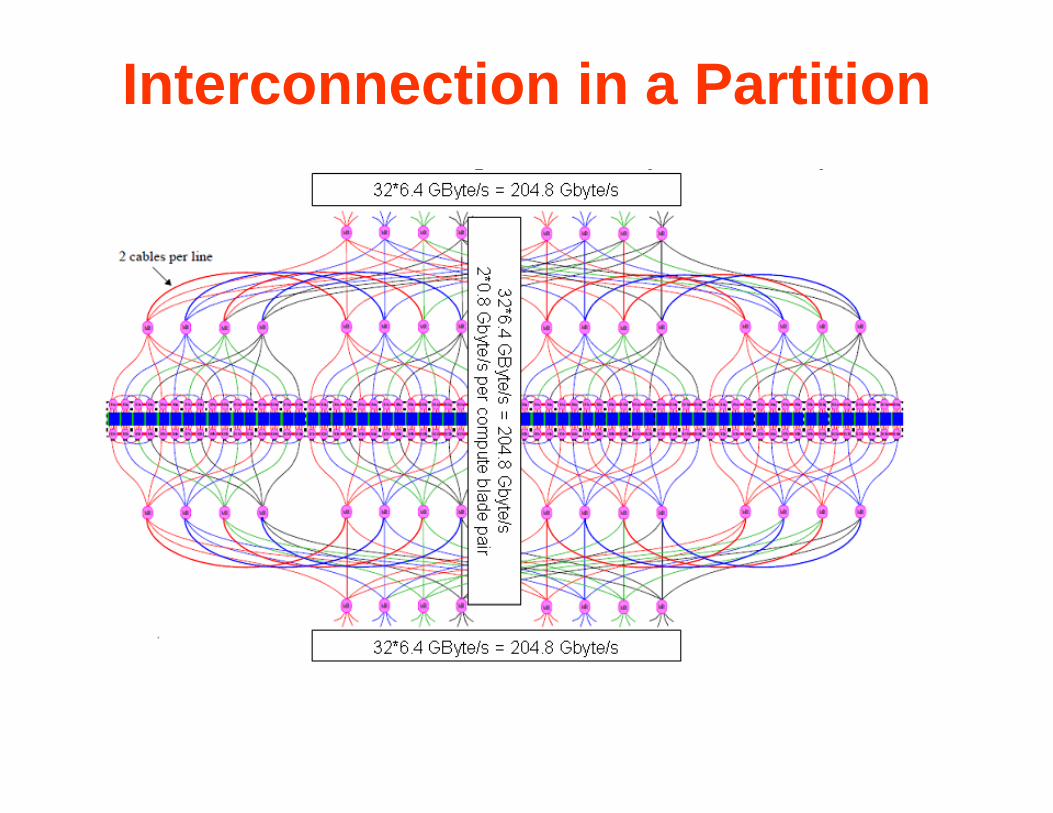
Interconnection in a Partition
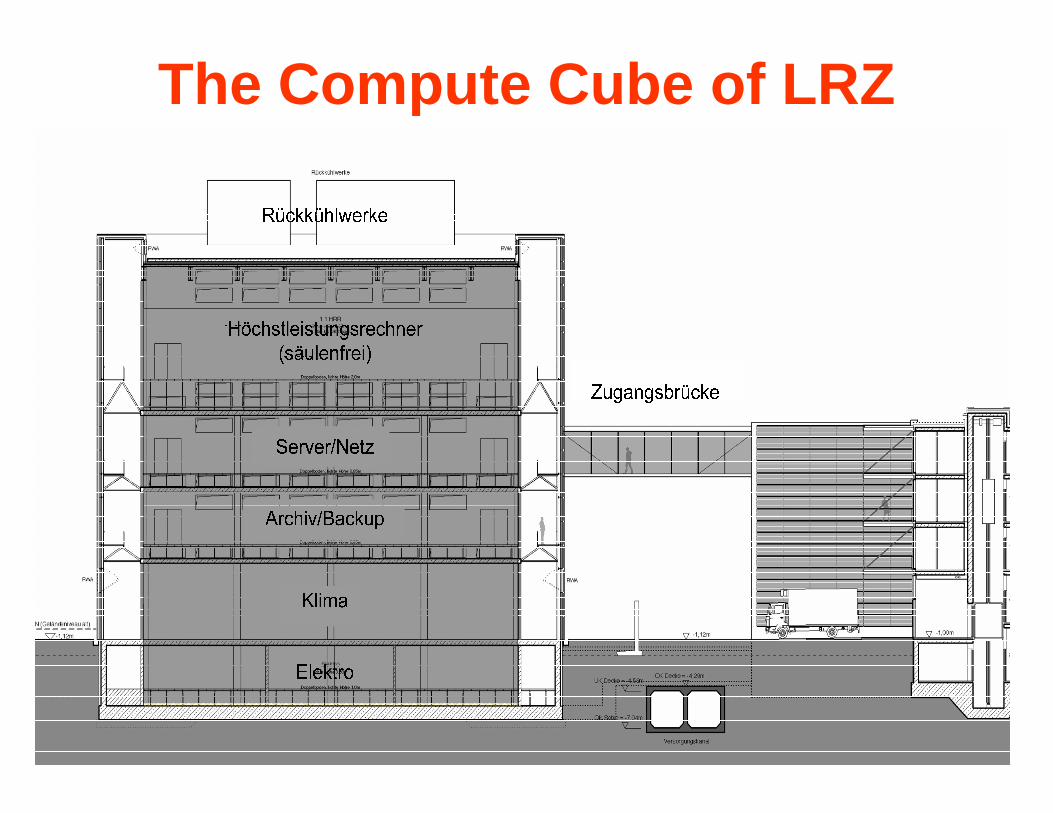
The Compute Cube of LRZp

87
ApplicationsppMany applications can be expressed as a graph:• Nodes: computations• Edges: dependenciesEdges: dependenciesA few difficulties with the graph model:
B h• Branches• Loops• Programming languages introduce artificial dependenciesp

88
Granularityy• Microoperations: parallelism within an instruction exploited by
control unitcontrol unit. • Instructions:parallelism between instructions exploited by pipeline,
superscalar architectures.• Basic Blocks : in practice parallelism between loop iterations
exploited via multithreading, multiple processors/cores.• Program modules: functional parallelism exploited by multiple• Program modules: functional parallelism exploited by multiple
processors.

90
Regularity versus Irregularityg y g y
• Data Structures: dense vectors/matrices versus sparse (stored as such) matrices(stored as such) matrices
• Data access: regular vector access (with strides) versus indirect access (scatter/gather)indirect access (scatter/gather).
• Computation: uniform computation on a grid versus highly dependent upon grid point computation.g y p p g p p
• Communication: regular communication versus highly irregular graphs.

91
Static versus Dynamic Program Structure and Behavior
STATIC• Data structure,
DYNAMIC• Data structure, ,
communication, etc. remains constant over i
,communication, etc. varies over time
time• Can be analyzed at
il ti
• Need for run time support
compile time

92
Communication Structure
• LOCAL: neighbor type communication• GLOBAL: everyone communicates with
everyoneIn practice, mixture of both!!

93
Architecture Application Matchpp
• Architectures are good at uniform and regular, coarse grain computations with local communications, everything being static of course.
• Everything else generates problems!y g g p• Computer architects assumptions:
Software will solve it!Software will solve it!• Challenging problems are left to software
d ldevelopers

94
Interaction in Parallel Systemsy• Programming Model specifying the interaction
abstraction– Shared Memory
• Global addresses• Explicit synchronization
M P i– Message Passing• Explicit exchange of messages• Implicit synchronizationImplicit synchronization
• Communication hardwareShared memory (Bus based shared memory systems– Shared memory (Bus-based shared memory systems, Symmetrical Multiprocessors – SMPs)
– Message passing (network based such as Myrinet, g p g ( y ,Infiniband, Quadrics, etc.)

96Parallel Architectures: ClassificationClassification
• historical classification:– flow of instruction: 1 or multiplep– flow of data operated upon: 1 or multiple
• SISD (Single Instruction Single Data): conventional serial approachP ll l t• Parallel systems
– Parallel computers• SIMD (Single Instruction Multiple Data): Synchronized execution of the same instruction
on a set of ALUMISD (S li A )• MISD (Systolic Arrays)
• MIMD (Multiple Instruction Multiple Data): Asynchronous execution of different instructions.
– Computer networksN t k f k t ti NOW N d di t d hi h f t k• Networks of workstations - NOW: No dedicated high-performance network.
• Clusters: Collection of off-the-shelf processors dedicated to parallel computing with a dedicated high-performance network.
• Grids: Collection of resources, including parallel computers, building a virtual high-performance system.performance system.
• M. Flynn, Very High-Speed Computing Systems, Proceedings of the IEEE, 54, 1966

98
SISD : A Serial Computerp
Insttructions
D O
s
ProcessorData Input Data Output
Speed is limited by the rate at which computer can p y ptransfer information internally.
Ex: PC, Macintosh, Workstations many years ago

99
The MISD ArchitectureInstructionStream A
InstructionS
Processor
Stream BInstruction Stream C
Data
Data OutputStream
ProcessorA
ProcessorInputStream
StreamProcessorB
Processor
More of an intellectual exercise than a practical configuration
C
More of an intellectual exercise than a practical configuration. Few built, but commercially not available
100
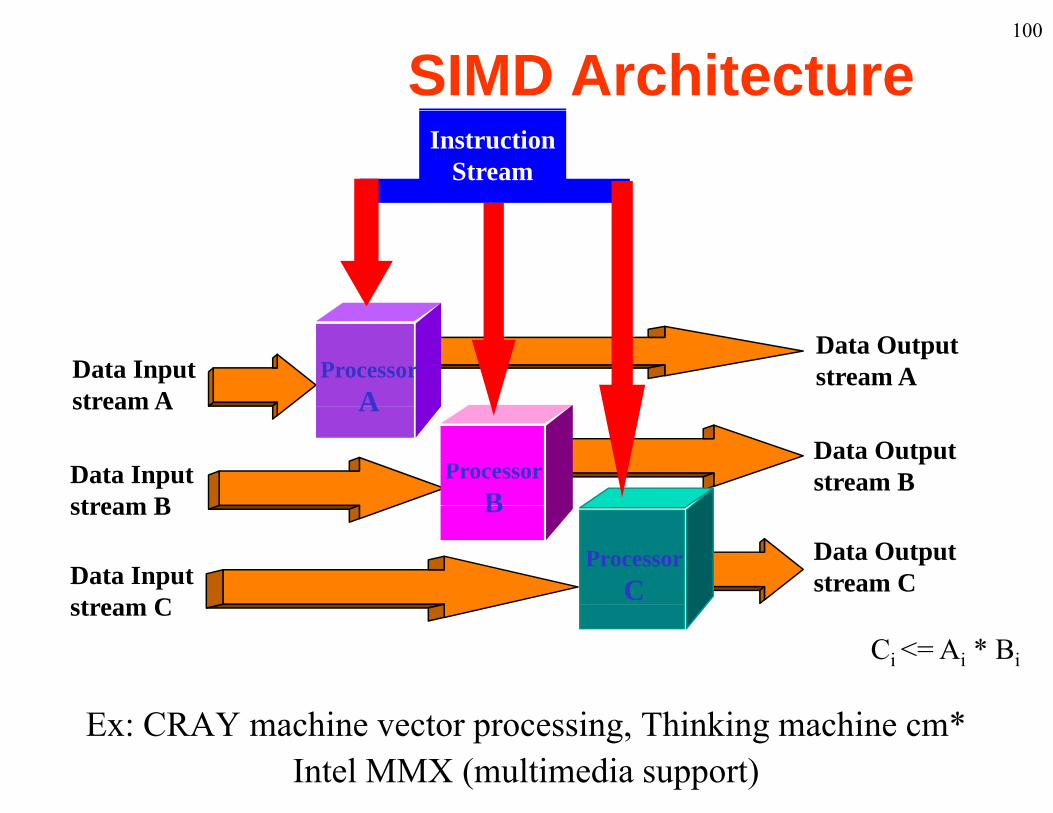
SIMD ArchitectureInstruction
Stream
ProcessorA
Data Inputstream A
Data Outputstream A
A
ProcessorB
stream A
Data Inputstream B
Data Outputstream B
B
ProcessorC
stream B
Data Inputstream C
Data Outputstream C
Ci <= Ai * Bi
stream C
Ex: CRAY machine vector processing, Thinking machine cm*Intel MMX (multimedia support)

101
SIMDLIMITATIONS:ADVANTAGES:• Regularity• Uniformity
• 1 Control Unit• Simple architecture
• Specialized• Exploits parallelism from bit level up to i t ti l linstruction level
Well suited for vector (data parallel) algorithms.
Nowadays, its use is limited to image and signal processing. (appears as coprocessor and in embedded systems)

102
MIMD ArchitectureInstructionStream A
InstructionS B
InstructionSt CStream A Stream B Stream C
ProcessorA
Data Inputstream A
Data Outputstream A
ProcessorB
Data Inputstream B
Data Outputstream B
ProcessorCData Input
stream C
Data Outputstream C
Unlike SISD and MISD, a MIMD computer works asynchronously.Shared memory (tightly coupled) MIMDShared memory (tightly coupled) MIMD
Distributed memory (loosely coupled) MIMD
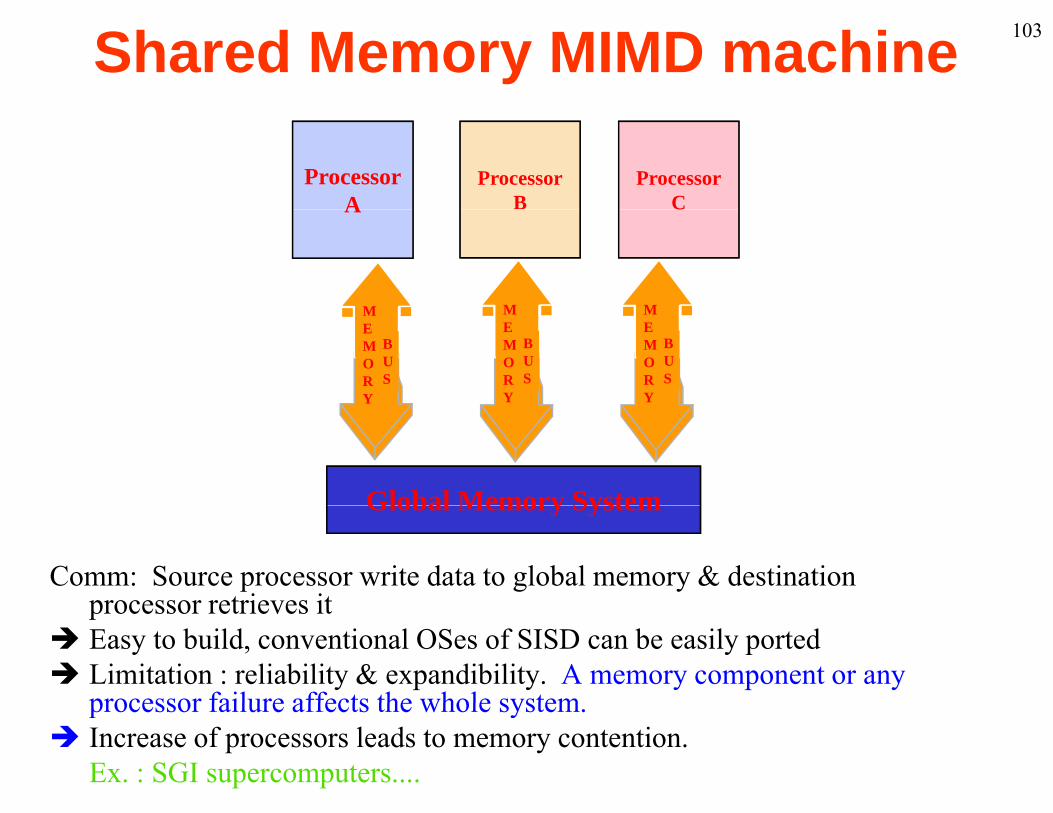
103Shared Memory MIMD machine
ProcessorA
ProcessorB
ProcessorC
M M
A C
MMEMORY
BUS
MEMORY
BUS
MEMORY
BUS
Global Memory System
Comm: Source processor write data to global memory & destination processor retrieves it
Global Memory System
processor retrieves it Easy to build, conventional OSes of SISD can be easily ported Limitation : reliability & expandibility. A memory component or any
processor failure affects the whole systemprocessor failure affects the whole system. Increase of processors leads to memory contention.
Ex. : SGI supercomputers....

104
Memory View (1)y ( )
GLOBAL ADRESS SPACE
XX
WRITEREAD
WRITE

Example for Shared Memory MIMD105
p y
SMP clusters (Uniform Memory Access - UMA):– centralized shared memory, accesses to global memory from
all processors have same latency.

107
Shared Memory MIMDyADVANTAGES DISADVANTAGES• Multiple control units• Exploits parallelism above
• hw and sw implementation• scalability
instruction level• simplicity for
i i
• performance• hardware faults
programming, managing resources and compiling

108
Distributed Memory MIMDIPC
channelIPC
channel
ProcessorA
ProcessorB
ProcessorC
MEMO
BUS
MEMO
BUS
MEMO
BUSR
Y
S RY
SRY
S
MMemorySystem A
MemorySystem B
MemorySystem C
Communication : IPC on High Speed Network. Network can be configured to ... Tree, Mesh, Cube, etc.

110
Memory View y
X XCOPY!
READ

111
Disjoint Address Space j p
ADVANTAGES DISADVANTAGES• Simple to develop• Performance (local
• Difficulty of programming• Performance (remote
access)• easily/ readily expandable
access)
• highly reliable (any CPU failure does not affect the
h l t )whole system)

112
Variants• Combination of both concepts
– Disjoint address space (local memory) + Global address space– Two level architectures: subsets of processors having a global
shared space limited to that subset!!shared space limited to that subset!!
• Shared Virtual Memory: at the programmer’s level, the memory space is shared but at the physical level, address spaces are disjoint.
e.g. KSR-1

113
NUMA (non-uniform memory access) S tSystems
• every processor has memory and cachey p y• all memories form a global address space• local access is much faster than remote access
• Cache-coherent NUMA - ccNUMA: Home location of d i fi d i f h d d i h hdata is fixed. Copies of shared data in the processor caches are automatically kept coherent, i.e. new values are automatically propagated. (SGI Origin/Altix 3000/ASCIautomatically propagated. (SGI Origin/Altix 3000/ASCI Blue Mountain, Convex SPP)
• Non-cache-coherent NUMA - nccNUMA: Home location of data is fixed. Copies of shared data are independent of original location. (Cray T3E)
• Cache only memory COMA: Data migrate between• Cache-only memory - COMA: Data migrate between memories of the nodes, i.e. home location can be changed. (KSR-1 computer)
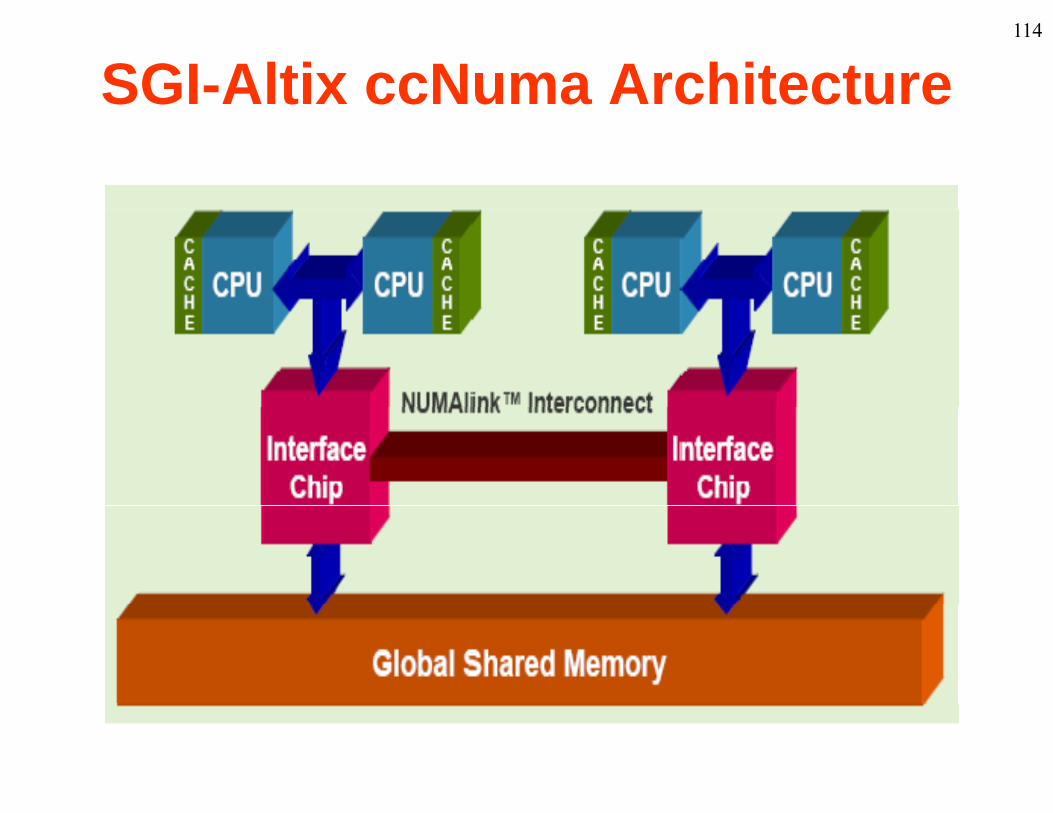
114
SGI-Altix ccNuma Architecture

115
COMA Architecture
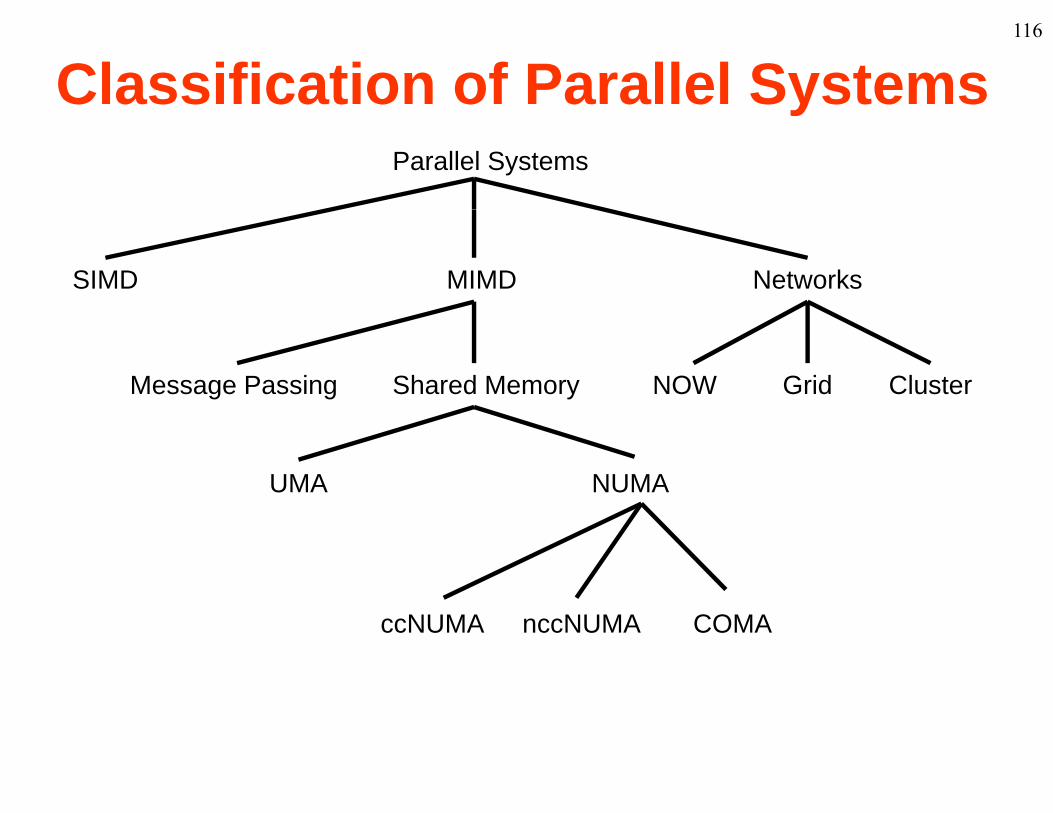
116
Classification of Parallel SystemsyParallel Systems
SIMD MIMD Networks
Message Passing Shared Memory NOW Grid Cluster
UMA NUMA
ccNUMA nccNUMA COMA

118
TOP 500• www.top500.org• 500 most powerful computer systems installed
around the world• Linpack benchmark performance
– Number of floating point operations is determined byNumber of floating point operations is determined by standard linpack.

120
source: Jack Dongarra

121
Fastest Computer on Top 500p pTianhe-1a system at National Supercomputer Centre in Tianjin achieving 2.57 petaflop/sg p p
• 186.368 Cores– 14 336 Xeon X5670 processors– 14.336 Xeon X5670 processors– 7.168 Nvidia Tesla M2050 general purpose GPUs
2048 NUDT FT1000 heterogeneous processors– 2048 NUDT FT1000 heterogeneous processors• architecture:
112 compute cabinets 12 storage cabinets 6 communication cabinets– 112 compute cabinets, 12 storage cabinets, 6 communication cabinets, 8 IO cabinets
– total memory size: 262 Terabytesy y– total disc storage: 2 Petabytes
•Consumes 4 Megawatts• runs under Linux

123
Parallel Computer Architecturesp• MPP – massively parallel processors
– Build with specialized networks by vendors• Clusters
– Simple cluster (1 processor in each node)– Cluster of small SMP‘s (small # processors / node)
Constellations (large # processors / node)– Constellations (large # processors / node)– Usually cheaper than MPPs with slower communication than
in MPPs (but catching up)– Commodity off the shelf components rather than custom
architecturesOld hit t• Older architectures– SIMD – single instruction multiple data
Vector processors– Vector processors
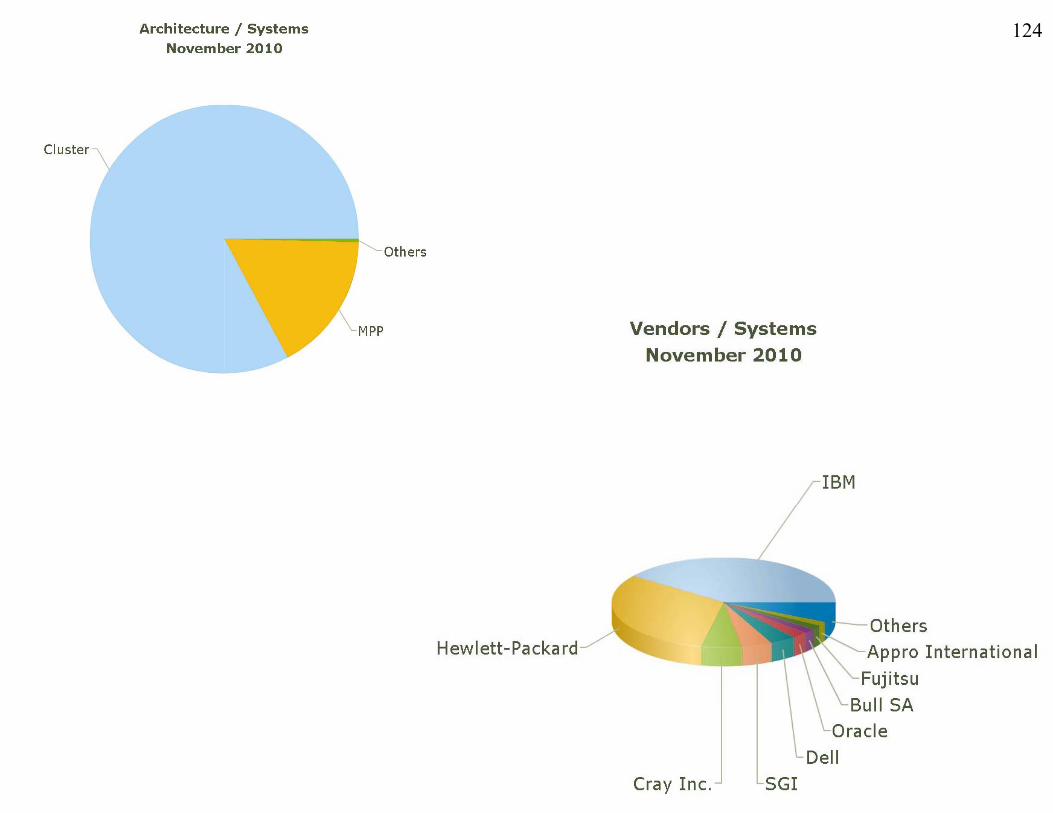
124
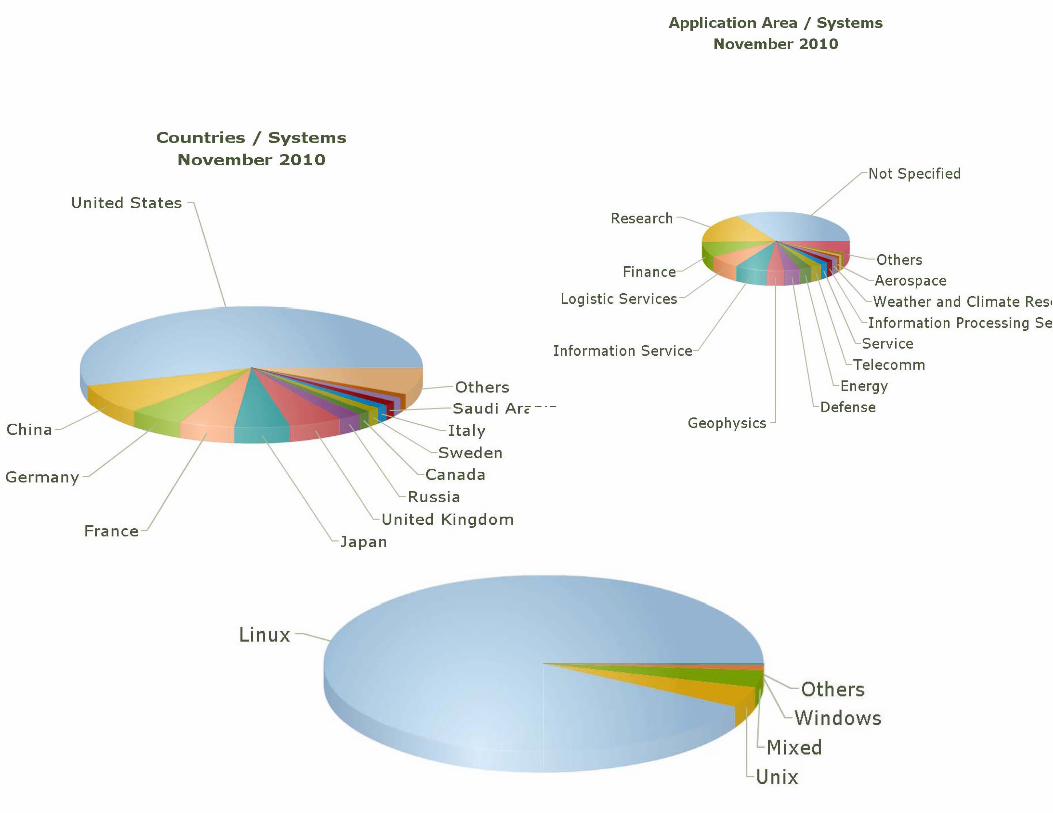
125
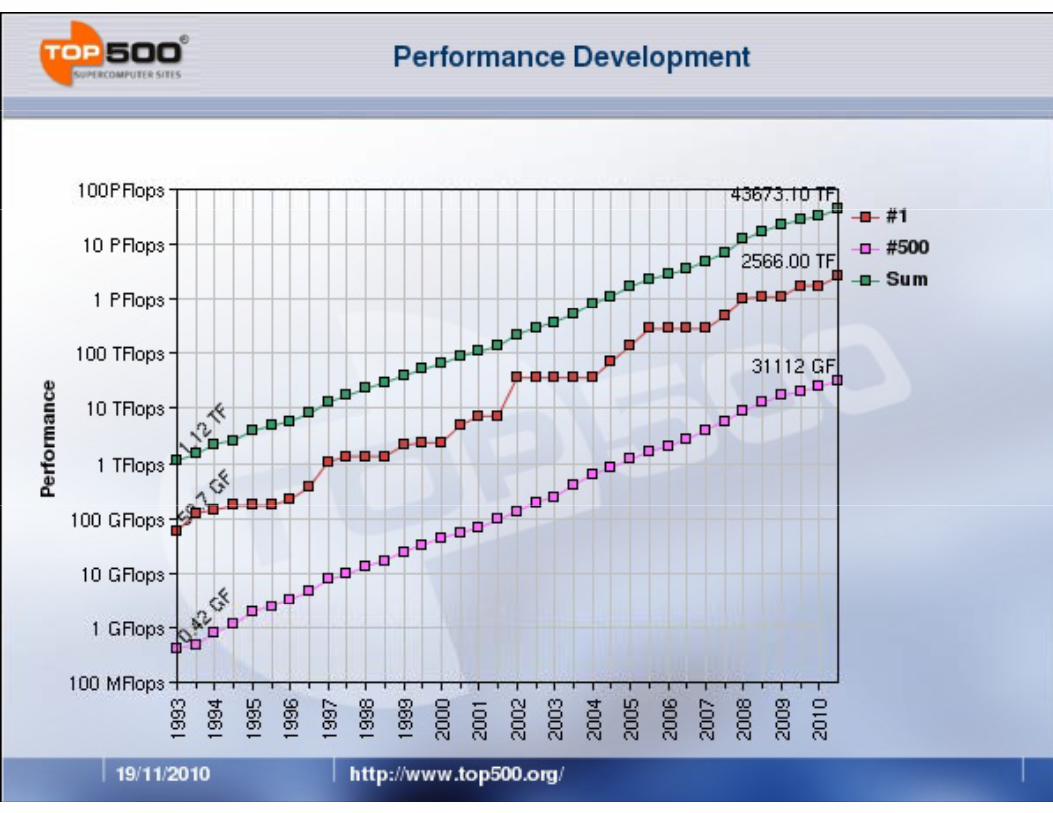
126

127Timeline of Top-Performance SupercomputersSupercomputers
• 1 Gflop/s 1988; Cra Y M; 8 Processors• 1 Gflop/s 1988; Cray Y-M; 8 Processors• 1 Tflop/s; 1998; Cray T3E; 1024 Processors• 1 Pflop/s; 2008; Cray XT5; 1.5x105 Processors• 1 Eflop/s; ~2018; ?; 1x107 Processors (109 threads)p ; ; ; ( )
source: J. Dongarra

132
Caution....• Even well-defined distinctions like shared
memory and distributed memory are merging dueto ne ad ances in technolgto new advances in technolgy.
• Good environments for developments and• Good environments for developments anddebugging are yet to emerge.

133
Caution....• There is no strict delimiters for contributorsThere is no strict delimiters for contributors
to the area of parallel processing: computerarchitectures, operating systems, high levellanguages, compilers, databases, computerlanguages, compilers, databases, computernetworks, all have a role to play.
• This makes it a hot topic of research

134
Programming for Parallel ArchitecturesProgramming for Parallel ArchitecturesTrick One
Hi h l F ti hi h t f thHighway rule: Functions which consume most of the time should be optimized the most.
But be aware of Amdahl’s Law!

135
Trick TwoPlumber’s rule: lot of care has to be given to match bandwidth of communicating subsystems.
Use buffer to limit the effect of instantaneous bandwidths variationsbandwidths variations.
T l i i i h f lTry to overlap communication with useful computations.

136
Memory Hierarchy y y
256 MB256 MB –– 10 GB10 GB
1 TB1 TB –– 100 TB100 TB
100 GB 100 GB –– 2 TB2 TB
256 MB 256 MB 10 GB10 GB
1 TB 1 TB 100 TB100 TB

137
Trick Three
Prophet’s rule: knowing the future always allows you to make the best decisions.If you cannot afford a prophet in your machine,• Use the past to predict the futureUse the past to predict the future• Use the compiler
l h• Bet on several horses

138
Trick FourBlame on others: application universe is so well spread that no matter how well thought of is your architecture, some applications will perform like dogs.• Use the compiler p• Change the applications/algorithms!

139System Design Trends for Scalable ComputersScalable Computers
• Supercomputers are today massively parallel or cluster systems instead of vector systemsinstead of vector systems.– Large number of nodes.– scalar processor technology.
• Supercomputing on demand (Grid, Cloud computing)– pay for capacity and duration (IBM, Google, Sun)
k d• 3D stacked memory– processors and memory on the
same chip (achieve very high bandwidth)
Source. J. Dongarra
same chip (achieve very high bandwidth)
• Different classes of chips (home games business scientific)• Different classes of chips (home, games, business, scientific)• heterogeneous processors
– combine mainstream multicore processors with GPUs, Cells, FPGAs

141Parallel Processing Research at the Distributed and Parallel Systems Group, UIBKy p,
dps.uibk.ac.at• Insieme: an optimizing compiler based on machine p g p
learning for MPI/OpenMP C/C++ codes• Performance Tools and TechnologiesPerformance Tools and Technologies
– SCALEA, SCALEA-G, Aksum, PerformanceProphet, Zenturio, P3T+, Weight Finder
• Programming Paradigms and Environments– OpenMP+, JavaSymphony, AGWL, CGWL, Teutap , y p y, , ,
• Runtime Environment– Scheduling Resource Brokerage Enactment Engine InformationScheduling, Resource Brokerage, Enactment Engine, Information
Service, Ontology and Semantic Grid technologies
• Parallelisation of real-world ApplicationsParallelisation of real world Applications– Material Science, Finance Modeling, Photonics, Astrophysics,
River Modeling, Simulation of semiconductor devices, games

142Askalon www.askalon.orgApplication Development, Analysis, Optimization, pp p , y , p ,Execution for Computational Science and Beyond

143Sources for Slides(Acknowledgements)(Acknowledgements)
• S. Amarasinghe, MITR B U i it f M lb A t li• R. Buyya, University of Melbourne, Australia
• J. Dongarra, University of Tennessee, USA• F. Ercal, University of Missouri-Rolla• T. Fahringer, University of Innsbruck, Austria• Ian Foster, Argonne National Lab, USA• M. Gerndt, Department of Computer Science, TU , p p ,
Munich, Germany• W. Jalby, University de Versailles, France• K Kennedy Rice University USA• K. Kennedy, Rice University, USA• M. J. Quinn, Oregon State University, Corvallis, USA• X. Sun, Illinois Inst. of Technology, USA• M Voss University of Toronto Canada• M. Voss, University of Toronto, Canada• B. Wilkinson and M. Allen, University of North Carolina,
USA