1 epi-820 evidence-based medicine lecture 7: clinical statistical inference mat reeves bvsc, phd
Post on 21-Dec-2015
238 views
TRANSCRIPT

1
EPI-820 Evidence-Based Medicine
LECTURE 7: CLINICAL STATISTICAL INFERENCE
Mat Reeves BVSc, PhD

2
Objectives
• Understand the theoretical underpinnings and the flaws associated with the current approach to clinical statistical testing (the frequentist approach).
• Understand the difference between testing and estimation
• Understand the advantages of the CI and the CI functions.
• Understand the logic of a Bayesian Approach

3
Personal Statistical History….• Post-DVM
• Clue-less. Sceptical of the role of statistics• Thinks research = the search for P < 0.05
• PhD Era:• Increasing obsession with stat methods• Lots of tools! SLR, ANOVA, MLR, LR, LL & Cox• Thinks statistics = “real science”
• Post-PhD:• Healthy scepticism for the way stats are used• Stats = methods which have inherent limitations• Not a substitute for clear scientific thought or understanding the
“scientific method”

4
Review of Significance Tests
Alternative hypothesis (Ha): the mean body wt. of cows trt with BST is different from the mean body wt. of control cows
Ux Uy
Substantive hypothesis: Cows on BST will tend to gain weight
Null hypothesis (Ho): the mean body wt. of cows trt with BST is not different from the mean body wt. of control cows
Ux = Uy

5
Review of Significance Tests
- Logically, if Ho is refuted Ha is confirmed
- investigator seeks to 'nullify' Ho
Expt:
20 cows randomized to BST (X) and control (Y). Measure wt.gain. Calculate mean wt. change per group.

6
Review of Significance Tests
ii) Populations are normally distributed, equal variance
iii) The Ho is true
Assumptions:
i) Sample statistic (X - Y) is one instance of an infinitely largenumber of sample statistics obtained from an infinite number ofreplications of the expt., under the same conditions (frequentistassumption)

7
Review of Significance Tests (t-test)
- t may take on any value, no value is logically inconsistent with Ho! Smaller t values are more consistent with Ho being true.- all else equal, larger n’s increase value of t (higher power).
yxS
YXt
Where:
N (0, 1)df = (n1 – 1) (n2 – 1)
2
21
).11
( Snn
yxS = standard error of the difference between two independent means.
S2 = estimate of pooled population variance

8
Review of Significance Tests
- By convention, relative frequency of t where we decide to choose (ii) above as a logical conclusion is set to 5% (alpha level or significance level)
- Expt: t = 2.55, p = 0.02, reject Ho - result is significant
Large values of t indicate:
i) test assumptions are true, a rare event has occurred
ii) one of the assumptions of the test is false, and by convention it is assumed that the Ho is not true.

9
Review of Significance Tests
- Type 1 error (alpha), occurs 5% of the time when Ho is true
- Type II error (beta), occurs B% of the time when Ho is false
- Alpha and beta are inversely related
- Fixing alpha at 5%, means Sp is 95%
- Beta is not set 'a priori‘, hence Se (power) tends to be low
- Scientific caution dictates that set alpha small
- Scientific ignorance dictates we ignore beta!

10
Alpha and beta are inversely related

11
R e la tio n s h ip b e tw e e n d ia g n o s tic te s t re s u lt a n d d is e a s e s ta tu s
DISEASE
PRESENT (D+) ABSENT (D-)
TEST
POSITIVE (T+)
NEGATIVE (T-)
TP FP
FN TN
a bc d
Sp= P(T-|D-)
PVN= d c + d
Sp= d/b + d
PVP= a a + b
Se= a/a + c
Se= P(T+|D+)

12
R e la tio n s h ip b e tw e e n s ig n ific a n c e te s t re s u lts a n d tru th
TRUTH
Ho False Ho True
SIGNF.
REJECT Ho
ACCEPT Ho
TP FP
FN TN
(1 - B) Type I (a)
Type II (B) (1 - a)
Sp= TN/TN + FP
PVN= TN TN + FN
TEST
PVP= TP TP + FP
Se= Power (1 - B)
Se= TP/TP + FN

13
Power
- Probability of rejecting Ho when Ho is false
- Se = TP/(TP + FN) or (1 - B)
- Power is a function of:
i) Alpha (increase by making Ha one sided i.e., Ux > Uy) (consistent with changing the cut-off value)
ii) Reliability (as measured by SE of the difference)
- SE decreases with increasing sample size (= decr variance)
iii) Size of treatment effect
- Power increases with decreasing SE

14
The Consequences of Low Power
i) difficult to interpret negative results
- truly no effect
- expt unable to detect true difference
ii) increase proportion of type 1 errors in literature
iii) fail to identify many important associations
iv) low power means low precision (indicated by the confidence interval)

15
Questions?
• What proportion of statistically significant findings published in the literature are false positive (Type 1) errors?
• What well known measure is this proportion? and, what elements does this figure therefore depend on?

16
TRUTH
Ho FALSE Ho TRUE
SIGNF.TEST
REJECT Ho
ACCEPT Ho
50 20
50 380
PV+ = 50/70 = 71%
Se = 50% Sp = 95%100 400 N = 500
If all signf. results published, 29% are Type 1 errors
Hypothetical outcomes of 500 experiments, a= 0.05, Power= 0.50, and20% prevalence of false Ho’s

17
The P value
- probability of obtaining a value of the test statistic (X) at least as large as the one observed, given the Ho is true
- It is NOT P (Ho true|Data)!!!
- We can never state the probability of a hypothesis being true! (under the frequentist approach)
Common Incorrect Interpretations
- The probability that the results were due to chance!
- P (>=X | Ho true)

18
Criticisms of Significance Tests
i) Decision vs Inference (Neyman-Pearson)
- problem of automatic acceptance or rejection based on an arbitrary cutoff (P= 0.04 vs P=0.06)
- pioneers of modern statistics were interested in producing results that enabled decisions to be made
- results should adjust your degree of belief in a hypothesis rather than forcing you to accept an artificial dichotomy
- "intellectual economy"

19
Criticisms of Significance Tests
ii) Asymmetry of significance tests
- acceptance of both Ho's given the data leads to 2 very different conclusions!
- frequently, the experimental data can be found to be consistentwith a Ho of no effect or a Ho of a 20% increase
- asymmetry was recognized by Fisher, hence convention is to identify theory with the Ha but to test the Ho
- Is there an effect? is the wrong question! Should ask: What is the size of the effect?

20
Criticisms of Significance Tests
iii) Corroborative power of significance tests
- Both schools presume Ho is almost always false
- Both Fisherian and Neyman-Pearson schools make no assumption about the prior probability of Ho
- rejection of Ho does nothing to illuminate which of the vast number of Ha’s are supported by the data!
- Failing to reject Ho does not prove Ho is true (Popper: 'we can falsify hypotheses but not confirm them')

21
Criticisms of Significance Tests
iv) Effect size and significance tests
- Cannot infer size of an effect by inspection of the P value reporting P< 0.00001 has no scientific merit!
- Test statistics and p values are a function of both effect size and sample size
- Highly significant results may be derived from trivial effects if sample size is large.
- Confidence intervals give plausible range for the unknown popl parameter (signf tests show what the parameter is not!)

22
Relationship between the Size of the Sample and the Size of the P Value
• Example RCT:• Intervention: new a/b for pneumonia.
• Outcome: Recovery Rate = % of patients in clinical recovery by 5 days
• Facts:• Known = Existing drug of choice results in 35%
recovery rate at 5 days
• Unknown = New drug improves recovery rate by 5% (to 40%)

23
P values Generated by RCT by Sample Size
Sample Size (N = 2x) P value (Chi-square)
100 0.465
500 0.103
600 0.074
700 0.053
800 0.039
1000 0.021

24
Conclusion?
Significance testing should be abandoned and replaced withinterval estimation (point estimate and CI)! Why?
- do not imply any decision making implications
- not couched in pseudo-scientific hypothesis testing language
- give plausible range to unknown popl parameter
- gives clue as to sample size (width of the CI)
- avoids danger of inferring a large effect when result if highly significant

25
Interval estimation
- want an unbiased, precise measure of effect
- view "experimentation" as a measurement exercise
- Point estimate: best estimate of the true effect, given the data (aka MLE) and it indicates the magnitude of effect (but is imprecise)
- Confidence intervals indicate degree of precision of estimate. Represent a set of all possible values for the parameter that are consistent with the data
- width of CI depends on variability and level of confidence (%)

26
Interval estimation
- 90% of such intervals will include the true unknown popl. parameter (necessary frequentist interpretation)
- it does not represent a 90% probability of including the true unknown popl. parameter within it
- 90% CI:
- CIs indicate magnitude and precision.
- CI are linked to alpha and hypothesis testing (1 - alpha) = 95%

27
Interval estimation - Example
OUTCOME
TRT B
TRT A
+ -
7
14 6 20
13 20
P(success)= 70%
Significance test: P= 0.06 or NS!
P(success)= 35%
Interval estimation of difference: 35% (95%CI = -1,+71%)

28
Confidence Intervals
- CI are non-uniform, true parameter is more likely to be located centrally than near to limits. Therefore precise location of boundary is irrelevant!
- CI functions
- For a study to be reassuring about a lack of effect, boundaries of CI should be near the null value
- CIs have clear advantages over the p-value but still suffer from the necessary frequentist interpretation (a CI represents one member of a family of CIs produced by an infinite number of replications of the same experiment)
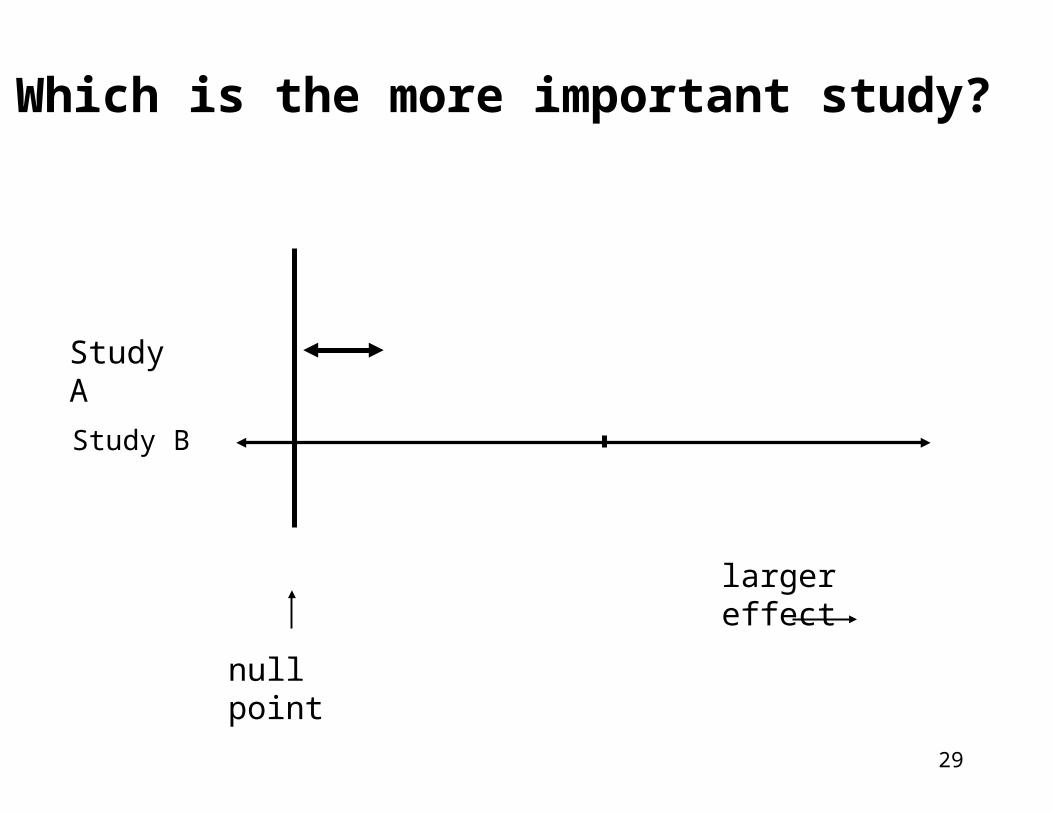
29
Study B
Study A
null point
larger effect
Which is the more important study?

30
Importance of Beta (Type II error) and Sample Size in RCT’s (Freiman et al 1978)
• Reviewed 71 “negative’ (P > 0.05) RCT published from 1960-77
• Assume 25% treatment effect:• 94% (N= 67) of trials had < 90% power• Only 15% (N= 10) had sufficient evidence to
conclude no effect
• Assume 50% treatment effect: • 70% (N= 50) of trials had < 90% power • Only 32% (N= 16) had sufficient evidence to
conclude no effect

31
The P Value Fallacy - Goodman
• Derives from the simultaneous application of the p-value as:• A long-run, error based, deductive tool (Neyman
Pearson frequentist application), and
• A short-run, evidential and inductive tool (i.e., what is the meaning of this particular result?)
• The p-value was never designed to serve these two conflicting roles

32
The Bayes Factor - Goodman
• Comparison of how well two hypotheses predict the data: P (Data | given the Ho) P (Data | given the Ha)
• Allows explicitly the incorporation of external evidence (in terms of prior probability/belief)
• Use of Bayesian statistics shows that weight of evidence against the Ho is not as strong as the p-value suggests (Table 2)