1 dr. virendrakumar (virendra) c. bhavsar professor and director, advanced computational res. lab....
TRANSCRIPT

1
Dr. Virendrakumar (Virendra) C. BhavsarDr. Virendrakumar (Virendra) C. Bhavsar
Professor and Director, Advanced Computational Res. Lab.Professor and Director, Advanced Computational Res. Lab.(Dean 2003-2008)(Dean 2003-2008)
Faculty of Computer ScienceFaculty of Computer ScienceUniversity of New Brunswick (UNB)University of New Brunswick (UNB)
Fredericton, CanadaFredericton, [email protected]@unb.ca
(Thanks - Lu Yang, Biplab Sarker, Harold Boley)(Thanks - Lu Yang, Biplab Sarker, Harold Boley)
Semantic Matching and Applications

2
Faculty of Computer Science
The First “Faculty of CS” in Canada
University of New Brunswick
Fredericton, New Brunswick Fredericton, New Brunswick
CanadaCanadaOldest English Language University in CanadaOldest English Language University in Canada
Established in 1785Established in 1785

33

44

5
Outline
• Motivation• Syntactic Matching• Semantic Matching
- Concept Similarity in a Taxonomy - Schema Matching
• Weighted Tree Representation• Partonomy Tree Similarity Algorithm
• Non-semantic matching on nodes• Semantic Matching
• Inner nodes vs. leaf nodes• Global similarity measure (inner nodes)• Local similarity measures (for leaf nodes)
• Conclusion

6
Exact String Matching
• Binary result 0.0 or 1.0
Permutation of strings
“Java Programming” versus “Programming in Java”
Number of identical words
Maximum length of the two strings
Example 1
For two node labels “a b c” and “a b d e”, their similarity is:
2
4= 0.5
Syntactic Matching

7
Example 2Node labels “electric chair” and “committee chair”
1
2= 0.5 meaningful?
• Syntactic Matching does not consider additional
domain knowledge
•Semantic matching techniques are needed for the above problems
Syntactic Matching

8
Semantic Matching Applications
• Databases• e-Business• Case-Based Reasoning (CBR)• Information Retrieval • Web Services • Natural Language Processing • Information Integration • Other applications

9
Main Server
User Info
User Profiles
User Agents
…
…
Agents
…
…
Matcher1 Matchern
To other sites (network)
Web Browser
User
e-Market
• e-business, e-learning …• Buyer-Seller matching• Metadata for buyers and sellers
• Keywords/keyphrases•S. Marsh, A. Ghorbani and V.C. Bhavsar, The ACORN Multi-Agent System,
Web Int. and Agent Systems, Vol. 1, No.1, pp.65-86, Oct. 2003.
e-Business Applications

10
Concept Similarity in a Taxonomy
• Taxonomy A taxonomy is a scheme that partitions a body of knowledge and defines the relationships among the pieces
Given a taxonomy and two concepts (e.g., A and B), find the semantic similarity (distance) of the two conceptsA B
T axo no m y

11
Semantic Matching Techniques
• Schema Matching • Element Matching• Concept Matching

12
Schema Matching
• Schema A schema is simply a set of elements connected by some structure
• Schema matching (E. Rahm and P. A. Bernstein. A survey of approaches to automatic schema matching. The VLDB Journal 10:334-350, 2001)
• Takes two schemas as input and produces a mapping between
elements of the two schemas that correspond semantically to each other
• Applications
• Schema integration
• Data warehouses
• E-Commerce
• Semantic query processing

13
Concept Similarity in a Taxonomy ─ WordNet
• Semantic knowledge base: WordNet (G.. Miller. Nouns in WordNet: A Lexical Inheritance System. International Journal of Lexicography, 1990, 3(4):245-264.)(G.. Miller. Nouns in WordNet: A Lexical Inheritance System. International Journal of Lexicography, 1990, 3(4):245-264.)
WordNet is the product of a research project at Princeton University which has attempted to model the lexical knowledge of a native speaker of English
• Information in WordNet is organized around logical groupings called synsets
• Each synset consists of synonymous word forms and semantic pointers that describe relationships between current synset and other synsets

14
Concept Similarity in a Taxonomy (Cont’d)
• A taxonomy is represented as a tree or a graph
• IS-A/HAS A (Contributes 80% among all the relationships)
• Part-of/Has-Part
• Classification of the semantic concept similarity measures
• Edge-based approaches — shortest path length
• Node-based approaches — node information content
• Combination of edge-based and node-based approaches
• Edge-weight assignment
1515
• Edge-based approach — shortest path length(R. Rada, H. Mili, E. Bicknell, and M. Blettner. Development and Application of a Metric on Semantic Nets. IEEE Transactions on Systems, Man, and Cybernetics. 1989, 19(1):17-30:17-30)
• Applied to the medical domain
• Intuition The more similar two concepts are, the smaller the concept distance is between them
• Distance (A, B) = minimum number of edges separating a and b where, A and B are two concepts represented by the nodes a and b in an IS-A semantic net
Concept Similarity in a Taxonomy ─ Two Classical Algorithms - #1

1616
• Problems with the Rada et al. algorithm
• For larger or more general domains, this algorithm leads to less accurate results than expected (Resnik et al. 1995, 1999)
• The distances between any two adjacent nodes are not necessarily equal (Richardson & Smeaton 1995)
• It relies on the notion that links in a taxonomy represent uniform distances (Wu & Palmer 1995, Richardson & Smeaton 1995,
Corley & Mihalcea 2005)
• Certain sub-taxonomies might be much denser than others
• Only IS-A relationship was considered (Resnik 1999)
Concept Similarity in a Taxonomy ─ Two Classical Algorithms - #1
1717
• Node-Based Approach — Node Information Content (Resnik et al.1995, 1999)
Goal: To solve the problem that certain sub-taxonomies are much denser than others in a taxonomy
• Intuition One key to the similarity of two concepts is the extent to which they share information in common, indicated in an IS-A taxonomy by a highly specific concept that subsumes them both
• Method Associating probabilities with concepts in the taxonomy
function p: C→[0,1], such that for any c in C, p(c) is the probability of encountering an instance of concept c
=> p is monotonic as one moves up the taxonomy: if c1 IS-A c2, then p(c1) ≤ p(c2)
Concept Similarity in a Taxonomy ─ Two Classical Algorithms - #2
1818
* S. Ross. A First course in Probability. Macmillan, 1976.
• Probability computation of a concept
freq(c) = ∑ count(n)
where words(c) is the set of words subsumed by concept c
p(c) = freq(c)/N where N is the total number of words observed
• Quantification of the information content* -logp(c)
As probability increases, informativeness decreases, so the more abstract a concept, the lower its information content
• Similarity computation
sim(c1, c2) = max [-logp(c)]
where S(c1, c2) is the set of concepts that subsume both c1 and c2
c in S(c1, c2)
n in words(c)
Concept Similarity in a Taxonomy ─ Two Classical Algorithms -#2

1919
• Problems of the information content based approach
Example (Richardson & Smeaton, 1995)
{Produc e, Green goods} 3.034
{Fruit} 3.374
{Apple} 3.945{Berry } 4.907
{Banana} 5.267
{Boxberry } 7.576 {Cranberry } 6.285
• It does not differentiate the similarity values of any pair of concepts in a sub-hierarchy as long as their “smallest common ancestor” is the same e.g. sim(Apple, Berry) = sim(Apple, Banana) = 3.374
Concept Similarity in a Taxonomy ─ Two Classical Algorithms -#2

2020
• It only considers the IS-A links too
• Structure information is overlooked
• It derives coarse similarity results
Concept Similarity in a Taxonomy ─ Two Classical Algorithms (II)

2121
Concept Similarity in a Taxonomy
─ Other Algorithms
321
3
*2
*2)2(
NNN
NSim
D
lengthSim
*2log)1(
)()(
)(*2)3(
21 conceptICconceptIC
LCSICSim
length is the length of the shortest path between two concepts and D is the maximum depth of the taxonomy
N1 and N2 are the numbers of nodes from c1 and c2 to their most specific common superconcept c3; N3 is the number of nodes from c3 to the root of the taxonomy
IC is the information content computed by [4]; LCS is the Least Common Subsumer
*
* C. Leacock and M. Chodorow. Combining Local context and WordNet Sense Similarity for Word Sense Disambiguation. In WordNet, An Electronic Lexical Database. The MIT Press, 1998.
R o o t
N 1 N 2
N 3(Wu & Palmer, 1994)
(Lin, 1998)
c1 c2
c3

2222
)(*2)()(
1)4(
21 LCSICconceptICconceptICSim
(Jiang-Conrath,
1997)
• (Li-Bandar-McLean, 2003)
• The main problem of previous algorithms: Either information sources are directly used as metric of similarity or a method uses a particular information source without considering the contribution of others.
• Intuition Concepts at upper layers of the hierarchy have more general semantics and less similarity between them, while concepts at lower layers have more concrete semantics and stronger similarity. This leads to the consideration of concept depth.
• Three factors that affect concept similarity Path length, depth, and density
Concept Similarity in a Taxonomy ─ Other Algorithms (Cont’d)

2323
• The similarity of two concepts is represented by the function
s(c1, c2) = f ( f1(l), f2(h), f3(d))
where l, h, and d are the shortest path length, the depth of the nearest common subsumer of c1 and c2, and the local density of c1 and c2, respectively
lelf )(1 hh
hh
ee
eehf
)(2 ),(),(
),(),(
32121
2121
)(ccsimccsim
ccsimccsim
ee
eesimf
α is a constantβ > 0 λ > 0
hh
hhl
ee
eeehflfccs
)()(),( 2121
After integration and evaluation:
was reported as the best one
Concept Similarity in a Taxonomy ─ Other Algorithms (Cont’d)

2424
• Basic idea Investigates the performance of algorithms against human common sense
• Benchmark word set A commonly used word set is from an experiment by Rubenstein and Goodenough1 and 26 years later by Miller and Charles2. Subjects rated the semantic similarity values from 0 to 4
• Reference results
1 H. Rubenstein and J. B. Goodenough. Contextual Correlates of Synonymy. Comm. ACM. 1965. 8:627-633.2 G. a. Miller and W. G. Charles. Contextual Correlates of Semantic Similarity. Language and Cognitive Processes, 1991, 6(1):1-28.
Similarity method Correlation
Resnik Replication to Miller-Charles 0.9583
Li-Bandar-McLean 0.8914
Jiang-Conrath 0.8484
Lin 0.8213
Resnik (Information Content) 0.745
Rada (Edge-Counting) 0.664
Concept Similarity in a Taxonomy ─ Evaluation of the Algorithms

2525
• Most of the aspects that should be considered are the structural characteristics (Jiang & Conrath, 1995)
• Local network density One easy way to measure the local density is to find the number of children of a given node. The greater the density, the closer the distance between the nodes Node depth Distance shrinks as one descends the hierarchy, since differentiation is based on finer and finer details
• Type of link
• Link strength The closeness between a child node and its parent node, against those siblings
Concept Similarity in a Taxonomy ─ Edge-Weight Assignment

26
Schema Matching
• Schema representations
Entity-Relationship (ER) model, object-oriented (OO) model, XML and directed graphs
• Element versus structure
Match is performed for individual schema elements or for combinations of elements

27
Schema Matching ─ Approaches
• Cupid (Madhavan et al. 2001)
• Intended to be generic across data models
• Three phrases
• Linguistic element-level matching
• Transformation from the original schema to a tree and the computation of the structural similarity between pairs of elements
• Mapping between elements
• Similarity flooding (Melnik et al. 2002)
• A graph matching algorithm
• Schemas are converted into directed labeled graphs
• The element-level mapping is fed into the SF matcher
• Filters are applied to select relevant subsets of match results

28
Schema Matching ─ Approaches (Cont’d)
• COMA (Do & Rahm 2002)
• Represents schemas as rooted directed acyclic graphs
• Combines match algorithms in a flexible way
• Represents a generic match system supporting different applications and multiple schema types such as XML and relational schemas
• Allows an interactive and iterative match process
• Reuses the previously obtained match results

2929
• Concept similarity matching in a taxonomy
• Edge-based
• Node-based
• Considerations
• Path length
• Node information content
• Node depth
• Edge weight
• Semantic matching are applicable in many applications
• Schema matching
• Structure matching
• Element matching
Recap

3030
• More and more on-line transactions (e.g. e-Bay, Kijiji, etc.)
• Buyers and sellers input key words and/or specify values for some product features
• A list of recommended sellers (with product advertisements) and/or buyers (with product requests) is presented
• Flat representation of products cannot represent the hierarchical ‘part-of’ relationship of product parts
• Match-making is not precise
• Negotiation space is large
Motivation

31
Main Server
User Info
User Profiles
User Agents
…
…
Agents
…
…
Matcher1 Matchern
To other sites (network)
Web Browser
User
e-Market
• e-business, e-learning …• Buyer-Seller matching•Ranked pairings of Buyers and Sellers• Metadata for buyers and sellers
• Keywords/keyphrases•S. Marsh, A. Ghorbani and V.C. Bhavsar, The ACORN Multi-Agent System, Web Int. and Agent Systems, Vol. 1, No.1, pp. 65-86, 2003.
e-Business Applications

32
• Web service discovery [Field and Hoffner 2003] [Kawamura et al. 2001] [Trastour et al. 2001]
• Multi-agent systems [Bertels et al. 2004] [Decker et al. 1996] [Marsh et al. 2003] [Ogston and Vassiliadis 2001]
• Database schema, XML schema, and Data integration [Melnik et al. 2001] [Madhavan et al. 2001]
• Ontology integration [Jiang and Conrath 1997] [Maguitman et al. 2005] [Sussan 1993]
• … …
Match-Making

33
Partonomy Tree Similarity Algorithm─ Tree Representation
• Tree representation for product/service descriptions [Bhavsar et al. 2004]
• Characteristics of our trees
• Node-labled, arc-labled and arc-weighted
• Sibling arcs are labled in lexicographical order
• Sibling arc weights sum to 1.0
A simple example “Car” tree:
2002
Car
FordBlack
Make
Color Year0.3
0.2
0.5

34
Seller Weights (1)
• Advertisements on TV, Internet, and in newspapers
• Sellers emphasize specific product/service features to attract buyers
• Sellers seek buyers having preferences close
to their products

35
Seller Weights (2)
• No weights
seller
2002
Car
FordRed
Make
Color Year1/3
1/3
1/3

36
Seller Weights (3)
• Weights are not specified
buyer seller
2002
Car
FordBlack
Make
Color Year0.1
0.1
0.8
2002
Car
FordRed
Make
Color Year1/3
0.7834
1/3
1/3

37
Seller Weights (4)• Sellers give weights
buyer seller1
2002
Car
FordBlack
Make
Color Year0.1
0.1
0.8
2002
Car
FordRed
Make
Color Year0.05
0.05
0.9
0.925
2002
Car
FordRed
Make
Color Year0.2
0.2
0.6
seller2
2002
Car
FordRed
MakeColor Year
0.10.6 0.3
seller3
0.85 0.65
• All the seller trees below are identical except the arc weights

38
Seller Weights (5)
• Using seller weights, both buyers and sellers can find the most promising trading partners
• The negotiation space is decreased
• Sellers can always select the same weight for all fanout branches if they do not want to emphasize any attributes of their products/services

39
Some important algorithms in literature:• Node-labeled tree edit distance [Lu 1979] [Wang et al. 1994] [Shasha et al. 2001]
• Insertion, deletion and substitution• Minimum cost to transform one tree to another one
• ATreeGrep [Shasha et al. 2002]• Approximate tree searching • Only nodes are labeled• Siblings cannot be identical
• Schema tree matching — Cupid [Madhavan et al. 2001]• Transformation from the original schema to a tree and
computation of the structural similarity between pairs of elements
• … …
Tree Similarity/Distance (1)
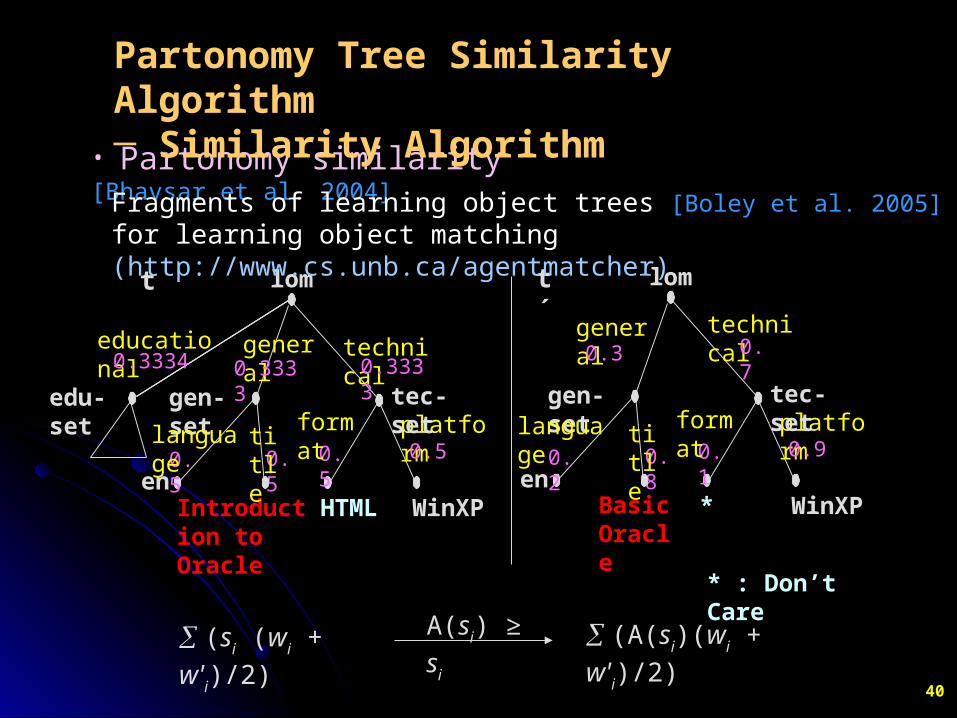
40
(si (wi + w'i)/2)
(A(si)(wi + w'i)/2)
A(si) ≥ si
lom
educational
0.5
general
format platform0.50.50.5
Introduction to Oracle
t t´
technical0.3334 0.33330.3333
edu-set gen-set tec-set
language
en
title
HTML WinXP
lom
0.1
general
format platform0.90.80.2
Basic Oracle
technical0.70.3
gen-set tec-setlanguage
en
title
* WinXP
* : Don’t Care
• Partonomy similarity [Bhavsar et al. 2004]
Fragments of learning object trees [Boley et al. 2005] for learning object matching (http://www.cs.unb.ca/agentmatcher)
Partonomy Tree Similarity Algorithm─ Similarity Algorithm

41
Semantic Matching
• Inner nodes versus Leaf nodes
• Inner nodes — class-orientedInner node labels can be classes
• Classes are located in a taxonomy tree• Taxonomic class similarity measure (global similarity measure)
• Leaf nodes — type-oriented• Address, currency, date, price and so on• Type similarity measures (local similarity measures)

42
Semantic Matching (Cont'd)
String Permutation (both inner
and leaf nodes)
Exact String Matching (both inner
and leaf nodes)
Non-Semantic Matching
Taxonomic Class Similarity
(inner
nodes)
Type Similarity (leaf nodes)
Semantic Matching

43
Distributed Programming
Credit
“Introduction to Distributed Programming”
Textbook
TuitionDuration
$8002months3
0.20.1 0.3
0.4
t1 t2
Object-Oriented Programming
Credit
“Objected-Oriented Programming Essentials”
Textbook
TuitionDuration
$10003months3
0.10.5 0.2
0.2
Partonomy trees
• Global similarity measure (for inner nodes) [Yang et al. 2005]
Semantic Matching ─ Global Similarity

44
Tree Similarity Algorithm Development— Tree Similarity Function
• Desired General Properties• Similarity function maps to [0.0, 1.0]• Reflexivity sim(t,t) =1.0• Symmetry (could be relaxed) sim(t,t’) = sim(t’,t)
• Negative properties• The following two conditions do not hold
• If sim(x,y) = 1.0, then x = y
• “Triangle Inequality” [sim(x,y)+ sim(y,z)] sim(x,z) >= sim(x,y) sim(y,z)

45
Tree Similarity Algorithm Development— Tree Similarity Function
• Desired Special Properties• Breadth/Depth Robustness• Subtree Aggregation• Taxonomic class similarity of inner node labels• Local similarity of leaf node labels
Select a tree, t, in the tree data set as the reference tree, the similarity between t and the trees in the data set
1.0
Similarity
Trees0.0
Similarityapproaches 0.0
t

46
Tree Similarity Algorithm Development— Tree Similarity Algorithm
Desired properties
• Realize all desired properties of the function
• (Recursive) Top-down traversal via subtree pairs under identically labeled arcs
• Bottom-up similarity computation
• Combining weights of identically labeled arcs
• Inner node similarity
• Node-label similarity — syntactic or semantic
• Aggregation of subtree similarities
• Leaf node similarity — syntactic or semantic

47
• Arc-weighted tree distance [Amenta et al. 2007]
• Point representation of trees
• Arcs can be weighted/unweighted
• Only leaf nodes are labeled
• No arc labels
• Robinson-Foulds distance is employed
Tree Similarity/Distance (2)

48
Tree Simplicity
• Buyers and sellers may omit some product/service features, which lead to missing (sub)trees in product/service trees
• Calculate the simplicity of the missing (sub)tree for the similarity computation
• The simpler the missing (sub)tree, the greater its similarity and the empty tree

49
Tree Simplicity
• Desired properties
A tree simplicity function on a tree t is a real valued function simp(t) → R[0.0, 1.0] with the
following properties:1) Breadth property simp[bt] ]: N1→ R[0.0, 1.0]
bt is the fanout of tree t. For two trees t and t':
bt > bt' => simp(t) < simp(t') The simplicity of a tree monotonically decreases with increasing tree breadth.
2) Depth property simp[dt]]: N0→ R[0.0, 1.0]
dt is the depth of tree t. For two trees t and t': dt > dt' => simp(t) < simp(t') The simplicity of a tree monotonically decreases with increasing tree depth.

50
Programming Techniques
Applicative Programming
0.60.5General
Automatic Programming
Concurrent Programming
Sequential Programming
Object-Oriented Programming
Distributed Programming
Parallel Programming
0.8 0.50.9
0.7
0.7 0.5
• The taxonomy tree of “Programming Techniques” according to the ACM Computing Classification System (http://www.acm.org/class/1998/ccs98.txt)
Semantic Matching ─ A Taxonomy Tree

51
• The arc weights can be determined by human experts or machine learning algorithms [Singh 2005]
• Sibling arc weights do not need to add up to 1
• Three factors that affect the taxonomic class similarity
• The shortest path length between two classes
• Arc weights on the shortest path
• Level difference of two classes
Semantic Matching ─ Taxonomic Class Similarity

52
• Taxonomic class similarity computation [Yang et al. 2005]
21**)1(),( 21cc dd
t
s GMN
NccTS
where
TS(c1, c2) is the taxonomic class similarity of classes c1 and c2
Ns: the number of edges of the shortest path
Nt: the number of edges of the whole tree
M: the product of the arc weights on the shortest path
: the level difference factor where G’s value is in (0.0, 1.0) and is the absolute difference of the depths of classes c1 and c2 (We assume G=0.5 here)
21 cc ddG
||21 cc dd
Semantic Matching ─ Taxonomic Class Similarity

53
Programming Techniques
Applicative Programming
0.60.5General
Automatic Programming
Concurrent Programming
Sequential Programming
Object-Oriented Programming
Distributed Programming
Parallel Programming
0.8 0.5 0.90.7
0.7 0.5
Example
0766.012
5.0*)7.0*5.0*7.0(*)8
31(
)gProgrammin Oriented-Object g,Programmin dDistribute(
TS
• red arrows stop at their nearest common ancestor
Semantic Matching ─ Taxonomic Class Similarity

54
• Encoding subtaxonomy trees into partonomy trees
• A converse task Computes the similarity of pairs of taxonomies e.g. subtaxonomies of the background taxonomy, as required in our Teclantic project (http://teclantic.cs.unb.ca)
• Allows the direct reuse of our partonomy similarity algorithm and permits weighted (or ‘fuzzy’) taxonomic subsumption with no added effort
Semantic Matching ─ Encoding Subtaxonomies

55
Programming Techniques
ApplicativeProgramming
0.1 0.15General
AutomaticProgramming
ConcurrentProgramming
SequentialProgramming
Object-OrientedProgramming
DistributedProgramming
ParallelProgramming
0.3
0.1
0.15
* **
* *
* *
*
0.6 0.4
0.2
• Sibling arc weights must sum up to 1.0
• Classes are represented as arc labels (lexicographical ordered)
• All node labels except the root node label are changed into “Don’t Care”
Background Taxonomy tree of “Programming Techniques” for encoding
Semantic Matching ─ Encoding Subtaxonomies

56
Credit TitleTuition
Duration$800
2months3
0.050.1 0.15
0.05Classification
0.65taxonomy
DistributedProgramming
course
SequentialProgramming
ParallelProgramming
*
*
0.6 0.4
*
*0.7 0.3
1.0Programming Techniques
*
DistributedProgramming
ConcurrentProgramming
Credit TitleDuration
$1000
3months3
0.20.05 0.05
0.05Classification
0.65taxonomy
Object-OrientedProgramming
course
SequentialProgramming
**0.8 0.2
1.0Programming Techniques
*
Tuition
Object-OrientedProgramming
Two course trees with encoded subtaxonomy trees
Semantic Matching ─ Encoding Subtaxonomies
• Weight assignment in the "Classification" branch (two options)
• By human expert
• By machine learning
• Normalizes corresponding weights in the background taxonomy

57
Semantic Matching ─ Local Similarity
• Local similarity measures (for leaf nodes) Special-purpose similarity measures for various data types realizing semantics to be invoked when computing similarity of any two of their instances
• “Price” type
• “Date” type [Yang et al. 2005]
• . . .

58
• Price
• Price is the omnipresent factor that determines buyers’ and sellers’ decision-making
• Price similarity seems to be asymmetric for buyers and sellers
e.g. buyer asks $800 and seller asks $1000 — Unsuccessful buyer asks $1000 and seller asks $800 — Successful The similarity of $800 and $1000 is different for the above cases
Semantic Matching ─ Price Matching

59
• Transform the asymmetry to symmetry
• Buyers and sellers always have price ranges in their minds [Bpref, Bmax] and [Smin, Spref]
Bpref : buyer’s preferred price
Bmax : buyer’s maximum acceptable price
Smin : seller’s minimum acceptable price
Spref : seller’s preferred price
• Our price-range similarity measure is based on the intuition that the greater the overlap between the buyer’s and seller’s price ranges, the higher is their similarity value
Semantic Matching ─ Price Matching

60
PriceRangeSim ([Bpref, Bmax], [Smin, Spref])Begin If Spref <= Bpref similarity = 1.0 else if Bmax < Smin similarity = 0.0 else if Bmax = Smin
similarity = else { MIN = min{MIN, Smin} MAX = max{MAX, Bmax}
similarity = } return similarity End.• This algorithm can be easily adapted to the “price”-typed attributes
e.g. “salary range” in job seeking and recruiting e-Market
• Pseudo code of the price-range similarity algorithm
MINMAX
005.0
MINMAX minmax SB
Semantic Matching ─ Price Matching Algorithm

61
• “Date”-typed leaf node similarity measure
{1 –
| d1 – d2 |
365
0.0 if | d1 – d2 | ≥ 365
otherwiseDS(d1, d2) =
0.5
end_date
Nov 3, 2004
0.5
t1 t 2
start_date
May 3, 2004
Project
0.5
end_date
Feb 18, 2005
0.5
start_date
Jan 20, 2004
Project
0.74
where DS(d1, d2) is the date similarity of two dates d1 and d2
Semantic Matching ─ Date Matching

62
Evaluation
• Analytic study of algorithmic properties
(for special cases)
• Experiments to assess properties of functions and algorithms
• Comparison with other algorithms- Arc-weighted tree distance [Amenta et al. 2007]- Weighted keywords/phrases similarity
[Marsh 2003]- Online hotel search [Niemann 2006]

63
Implementation, Testing and Evaluation
• Implementation
• In Java
• Testing on systematically varied cases
• Evaluation
• Experiments to assess properties of algorithms
• Analytic study of algorithmic properties
• Show the behavior of the algorithms with increasing breadth and depth

64
Implementation, Testing and Evaluation
• Comparison with other algorithms
• Arc-weighted tree distance [Amenta et al. 2007]
• Weighted keywords/phrases [Marsh et al. 2003]
• ATreeGrep [Shasha et al. 2002]
• Node-labeled tree edit distance [Lu 1979]

65
• eduSource project
Partonomy Tree Similarity Algorithm─ Application
Similarity Engine(Java)
Translator(XSLT)
CANLOM(XML)
Prefilter(SQL)
LOMGen(Java)
LOR(HTML)
Enduser
Administrator
user input
prefilter parameters (Query URI)
WOO RuleML file
Recommended results
HTML files
partial CanCore filesCanCore
files
prefiltered CanCore filesWOO
RuleML files
DATABASE(Access)
UI (Java)
Keyword Table
Administrator input
(1)
(2)(4) (5)
(6) (7)
(3)
(8)
(a)
(b)
(c)
Search
Results

66
• Teclantic protal http://www.teclantic.ca
•ca)
Partonomy Tree Similarity Algorithm─ Application

67
Conclusion• Weighted trees for product/service descriptions
• Partonomy tree similarity algorithm
• Synchronously traverses trees top-down
• Aggregates intermediate similarity values bottom-up
• Semantic Global and Local Matching
• Taxonomic Class Similarity
• Encoding Subtaxonomies into Partonomies
• Leaf-Node Type Similarity Measures
• Future Work
• Improvement of Taxonomic Class Similarity
• Generalization of Local Similarity Measures

68
Publications1. M. Joshi, V.C. Bhavsar, H. Boley, Hunt ForTune: A Framework for Matchmaking,”
accepted for the International Conference on Emerging Trends in Engineering and Technology (ICETET 2009), sponsored by IEEE SMC Society, Nagpur, India, Dec. 16-18, 2009 (to appear).
2. M. Joshi, V. Bhavsar and P. Lingras, “An Algorithm for the Estimation of a Time Period of 2-Sequences,” accepted for the 4th Indian International Conference on Artificial Intelligence, Dec. 16-18, 2009, Tumkur (Banglore), India, 2009.
3. M. Joshi, V.C. Bhavsar and H. Boley, “Knowledge Representation in Matchmaking Applications,” chapter in ‘Advanced Knowledge-Based Systems: Models, Applications and Research Trends, Eds. P.S. Sajja and R. Akerkar, e-Book Series, TMRF, India (accepted, to appear).
4. M. Joshi, V. Bhavsar and H. Boley, "A Knowledge Representation Model for Match-Making Systems in e-Marketplaces," Proc. of the 11th International Conference on e-Commerce (ICEC 2009), August 12-15, 2009, Taipei, Taiwan, pp. 362-365, 2009.
5. L. Yang, B. K. Sarker, V.C. Bhavsar and H. Boley, “Range Similarity and Satisfaction Measures for Buyers and Sellers in e-Marketplaces,” Journal of Intelligent Systems, Vol. 17, No. 1-4, pp. 247-266, 2008.

69
Publications6. Lu Yang, B. K. Sarker, V. C. Bhavsar, and H. Boley. “Range
Similarity and Satisfaction Measures for Buyers and Sellers in e-Marketplaces”. Journal of Intelligent Systems, Vol. 17, No. 1-4, pp. 247-266, 2007.
7. Lu Yang, Biplab K. Sarker, Virendrakumar C. Bhavsar, and Harold Boley, "Range Similarity Measures between Buyers and Sellers in e-Marketplaces", In Proceedings of the Second Indian International Conference on Artificial Intelligence, Pune, Dec. 20-22, 2005, pp. 2559-2572, 2005.
8. Lu Yang, Marcel Ball, Virendrakumar C. Bhavsar, and Harold Boley, "Weighted Partonomy-Taxonomy Trees with Local Similarity Measures for Semantic Buyer-Seller Match-Making". Journal of Business and Technology, Vol. 1, No. 1, pp. 42-52, Oct. 2005.

70
Publications
9. Harold Boley, Virendrakumar C. Bhavsar, David Hirtle, Anurag Singh, Zhongwei Sun, and Lu Yang, "A Match-Making System for Learners and Learning Objects", International Journal of Interactive Technology and Smart Education, 2(3), pp. 171-178, 2005.
10. Jing Jin, Biplab K. Sarker, V.C. Bhavsar and H. Boley, and Lu Yang, "Towards a Weighted-Tree Similarity Algorithm for RNA Secondary Structure Comparison", In Proceedings of the 8th International Conference on High Performance Computing in Asia Pacific Region, IEEE Computer Society, December 2005.
11. Lu Yang, Marcel Ball, Virendrakumar C. Bhavsar, and Harold Boley, "Weighted Partonomy-Taxonomy Trees with Local Similarity Measures for Semantic Buyer-Seller Match-Making", In Proceedings of Workshop of Business Agents and the Semantic Web (BASeWEB'05), May 8, 2005, Victoria, British Columbia, Canada.

71
Publications12. Lu Yang, Biplab K. Sarker, Virendrakumar C. Bhavsar, and Harold
Boley, "A Weighted-Tree Simplicity Algorithm for Similarity Matching of Partial Product Descriptions", In Proceedings of ISCA 14th International Conference on Intelligent and Adaptive Systems and Software Engineering, Toronto, 2005, pp.55-60.
13. Virendrakumar C. Bhavsar, Harold Boley, and Lu Yang, "A Weighted-Tree Similarity Algorithm for Multi-Agent Systems in e-Business Environments", Computational Intelligence, 20(4), pp.584-602, 2004.
14. Riyanarto Sarno, Lu Yang, Virendrakumar C. Bhavsar, and Harold Boley, "The AgentMatcher Architecture Applied to Power Grid Transactions", In Proceedings of the First International Workshop on Knowledge Grid and Grid Intelligence, Halifax, 2003, pp.92-99, 2003.
15. Virendrakumar C. Bhavsar, Harold Boley, and Lu Yang, "A Weighted-Tree Similarity Algorithm for Multi-Agent Systems in e-Business Environments", In Proceedings of 2003 Business Agents and the Semantic Web (BASeWEB'03) Workshop, Halifax, Canada, June 14, 2003.

72
ThesesLu Yang, Weighted Tree Similarity, Ph.D. Thesis, in progress.
Anurag Singh, “LOMGenIE: A Weighted Tree Metadata Extraction Tool,” MCS Thesis, September 2005.
Mathieu Sebastien, “Match-making in Bartering Scenarios,” MCS Thesis, December 2005.
Jin Jin Jing, “Similarity of Weighted Directed Acyclic Graphs,” MCS Thesis, September 2006.
Jie Li, “Rule-based Social Networking for Expert Finding,”, MCS Thesis, September 2006.

73
Post-Doctoral Fellows
Biplab Sarker
Manish Joshi

74
Thank you !

75
Semantic Matching Review - References
[1]. R. Rada, H. Mili, E. Bicknell, and M. Blettner. Development and Application of a Metric on Semantic Nets. IEEE Transactions on Systems, Man, and Cybernetics. 1989, 19(1):17-30:17-30.
[2]. M. Sussna. Word Sense Disambiguation for Free-text Indexing Using a Massive Semantic Network. Proceedings of the Second International conference on Information and Knowledge Management, Arlington, Virginia, 1993.
[3]. Z. Wu and M. Palmer. Verb Semantics and Lexical Selection. Proceedings of the 32nd Annual Meeting of the Associations for Computational Linguistics, Las Cruces, New Mexico, 1994, 133–138.
[4]. P. Resnik. Using Information Content to Evaluate Semantic Similarity in a Taxonomy. Proceedings of the 14th International Joint Conference on Artificial Intelligence, Montreal, August 1995, 1:448-453.
[5]. R. Richardson, and A. F. Smeaton. Using WordNet in a Knowledge-Based Approach to Information Retrieval. Working Paper, CA-0395, School of Computer Applications, Dublin City University, Ireland, 1995.
[6]. J. J. Jiang and D. W. Conrath. Semantic Similarity Based on Corpus Statistics and Lexical Taxonomy. Proceedings of International Conference Research on Computational Linguistics (ROCLING X), Taiwan, 1997.
[7]. D. Lin. An Information-Theoretical Definition of Similarity. Proceedings of the Fifth International Conference on Machine Learning, Morgan Kaufmann Publishers Inc., 1998, 296-304.
[8]. P.Resnik. Semantic Similarity in a Taxonomy: An Information-Based Measure and its Application to Problems of Ambiguity in Natural Language. Journal of Artificial Intelligence Research, 1999, 11:95-130.
[9]. Y. Li, Z. A. Bandar, and D. McLean. An Approach for Measuring Semantic Similarity between Words Using Multiple Information Sources. IEEE Transactions on Knowledge and Data Engineering, 2003, 15(4):871-882.
[10]. C. Corley and R. Mihalcea. Measuring the Semantic Similarity of Texts. Proceedings of the ACL Workshop on empirical Modeling of Semantic Equivalence and Entailment, Ann Arbor, June 2005, 13-18.
[11]. A. G. Maguitman, F. Menczer, H. Roinestad and A. Vespingnan. Algorithmic Detection of Semantic Similarity. Proceedings of WWW 2005, Chiba, Japan, May 10-14, 2005.
[12]. E. Rahm and P. A. Bernstein. A survey of approaches to automatic schema matching. The VLDB Journal 10:334-350, 2001.
[13]. J. Madhavan, P. A. Bernstein and E. Rahm. Generic schema matching with Cupid. Technical Report. Microsoft Research. August, 2001.
[14]. S. Melnik, H. G. Molina and E. Rahm. Similarity Flooding: A Versatile Graph Matching Algorithm and its Application to Schema Matching. In Proceedings of 18th Intl. Conf. on Data Engineering (ICDE), San Jose, CA, 2002.
[15]. H.-H. Do and E. Rahm. COMA - A System for Flexible Combination of Schema Matching Approaches. The VLDB Journal, 2002.
[16]. Institute of Electrical and Electronics Engineers. (1990) IEEE Standard Computer Dictionary: A Compilation of IEEE Standard Computer Glossaries. New York, NY.
[17] G. Miller. Nouns in WordNet: A Lexical Inheritance System. International Journal of Lexicography, 1990, 3(4):245-264.[17] G. Miller. Nouns in WordNet: A Lexical Inheritance System. International Journal of Lexicography, 1990, 3(4):245-264.

76
ReferencesAmenta, N., M. Godwin, N. Postarnakevich, and K. St. John. (2007) Approximating Geodesic Tree Distance. Information Processing Letters 103, 61-65.
Bertels, K., N. Panchanathan, and S. Vassiliadis. (2004) Centralized Matchmaking for Minimal Agents. Proceedings of the Conference on Parallel and Distributed Computer Systems, November, 2004.
Decker, K., M. Williamson, and K. Sycara. (1996) Matchmaking and Brokering. Proceedings of the Second International Conference on Multi-Agent Systems.
Do, H.-H., and E. Rahm. (2002) COMA--A System for Flexible Combination of Schema Matching Approaches. Proceedings of 28th International Conference on Very Large Databases, Hong Kong, 610-621.
Field, S., and Y. Hoffner. (2003) Web services and matchmaking. Int. J. Networking and Virtual Organisations, 2(1), 16-32.
Jiang, J. J., and D. W. Conrath. (1997) Semantic Similarity Based on Corpus Statistics and Lexical Taxonomy. Proceedings of International Conference Research on Computational Linguistics (ROCLING X), Taiwan.
Kawamura, T., T. Hasegawa, and A. Ohsuga. (2001) Proposal of Semantics-based Web Service Matchmaking. International Conference on Computational Intelligence and Multimedia Applications.
Lu, S. (1979) A tree-to-tree distance and its application to cluster analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-1(2), 219-224. Madhavan, J., P. A. Bernstein and E. Rahm. Generic schema matching with Cupid. Technical Report. Microsoft Research. August, 2001.
Maguitman, A. G., F. Menczer, H. Roinestad and A. Vespingnan. (2005) Algorithmic Detection of Semantic Similarity. Proceedings of WWW 2005, Chiba, Japan, May 10-14, 2005.
Marsh, S., A. Ghorbani and V. C. Bhavsar. (2003) The ACORN Multi-Agent System, Web Intelligence and Agent Systems, IOS Press, Amsterdam, 1(1), 1-21.
Melnik, S., H. Garcia-Molina and E. Rahm. (2001) Similarity Flooding: A Versatile Graph Matching Algorithm. Extended Technical Report, http://dbpubs.stanford.edu/pub/2001-25.
Ogston, E., and S. Vassiliadis. (2001) Matchmaking among Minimal Agents without a Facilitator. Proceedings of the 5th International Conference on carnomous Agents, 608-615.
Shasha, D., J. Wang, and K. Zhang. (1994) Exact and Approximate Algorithm for Unordered Tree Matching. IEEE Transactions on Systems, Man and Cybernetics, 24(4), 668-678.
Shasha, D., J. Wang, and R. Giugno. (2002) Algorithms and Applications of Tree and Graph Searching. Proc. Of the 21th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems. 39-52.
Sussna, M. (1993) Word Sense Disambiguation for Free-text Indexing Using a Massive Semantic Network. Proceedings of the Second International conference on Information and Knowledge Management, Arlington, Virginia.
Trastour, D., C. Bartolini, and J. G-C. (2001) A Semantic Web Approach to Service Description for Matchmaking of Services. Internal report, Hewlett-Packard Company.
Wang, J., K. Zhang, K. Jeong, and D. Shasha (1994) A System for Approximate Tree Matching. IEEE Transactions on Knowledge and Data Engineering. 6(4), 559-570.
Yang, L., V. C. Bhavsar, and H. Boley. (2008) On Semantic Concept Similarity Methods. The 4th International Conference on Information & Communication Technology and Systems (ICTS), Indonesia (to appear).

77
ReferencesRada, R., H. Mili, E. Bicknell, and M. Blettner. (1989) Development and Application of a Metric on Semantic Nets. IEEE Transactions on Systems, Man, and Cybernetics, 19(1), 17-30.
Lin, D. (1998) An Information-Theoretical Definition of Similarity. Proceedings of the Fifth International Conference on Machine Learning, Morgan Kaufmann Publishers Inc., 296-304.
Jiang, J. J., and D. W. Conrath. (1997) Semantic Similarity Based on Corpus Statistics and Lexical Taxonomy. Proceedings of International Conference Research on Computational Linguistics (ROCLING X), Taiwan.
Yang, L., B. K. Sarker, V. C. Bhavsar, and H. Boley. (2007) Range Similarity and Satisfaction Measures for Buyers and Sellers in e-Marketplaces. Journal of Intelligent Systems.
Niemann, M., Malgorzata Mochol, and Robert Tolksdrof. (2006) Improving Online Hotel Search - What Do We Need Semantics for?. Semantics: The New Paradigm Shift in ITNovember 28 - 30, Vienna, Austria.