1 beyond pages: supporting efficient, scalable entity search with dual-inversion index tao cheng and...
TRANSCRIPT

1
Beyond Pages: Supporting Efficient, Scalable Entity
Search with Dual-Inversion Index
Tao Cheng and Kevin Chang
{tcheng3,kcchang}@cs.uiuc.edu
Computer Science DepartmentUniversity of Illinois at Urbana-Champaign

2
Customer service phone number of Amazon?
Users in Frustration
Search on
Amazon?
Search on
Search Engine?

3
Professors in the area of data mining
Even More Frustration
cs.uiuc.edu cs.uiuc.edu/research
cs.uiuc.edu/research/data
cs.stanford.edu ……
cs.stanford.edu/researchcs.stanford.edu/research/faculty

4
Many many such cases:
The email of Kevin Chang? The papers and presentations of ICDE 2010? Conferences and their due dates on databases in
2010? Sale price of “Canon PowerShot A400”?
Often times, we are looking for data entities, e.g., emails, dates, prices, etc., not pages.
Indeed, according to a recent survey, 52.9% of queries are directly targeting at structured entities [DE Bulletin’09][DE Bulletin’09]: R. Kumar and A. Tomkins, “A Characterization of Online Search Behavior”

Recent Trends: WQAWeb-based Question Answering (WQA)
(Wu 2007, Lin 2003, Brill 2002)
Who is CEO of Dell?
Keywords:“CEO Dell”
Parse Top-k
results
Michael Dell
5
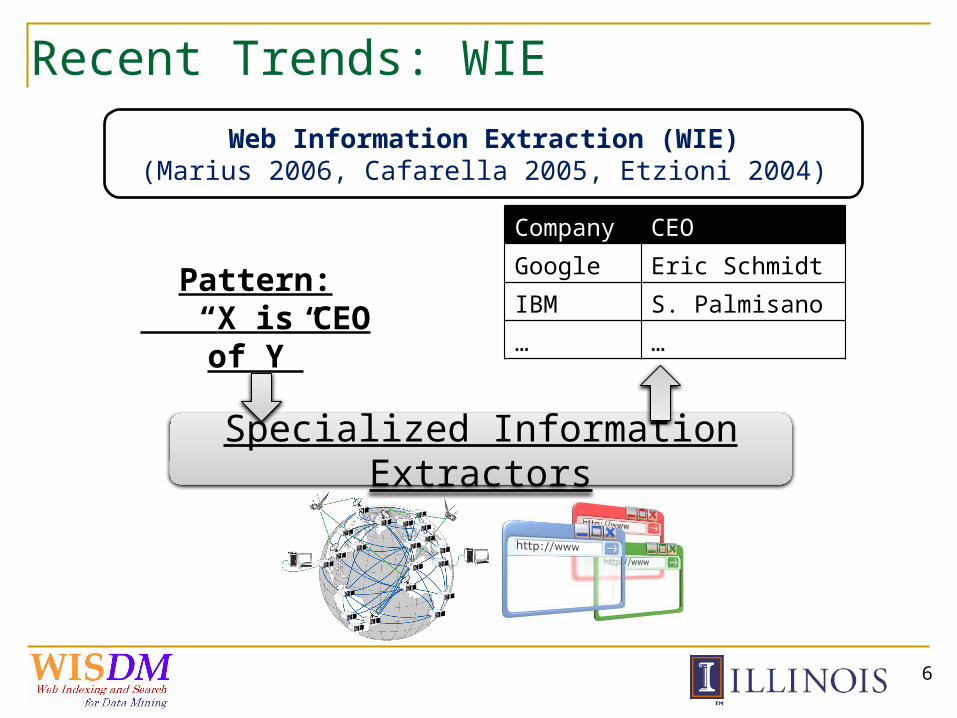
Recent Trends: WIE
6
Specialized Information Extractors
Web Information Extraction (WIE)(Marius 2006, Cafarella 2005, Etzioni 2004)
Pattern: “X is CEO of
Y”
Company CEO
Google Eric Schmidt
IBM S. Palmisano
… …

Recent Trends: TAS
7
Typed-Annotated Search (TAS)(Cheng 2007, Cafarella 2007, Chakrabarti 2006)
Inventor of television?
……
0.60
0.80
0.90
Ranked Entity List
Finding person names nearKeywords “invent” and
“television”
Typed-Annotated Search

8
From Pages to Data EntitiesTraditional Search Entity Search
Keywords Keywords &Entity Type
ResultsResults Support

9
Concretely, what do we mean by Entity Search?
Online Demo.
3TB Corpus of 150M pages 16-machine cluster
24 entity types

10
Entity Search Problem Abstraction
Input: Keywords & Entity Type (optionally with a pattern)
E.g. Amazon Customer Service #phone
Output: Ranked Entity Instances
Ordered by: Score(e)where e is an entity instance ……
0.60
0.80
0.90
Given:
D

Unanimous Requirements across the Trends Context Matching (in document)
Match the target type (say #location) by keywords (e.g., “louvre museum”) that appear in its surrounding context, in certain desired patterns
Global Aggregation (across documents) Match an entity (say, #location = Paris) for as
many times as it appears in numerous pages
11

Computation Challenges
Expensive Context Matching (Join ) Need to perform proximity matching in
documents Beyond simple containment checking
Extensive Global Aggregation (G) Need to perform corpus scale aggregation
A layer that is non-existent in online page retrieval
12
wv L

Traditional Page Retrieval based Approach
13
Who is the CEO of Dell?
Keywords:“CEO Dell”
Analyze top-k
results
Michael Dell
Limitation
• Only top-k documents
• Many random seeks

Our Proposal: Entity-aware Indexing
Inspired by the success of inverted index in enabling efficient IR for searching documents
However, traditional inverted index only aware of keywords and documents How can we make index entity aware?
Our proposal: Dual-Inversion Index Principle I: Document-inverted Index Principle II: Entity-inverted Index
14

Entity-as-keyword: Document-inverted Index
15
2d 12 6d 17
9d 366d 18
9d 34
56d 56 200
257 56d 55 64d 5
68d 56
97d 45
75d 56 97d 47
8p :800-201-7575 10p :408-376-7400
DamazonaD :)(
DservicesD :)(
6d ],23[ 8p 9d],323[ 10p ...],45[ 86p 97d ...],50[ 8p
DphonepD :#)(#
keyword pos
doc id

Document Space Partitioning
2d 12 6d 17
9d 366d 18
9d 34
56d 56 200
257 56d 55 64d 5
68d 56
97d 45
75d 56 97d 47
)(aD
)(sD
6d ],23[ 8p 9d],323[ 10p ...],45[ 86p 97d ...],50[ 8p)(# pD
...200
97d 45
97d 47
97d ],50[ 8p
:)(10 aD
:)(10 sD
:)(#10 pD
Node 10},...,{ 10091
10 ddD
2d 12 6d 17
9d 366d 18
9d 34 257)(1 aD
)(1 sD
6d ],23[ 8p 9d],323[ 10p ],45[ 86p)(#1 pD
Node 1},...,{ 101
1 ddD

Distributed Query Processing over D-inverted Index
17
Join ……
Aggregation
Local
Ranking
},...,{ 1011 ddD },...,{ 10091
10 ddD
Global
wv L Join wv L
SG
)(1 aD )(1 sD )(#1 pD
…
1,8p 1,86p 1,8p
2,8p 1,86p
results, scores
……
)(10 aD )(10 sD )(#10 pD
…
Node 1 Node 10

Entity-as-document: Entity-inverted Index
18
keyword pos entity id entity pos
6d ]17,,23[ 8p 9d ]34,,45[ 86p 97d ]45,,50[ 8p
phoneamazonaE #:)(
6d ]18,,23[ 8p 9d ]36,,45[ 86p 97d ]47,,50[ 8p
phoneservicesE #:)(

Entity Space Partitioning
19
6d ]17,,23[ 8p 9d ]34,,45[ 86p 97d ]45,,50[ 8p)(aE
6d ]18,,23[ 8p 9d ]36,,45[ 86p 97d ]47,,50[ 8p)(sE
...
Node 1
6d ]17,,23[ 8p 97d ]45,,50[ 8p)(1 aE
6d ]18,,23[ 8p 97d ]47,,50[ 8p)(1 sE
},...,{# 1011 ppP Node 9
},...,{# 90819 ppP
)(9 aE
)(9 sE
9d ]34,,45[ 86p
9d ]36,,45[ 86p
...

Distributed Query Processing over E-inverted Index
20
…
Local
RankingGlobal
S
)(1 aE )(1 sE
…
2,8p 1,86p
2,8p 1,86p
results, scores
…
)(9 aE )(9 sE
Node 1 Node 9
},...,{# 1011 ppP },...,{# 90819 ppP
Join
GAggregation
wv L Join
GAggregation
wv L…
…

21
Experiment Setup
Corpus: General crawl of the Web (Aug, 2007), around 3TB with 150M pages.
Entities: 24 diverse entity types
Concrete Applications (Benchmark queries): Yellowpage: #email, #phone, #state, #location, #zipcode CSAcademia: #university, #professor, #research, #email,
#phone

Metrics Used for Evaluation to Measure Throughput & Response Time
Local Processing Time Overall local processing time. Max local processing time
Transfer Time Overall transfer time Max transfer time
Global Processing Time
22

Local Processing Time Comparison
23

Network Transfer Comparison
24

Global Processing Time Comparison
25

Overall Time/Space Summary
26
Generally, ~2 to 4 orders of speedup,
with reasonable space overhead

Dual-Inversion Index
27
Dual-Inversion Index: The two types of indexes can co-exist, and
complement each other

Indexing Configuration
28
Entity Type Level Configuration: Create E-Inverted Index only for popular, space
efficient entities D-Inverted Index for less popular, space
expensive entities
Keyword Level Configuration: Only create E-Inverted Index for <keyword,
entity> pairs, when they are related, e.g., queried often from query log

Conclusion
Identify essential computation requirements for entity search
Dual-inversion indexing and partition schemes for efficient and scalable query processing Document-inverted index Entity-inverted index
Verify over large-scale corpus with real applications
29

30
Thanks much for coming!
Questions?

TopK Convergence
31

References of Related Work Index Design
Junghoo Cho and Sridhar Rajagopalan. A fast regular expression indexing engine. In ICDE, 2002.
Hugh E. Williams, Justin Zobel, and Dirk Bahle. Fast phrase querying with combined indexes. ACM Trans. Inf. Syst., 22(4):573–594, 2004.
Xiaohui Long and Torsten Suel. Three-level caching for efficient query processing in large web search engines. In WWW, 2005.
Michael Cafarella and Oren Etzioni. A search engine for large-corpus language applications. In WWW, 2005.
Question Answering S. Abney, M. Collins, and A. Singhal. Answer extraction. In ANLP, 2000. E. Brill, S. Dumais, and M. Banko. An analysis of the askmsr question-answering
system. In EMNLP, 2002. Cody C. T. Kwok, Oren Etzioni, and Daniel S. Weld. Scaling question answering
to the web. In WWW, 2001. Jimmy J. Lin and Boris Katz. Question answering from the web using knowledge
annotation and knowledge mining techniques. In CIKM, 2003.
32

Search Interface
33

Query I: Amazon Customer Service Phone
34
Results# of Supporting Page
Representative Supporting Pages

Query II: Professors in Data Mining
35

Query III: University of California Locations
36