1 advanced vlsi course class presentation an asynchronous array of simple processors for dsp...
TRANSCRIPT

1
Advanced VLSI Course Class Presentation
An Asynchronous Array of Simple Processors for DSP Applications
Rasoul Yousefi
Electrical and Computer Engineering DepartmentUniversity of Tehran

2
Copyright
• Slides used– Zhiyi Yu, Michael Meeuwsen, Ryan Apperson, Omar Sattari,
Michael Lai, Jeremy Webb, Eric Work, Tinoosh Mohsenin, Mandeep Singh, Bevan Baas “An Asynchronous Array of Simple rocessors for DSP Applications”, VLSI Computation Lab, ECE Department,University of California, Davis, USA,2006 IEEE
International Solid-State Circuits Conference

3
Outline
• The idea • Project objectives• Key features of the AsAP processor• Design of the AsAP processor• Results• Trends

4
The idea
• Using simple processor cores with small instruction and data memory to dramatically reduce area and power while increasing performance
FIFO 032
words ALUMAC
Control
IMem 64
words
DMem128
words
OSC
Staticconfig
Dynamicconfig
Output
FIFO 132
words
[1]

5
Outline
• The idea
• Project objectives• Key features of the AsAP processor• Design of the AsAP processor• Results• Trends
6
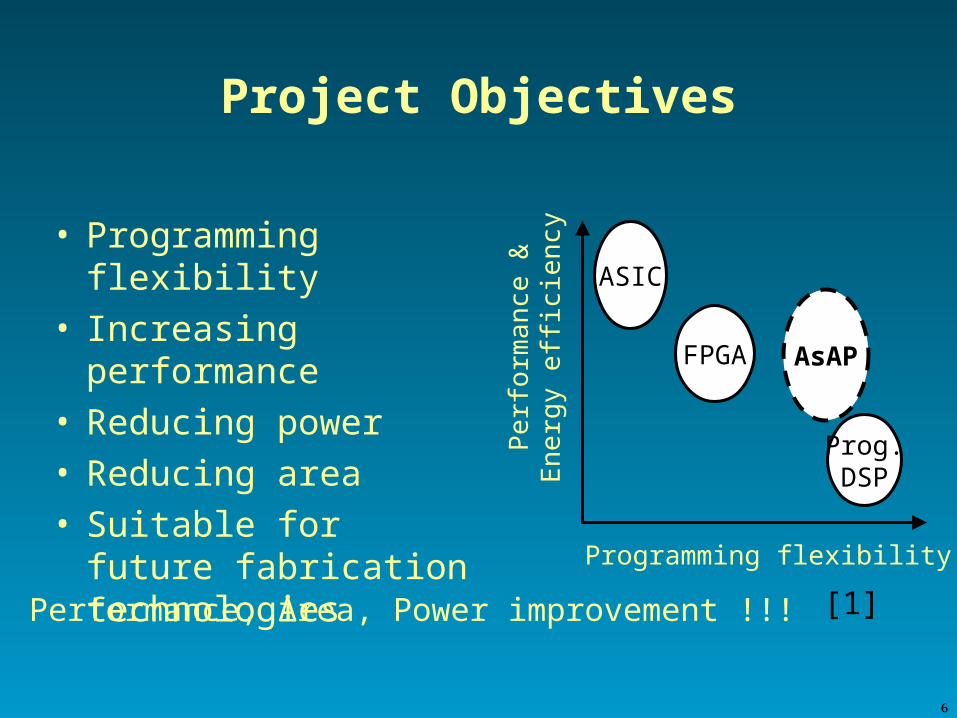
Project Objectives
• Programming flexibility• Increasing performance• Reducing power • Reducing area• Suitable for future
fabrication technologiesP
erf
orm
ance
&E
ner
gy
effi
cie
ncy
Programming flexibility
ASIC
FPGA
Prog.DSP
AsAP
Performance, Area, Power improvement !!! [1]

7
Outline
• The idea• Project objectives
• Key features of the AsAP processor• Design of the AsAP processor• Results• Trends

8
Key Features of the AsAP Processor
Chip multiprocessor High performance
Small memory& simple processor
High energy efficiencyGlobally asynchronous
locally synchronous (GALS)Technology scalability
Nearest neighbor communication

9
High Performance Through Chip Multiprocessor
• Increasing the clock frequency is challenging
• Parallelism is more promising– Instruction level parallelism (VLIW, Superscalar)– Data level parallelism (SIMD)– Task level parallelism
Higher clock frequency
Increased design complexity & lower energy efficiency
Deeper pipeline
10
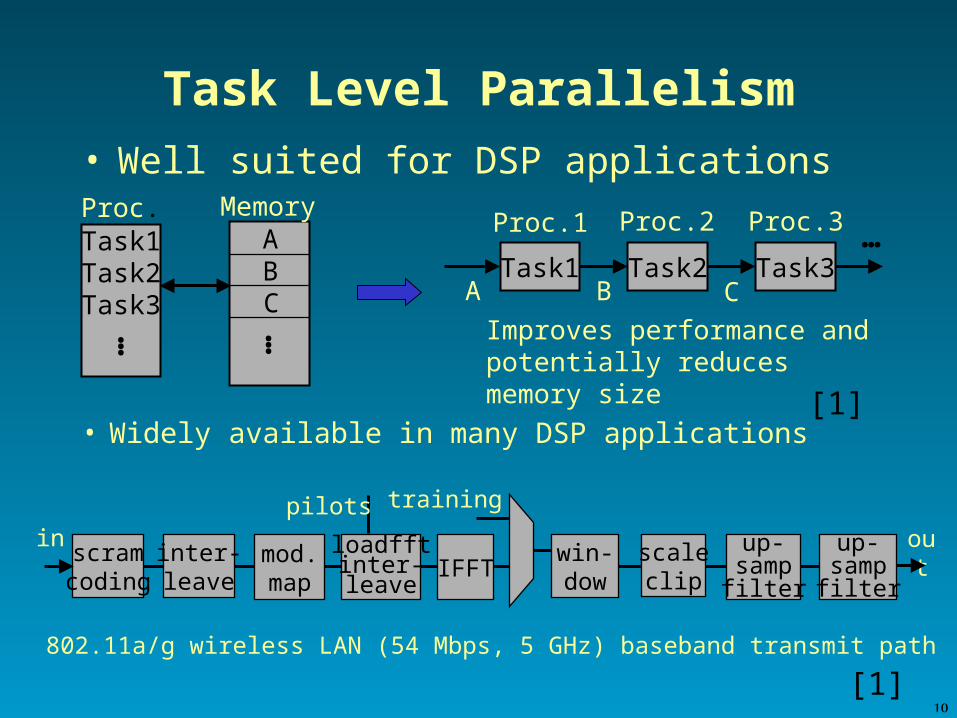
Task Level Parallelism• Well suited for DSP applications
scramcoding
inter-leave
mod.map
loadfftinter-leave
IFFTwin-dow
up-sampfilter
scaleclip
up-sampfilter
in out
trainingpilots
802.11a/g wireless LAN (54 Mbps, 5 GHz) baseband transmit path
Task1Task2Task3
ABC
Memory
Task1 Task2A B C
Proc. Proc.1 Proc.2
Task3
Proc.3
Improves performance andpotentially reduces memory size
…
• Widely available in many DSP applications
… …
[1]
[1]

11
Memory Size in Modern Processors• Memory occupies much of the area in modern processors
— this reduces area available for the core and consumes large amounts of power
• Memories frequently contain the critical path • Area and energy dissipation can be dramatically decreased
while speed can be increased with smaller memories
0%
20%
40%
60%
80%
100%
Are
a b
reak
do
wn other
mem
core
TI_C64x Itanium SPARC BlGe/L [ISSCC 02, 05] [from1]

12
Can we use small memory ?

13
Small Memory Requirements for DSP Tasks
• The memory required for common DSP tasks is quite small
• Several hundred words of memory are sufficient for many DSP tasks
Task IMem
(words)
DMem
(words)
N-pt FIR 6 2N
8-pt DCT 40
16
8x8 2-D DCT 154 72
Conv. coding (k = 7)
29 14
Huffman encode 200 330
N-pt convolution 29 2N
64-pt complex FFT 97 192
Bubble sort 20 1
N merge sort 50 N
Square root 62 15
Exponential 108 32
[1]

14
• A system with many processors can use individual processors or groups of processors to compute individual tasks and intermediate data can be transmitted between processors with a small memory requirement
• So it is possible to use small memory

15
GALS Clocking Style
• The challenge of globally synchronous systems– Design difficulty when using high clock frequencies,
long clock wires caused by large chip sizes, and large circuit parameter variations
– High clock power consumption and lack of flexibility to independently control clock frequencies
• How about totally asynchronous design style– Lack of EDA tool support– Design complexity and circuit overhead
• The GALS compromise– Synchronous blocks each operating in their own
independent clock domain

16
The GALS architecture basics
• Power breakdown in a high-performance CPU[2]
Datapath Memory
ControlI/O
Clock
[Adopted from 2]

17
The GALS architecture basics
• Eliminating global clock Eliminating a major source of power consumption[2]
• Frequency of each SB can be tailored to the local needs Reducing average frequency and overall power consumption[2]
SB1 SB2
SB3DataHandshake protocol [Adopted from 2]

18
On Chip Communication
• Methods to avoid global wires– Network on chip (NOC)– Local communication– Nearest neighbor communication
nearest local
[1]

19
Outline
• The idea• Project objectives• Key features of the AsAP processor
• Design of the AsAP processor• Results• Trends

20
AsAP Block Diagram• GALS array of identical processors
– Each processor is a reduced complexity programmable DSP with small memories
– Each processor can receive data from any two neighbors and send data to any of its four neighbors
FIFO 032
words ALUMAC
Control
IMem 64
words
DMem128
words
OSC
Staticconfig
Dynamicconfig
Output
FIFO 132
words
[1]

21
IFetch
PC
Inst.Mem
Decode Mem.Read
SrcSelect
EXE 1 EXE 2 EXE 3 ResultSelect
WriteBack
FIFO 0 RD
FIFO 1 RD
DataMemRead
DCMemRead
De-code
Addr.Gens.
ALU DataMemWrite
DCMemWrite
Proc Output
Single Processor Architecture• 54 32-bit instructions• 9-stage pipeline
Bypass
Multiply Accumulator
×ACC
+
[1]

22
resethalt
clk
Programmable Clock Oscillator
• Standard cell based• Configurable frequency
– Delay tunable stages using 7 parallel tri-state inverters
– 1 to 128 clock divider• Results
– 1.66 MHz – 702 MHz– Max gap: 0.08 MHz
(1.66 – 500 MHz)
… … … …
…
…
… …
stage_sel
..
...
...
...
.
Clock divider
[1]

23
Write side Read sideeast
westsouth Write
logic
FIFO 0
Readlogic
east
north
west
south
CPU
FIFO 1
Processor
east
northwest
south
Inter-processor Communication
• Each processor contains two dual-clock FIFOs
• Rd/Wr in separate clock domains
north
Binary Gray & Sync.
addr addr
SRAM
[1]

24
Advantages of theAsAP Clocking System
• Simplified clock tree design – The maximum span is < 1 mm in 0.18 µm
• Scalable – easy to add processors• Improved energy efficiency
– Clock halts in 9 cycles (processor dissipates leakage power only) and restores in < 1 cycle according to work availability
– 53% and 65% power saving– Independent clock and voltage scaling (individual
processor voltage scaling not implemented in this version)

25
Physical Design
• 0.18 µm TSMC• Standard cell• Design flow
– Completely synthesized, except oscillator– Macro memory blocks used for four main memories– Completely auto placed and routed
• To simplify physical design, clock gating not implemented in this version

26
Transistors:
1 Proc 230,000
Chip 8.5 million
Max speed: 475 MHz @ 1.8 V
Area: 1 Proc 0.66 mm²
Chip 32.1 mm²
Power (1 Proc @ 1.8V, 475 MHz):
Typical application 32 mW
Typical 100% active 84 mW
Worst case 144 mW
Power (1 Proc @ 0.9V, 116 MHz):
Typical application 2.4 mW
SingleProcessor
OSC FIFOs
DMemIMem
810 µm5.65 mm
810 µm
5.68 mm
Chip Micrograph of the 6 x 6 Array
[1]

27
Outline
• The idea• Project objectives• Key features of the AsAP processor• Design of the AsAP processor
• Results• Trends

28
Area Evaluation
• Most of AsAP’s area is for the core (66%)• Each processor requires a very small area; more
than 20x smaller than others
0%
20%
40%
60%
80%
100%
Are
a b
reak
do
wn
comm mem core
Pro
cess
or
area
(m
m²)
20x
All scaled to 0.13 µm[ISSCC 05, 00; ISCA04; CMPON96]
0.1
1
10
100 7230
8.3 7
0.34
29
TI RAW Fujitsu BlGe/ AsAP C64x 4-VLIW L
TI CELL/ Fujitsu RAW ARM AsAP C64x SPE 4-VLIW
[1] [1]

29
Power and Performance
0.01
0.1
1
10 100 1000 10000
AsAP
CELL/SPE
Fujitsu-4VLIW
ARM
RAW
TI C64x
Po
wer
/ C
lock
fre
qu
ency
/ S
cale
*
(mW
/MH
z)
Peak performance density (MOPS/mm²)
All scaled to 0.13 µm
* Assume 2 ops/cycle for CELL/SPE and 3.3 ops/cycle for TI C64x
Note: word widths and workload not factored
[ISSCC 05, 00; ISCA04; CMPON96]
Higher performance
÷ area, and
Lower estimated
energy
[1]
30
Pad
Scram
Conv. Code
PuncInter-
leave 1
Inter-leave 2
Mod.Map
PilotInsert
Train
IFFT BR
IFFT Mem
IFFT BF
IFFTOutput
GI/Wind.
GI/Wind.
IFFT Mem
IFFT BF
FIRFIR
IFFT BF
IFFT Mem
OutputSync
IFFT
Data bits
ToD/A
converter
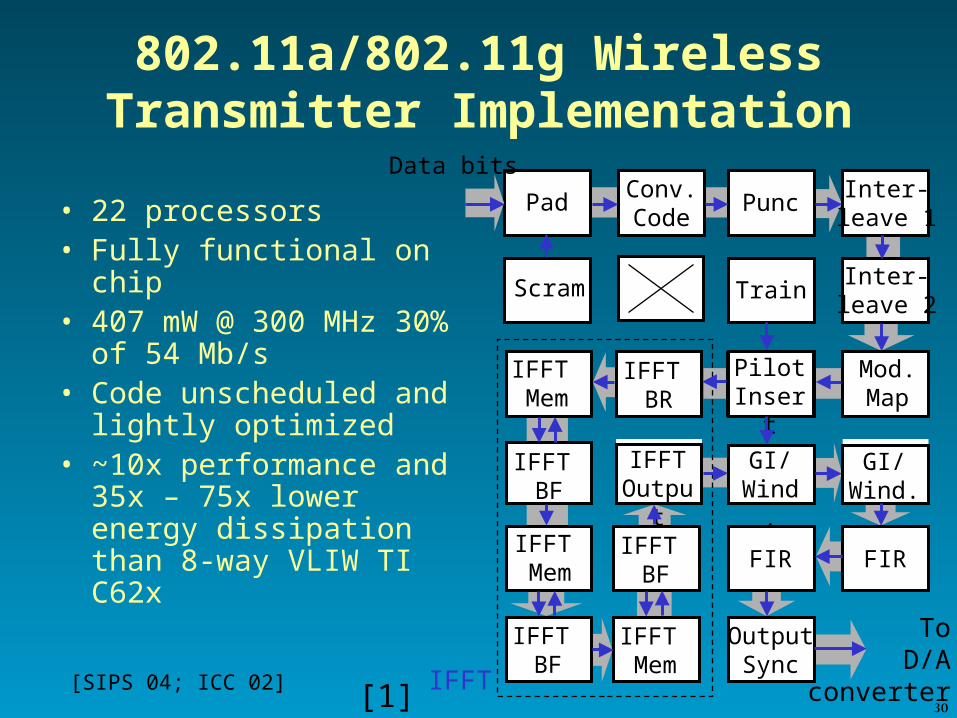
802.11a/802.11g Wireless Transmitter Implementation
• 22 processors• Fully functional on chip• 407 mW @ 300 MHz
30% of 54 Mb/s• Code unscheduled and
lightly optimized• ~10x performance and
35x – 75x lower energy dissipation than 8-way VLIW TI C62x
[SIPS 04; ICC 02] [1]

31
Summary
• Scalable programmable processing array– Many processors on a single chip– Reduced complexity processors with small memories– GALS clocking style– Nearest neighbor communication
• Results– 0.18 µm, 475 MHz @ 1.8 V
• 32 mW application power• 84 mW 100% active power• 2.4 mW application power @ 116 MHz and 0.9 V
– High performance density: 475 MOPS in 0.66 mm²– Well suited for future fabrication technologies

32
Trends
• Clock Gating
• Dynamic voltage scaling but adds level-conversion for asynchronous communication interface[3]
• CAD tool – CAD tools for asynchronous design is mature,
but not commercially strong yet.[3]

33
References1.Zhiyi Yu, Michael Meeuwsen, Ryan Apperson, Omar Sattari, Michael Lai, Jeremy Webb, Eric Work, Tinoosh Mohsenin,
Mandeep Singh, Bevan Baas, “An Asynchronous Array of
Simple rocessors for DSP Applications”, VLSI Computation Lab, ECE Department,University of California, Davis, USA,2006 IEEE International Solid-State Circuits Conference
2.A.Hemani , T.Meincke , S.Kumar, A.Postula, T.olsson, P.Nilsson,
J.Oberg , P.Ellervee,D.Lundqvist, “Lowering power consumption in clock by using Globally Asynchronous Locally Synchronous design style”
3.Anoop Iyer ,Diana Marculescu, “Power and Performance Evaluation of Globally Asynchronous Locally Synchronous Processors”, Proceedings of the 29th Annual International Symposium on Computer Architecture (ISCA.02)

34
Question?
Thanks for your attention