© hortonworks inc. 2013 stinger initiative: deep dive interactive query on hadoop page 1 chris...
TRANSCRIPT

© Hortonworks Inc. 2013
Stinger Initiative: Deep DiveInteractive Query on Hadoop
Page 1
Chris Harris
E-Mail : [email protected]
Twitter : cj_harris5

© Hortonworks Inc. 2013
Agenda
• Key Hive Use Cases• Brief Refresher on Hive• The Stinger Initiative: Interactive Query for Hive
Page 2

© Hortonworks Inc. 2013
Key Hive Use Cases
• RDBMS / MPP Offload–More data under query.–Database unable to keep up with SLAs.
• Analysis of semi-structured data.• ETL / Data Refinement
• +++ Increasingly: Business Intelligence and interactive query
Page 3

© Hortonworks Inc. 2013
BI Use Cases
Page 4
Enterprise Reports Dashboard / Scorecard Parameterized Reports
Visualization Data Mining

© Hortonworks Inc. 2013
Organize Tiers and Process with Metadata
Page 5
Work Tier
Standardize, Cleanse, Transform MapReducePig
Raw Tier
Extract & LoadWebHDFS
FlumeSqoop
GoldTier
Transform, Integrate, StorageMapReduce
Pig
Conform, Summarize, AccessHiveQL
Pig
Access Tier
HCat
Provides unified metadata
access to Pig, Hive &
MapReduce
• Organize data based on source/derived relationships
• Allows for fault and rebuild process

© Hortonworks Inc. 2013
Hive Current Focus Area
Page 6
• Online systems• R-T analytics• CEP
Real-Time Interactive Batch
• Parameterized Reports
• Drilldown• Visualization• Exploration
• Operational batch processing
• Enterprise Reports
• Data Mining
Data Size
0-5s 5s – 1m 1m – 1h 1h+
Non-Interactive
• Data preparation• Incremental batch
processing• Dashboards /
Scorecards
Current Hive Sweet Spot

© Hortonworks Inc. 2013
Stinger: Extending Hive’s Sweetspot
Page 7
• Online systems• R-T analytics• CEP
Real-Time Interactive Batch
• Parameterized Reports
• Drilldown• Visualization• Exploration
• Operational batch processing
• Enterprise Reports
• Data Mining
Data Size
0-5s 5s – 1m 1m – 1h 1h+
Non-Interactive
• Data preparation• Incremental batch
processing• Dashboards /
Scorecards
Improve Latency & Throughput• Query engine improvements• New “Optimized RCFile” column store• Next-gen runtime (elim’s M/R latency)
Extend Deep Analytical Ability• Analytics functions• Improved SQL coverage• Continued focus on core Hive use cases
Current Hive Sweet SpotFuture HiveExpansion

© Hortonworks Inc. 2013
The top BI vendors support Hive today
Page 8

© Hortonworks Inc. 2013
Agenda
• Key Hive Use Cases• Brief Refresher on Hive• The Stinger Initiative: Interactive Query for Hive
Page 9

© Hortonworks Inc. 2013
Brief Refresher on HiveThe State of Hive Today (0.10)
Page 10

© Hortonworks Inc. 2013
Hive’s Origins
Page 11
Hive was originally developed at Facebook.More data than existing RDBMS could handle.60,000+ Hive queries per day.More than 1,000 users per day.100+ PB of data.15+ TB of data loaded daily.Hive is a proven solution at extreme scale.

© Hortonworks Inc. 2013
Hive 0.10 Capabilities
• De-facto SQL Interface for Hadoop• Multiple persistence options:
–Flat text for simple data imports.–Columnar format (RCFile) for high performance processing.
• Secure and concurrent remote access• ODBC/JDBC connectivity• Highly extensible:
–Supports User Defined Functions and User Defined Aggregation Functions.
–Ships with more than 150 UDF/UDAF.–Extensible readers/writers can process any persisted data.
• Support from 10+ BI vendors
Page 12

© Hortonworks Inc. 2013
HDP 1.2: ODBC Access for Popular BI Tools
Page 13
• Seamless integration with BI tools such as Excel, PowerPivot, MicroStrategy, and Tableau
• Efficiently maps advanced SQL functionality into HiveQL– With configurable pass-through of
HiveQL for Hive-aware apps
• ODBC 3.52 standard compliant• Supports Linux & Windows
High quality ODBC driver developed in partnership with Simba.Free to download & use with Hortonworks Data Platform.
Applications &Spreadsheets
Visualization & Intelligence
ODBC
HortonworksData Platform

© Hortonworks Inc. 2013
0 to Big Data in 15 Minutes
Page 14
Hands on tutorials integrated into
Sandbox
HDP environment for evaluation

© Hortonworks Inc. 2013
Agenda
• Brief Refresher on Hive• Key Hive Use Cases• The Stinger Initiative: Interactive Query for Hive
Page 15

© Hortonworks Inc. 2013
The Stinger InitiativeInteractive Query on Hadoop
Page 16

© Hortonworks Inc. 2013
Stinger Initiative: 2-Pronged Approach
Page 17
Tez• New primitives move beyond map-reduce
and beyond batch• Avoid unnecessary persistence of
temporary data• Hive, Pig and others generate Tez plans
for high perf
Query Engine Improvements• Cost-based optimizer• In-memory joins• Caching hot tables• Vector processing
State-of-the-art Column Store• “Optimized RCFile” or ORCFile• Minimizes disk IO and deserialization
Tez Service• Always-on service for query interactivity
Improve Latency and Throughput
Analytics Functions• SQL:2003 Compliant• OVER with PARTITION BY and ORDER
BY• Wide variety of windowing functions:
• RANK• LEAD/LAG• ROW_NUMBER• FIRST_VALUE• LAST_VALUE• Many more
• Aligns well with BI ecosystem
Improved SQL Coverage• Non-correlated Subqueries using IN in
WHERE• Expanded SQL types including
DATETIME, VARCHAR, etc.
Extend Deep Analytical Ability
Making Hive Best for Interactive Query

© Hortonworks Inc. 2013
Hive: Performance Improvements
Page 18

© Hortonworks Inc. 2013
Stinger Initiative At A Glance
Page 19

© Hortonworks Inc. 2013
Base Optimizations: Intelligent Optimizer
• Introduction of In-Memory Hash Join:–For joins where one side fits in memory:–New in-memory-hash-join algorithm.–Hive reads the small table into a hash table.–Scans through the big file to produce the output.
• Introduction of Sort-Merge-Bucket Join:–Applies when tables are bucketed on the same key.–Dramatic speed improvements seen in benchmarks.
• Other Improvements:–Lower the footprint of the fact tables in memory.–Enable the optimizer to automatically pick map joins.
Page 20

© Hortonworks Inc. 2013
Dimensionally Structured Data
• Extremely common pattern in EDW.• Results in large “fact tables” and small “dimension tables”.
• Dimension tables often small enough to fit in RAM.• Sometimes called Star Schema.
Page 21

© Hortonworks Inc. 2013
A Query on Dimensional Data
• Derived from TPC-DS Query 27
• Dramatic speedup on Hive 0.11
Page 22
SELECT col5, avg(col6)FROM fact_table
join dim1 on (fact_table.col1 = dim1.col1) join dim2 on (fact_table.col2 = dim2.col1) join dim3 on (fact_table.col3 = dim3.col1) join dim4 on (fact_table.col4 = dim4.col1)
GROUP BY col5 ORDER BY col5LIMIT 100;

© Hortonworks Inc. 2013
Star Schema Join Improvements in 0.11
Page 23

© Hortonworks Inc. 2013
Hive: Bucketing
• Bucketing causes Hive to physically co-locate rows within files.
• Buckets can be sorted or unsorted.
Page 24
CREATE EXTERNAL TABLE IF NOT EXISTS test_table( Id INT, name String)PARTITIONED BY (dt STRING, hour STRING)CLUSTERED BY(country,continent) SORTED BY(country,continent) INTO n BUCKETSROW FORMAT DELIMITED FIELDS TERMINATED BY '|'LOCATION '/home/test_dir';

© Hortonworks Inc. 2013
ORCFile - Optimized Column Storage
• Make a better columnar storage file–Tightly aligned to Hive data model
• Decompose complex row types into primitive fields–Better compression and projection
• Only read bytes from HDFS for the required columns.• Store column level aggregates in the files
–Only need to read the file meta information for common queries–Stored both for file and each section of a file–Aggregates: min, max, sum, average, count–Allows fast access by sorted columns
• Ability to add bloom filters for columns–Enables quick checks for whether a value is present
Page 25

© Hortonworks Inc. 2013
Performance Futures - Vectorization
• Operates on blocks of 1K or more records, rather than one record at a time
• Each block contains an array of Java scalars, one for each column
• Avoids many function calls, virtual dispatch, CPU pipeline stalls
• Size to fit in L1 cache, avoid cache misses• Generate code for operators on the fly to avoid branches in code, maximize deep pipelines of modern processers
• Up to 30x faster processing of records• Beta possible in 2H 2013
Page 26

© Hortonworks Inc. 2013
Performance Futures – Cost-Based Optimizer
• Generate more intelligent DAGs based on properties of data being queried, e.g. table size, statistics, histograms, etc.
Page 27

© Hortonworks Inc. 2013
Performance Futures - Buffering
• Query workloads always have hotspots:–Metadata–Small dimension tables
• Build into YARN or Tez Service ways of buffering frequently used data into memory so it is not always read from disk.
• Part of the “last mile” of latency efforts.
Page 28

© Hortonworks Inc. 2013
YarnMoving Hive and Hadoop beyond MapReduce
Page 29

© Hortonworks Inc. 2013
Hadoop 2.0 Innovations - YARN
• Focus on scale and innovation– Support 10,000+ computer clusters– Extensible to encourage innovation
• Next generation execution– Improves MapReduce performance
• Supports new frameworks beyond MapReduce– Low latency, Streaming, Services– Do more with a single Hadoop cluster
HDFS
Map
Redu
ce
Redundant, Reliable Storage
YARN: Cluster Resource Management
Tez
Gra
ph P
roce
ssin
g
Oth
er

© Hortonworks Inc. 2013
TezMoving Hive and Hadoop beyond MapReduce
Page 31

© Hortonworks Inc. 2013
Tez
• Low level data-processing execution engine• Use it for the base of MapReduce, Hive, Pig, Cascading etc.
• Enables pipelining of jobs• Removes task and job launch times• Hive and Pig jobs no longer need to move to the end of the queue between steps in the pipeline
• Does not write intermediate output to HDFS–Much lighter disk and network usage
• Built on YARN
Page 32

© Hortonworks Inc. 2013
Tez - Core Idea
Task with pluggable Input, Processor & Output
Page 33
YARN ApplicationMaster to run DAG of Tez Tasks
Input Processor
Task
Output
Tez Task - <Input, Processor, Output>
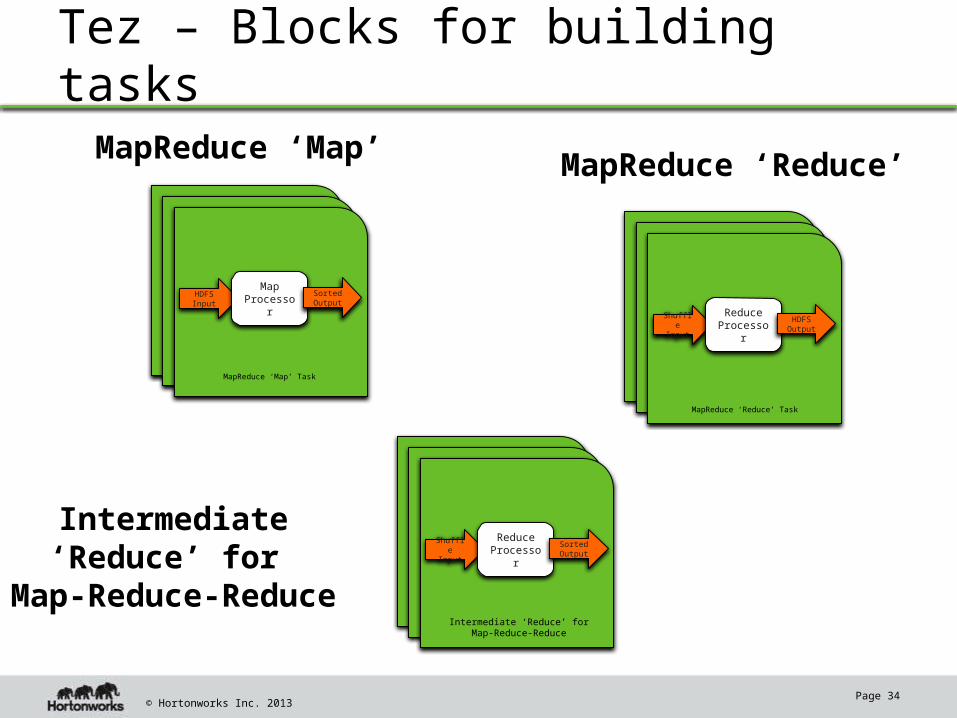
© Hortonworks Inc. 2013
Tez – Blocks for building tasks
MapReduce ‘Map’
Page 34
MapReduce ‘Reduce’
HDFS Input
Map Processor
MapReduce ‘Map’ Task
Sorted Output
Shuffle Input
Reduce Processor
HDFS Output
Intermediate ‘Reduce’ for
Map-Reduce-Reduce
Shuffle Input
Reduce Processor
Intermediate ‘Reduce’ for Map-Reduce-Reduce
Sorted Output
MapReduce ‘Reduce’ Task

© Hortonworks Inc. 2013
Tez – More tasks
Special Pig/Hive ‘Map’
Page 35
In-memory Map
HDFS Input
Map Processor
Tez Task
Pipeline Sorter Output
HDFSInput
Map Processor
Tez Task
In-memory Sorted Output
Special Pig/Hive ‘Reduce’
Shuffle Skip-
merge Input
Reduce Processor
Tez Task
Sorted Output

© Hortonworks Inc. 2013
Pig/Hive-MR versus Pig/Hive-Tez
Page 36
SELECT a.state, COUNT(*), AVERAGE(c.price)
FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemId = c.itemId)
GROUP BY a.state
Pig/Hive - MR Pig/Hive - Tez
I/O Synchronization
Barrier
I/O Synchronization
Barrier
Job 1
Job 2
Job 3
Single Job

© Hortonworks Inc. 2013
FastQuery: Beyond Batch with YARN
Page 37
Tez Generalizes Map-Reduce
Simplified execution plans processdata more efficiently
Always-On Tez Service
Low latency processing forall Hadoop data processing

© Hortonworks Inc. 2013
Tez Service
• MR Query Startup Expensive– Job launch & task-launch latencies are fatal for short queries (in
order of 5s to 30s)
• Solution–Tez Service
– Removes task-launch overhead– Removes job-launch overhead
–Hive/Pig– Submit query-plan to Tez Service
–Native Hadoop service, not ad-hoc
Page 38

© Hortonworks Inc. 2013
Tez Service Delivers Low Latency
Page 39
SELECT a.state, COUNT(*), AVERAGE(c.price)
FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemId = c.itemId)
GROUP BY a.state
Existing Hive
Parse Query 0.5s
Create Plan 0.5s
Launch Map-Reduce 20s
Process Map-Reduce
10s
Total 31s
Hive/Tez
Parse Query 0.5s
Create Plan 0.5s
Launch Map-Reduce 20s
Process Map-Reduce
2s
Total 23s
Tez and Tez Service
Parse Query 0.5s
Create Plan 0.5s
Submit to Tez Service 0.5s
Process Map-Reduce 2s
Total 3.5s
* Numbers for illustration only

© Hortonworks Inc. 2013
Recap and Questions: Hive Performance
Page 40

© Hortonworks Inc. 2013
Improving Hive’s SQL Support
Page 41

© Hortonworks Inc. 2013
Stinger: Deep Analytical Capabilities
• SQL:2003 Window Functions–OVER clauses
– Multiple PARTITION BY and ORDER BY supported– Windowing supported (ROWS PRECEDING/FOLLOWING)– Large variety of aggregates
– RANK– FIRST_VALUE– LAST_VALUE– LEAD / LAG– Distrubutions
Page 42

© Hortonworks Inc. 2013
Hive Data Type Conformance
• Data Types:–Add fixed point NUMERIC and DECIMAL type (in progress)–Add VARCHAR and CHAR types with limited field size–Add DATETIME–Add size ranges from 1 to 53 for FLOAT–Add synonyms for compatibility
– BLOB for BINARY– TEXT for STRING– REAL for FLOAT
• SQL Semantics:–Sub-queries in IN, NOT IN, HAVING.–EXISTS and NOT EXISTS
Page 43

© Hortonworks Inc. 2013
Questions?
Page 44

© Hortonworks Inc. 2013
Thank You!Questions & Answers
Page 45